An earlier article described some of the technical and business highlights from the recent TSMC Symposium in Santa Clara (link). This article continues that discussion, with the top five updates.
Continue reading “Top 10 Updates from the TSMC Technology Symposium, Part II”
Top 10 Updates from the TSMC Technology Symposium, Part I
Last week, TSMC held their 23rd annual technical symposium in Santa Clara. In the Fall, TSMC conducts the OIP updates from EDA/IP partners and customers. The theme of the Spring symposium is solely on TSMC’s technology development status and the future roadmap. Indirectly, the presentations also provide insight into the electronics industry as a whole, based upon the market segments where TSMC is focusing, with their R&D investments.
Continue reading “Top 10 Updates from the TSMC Technology Symposium, Part I”
TSMC Talks About 22nm, 12nm, and 7nm EUV!
The TSMC Symposium was jam-packed this year with both people and information. I had another 60 minutes of fame in the Solido booth where I signed 100 books, thank you to all who stopped by for a free book and a SemiWiki pen. SemiWiki bloggers Tom Dillinger and Tom Simon were also there so look for more TSMC Symposium blogs coming in the next few days. If you have specific questions ask them here and I will make sure you get answers.
Rick Cassidy, President, TSMC North America again kicked of the conference with a nice overview of the semiconductor business. In fact, TSMC shipped 5.8M (12” equiv) wafers in 2016 to more than 450 customers with 5,238 products. Approximately 71% of the resulting revenue went through Rick and the TSMC North American organization so congratulations to them on a job well done.
One of the reoccurring points made by Rick and the other TSMC executives is that TSMC does not compete with their customers which is the foundation of the pure-play foundry business and the key to the success of the fabless semiconductor industry, absolutely.
This year TSMC really focused on custom process platforms for key market segments of the semiconductor industry. I went into a bit more detail on this in my pre-symposium blog TSMC Design Platforms Driving Next-Gen Applications. That blog went viral with more than 10,000 views in one week so you may want to check it out.
There were three big announcements yesterday in my opinion:
1. 22nm ULP
2. 12nm FFC
3. 7nm EUV
Most of us had advanced knowledge of this but it was nice to hear more details in front of more than 1,000 TSMC customers. Again, this is an invitation only event with no recording or photography allowed so much more information is made available than open events or conferences.
TSMC formally introduced 22nm ULP (an optimized version of 28nm HPC+) and 12nm FFC (an optimized version of 16nm). 22nm ULP offers a 10% area reduction and either a 15% performance gain over 28nm or a 35% power reduction. TSMC also has 55nm ULP, 40nm ULP, and 28nm ULP all targeted at IoT and other low power and low cost applications. 12nm FFC offers a 10% performance gain or a 25% power reduction. 12nm also offers a 20% area reduction with 6T Libraries versus 7.5T or 9T.
TSMC 10nm is now fully qualified and in HVM at Giga Fabs 12 and 15. TSMC is scheduled to ship 400,000 wafers in 2017 so you can expect the next Apple iProducts to sport TSMC 10nm SoCs, definitely.
Other than that, 10nm was not discussed much because it is another short node like 20nm. Remember, TSMC introduced double patterning at 20nm then quickly followed with FinFETs at 16nm. This proved to be very a wise approach since the same fabs were used for both 20nm and 16nm which simplified the 16nm ramp. We will see the same with 10nm and 7nm. TSMC ramped 10nm without quad patterning and will add it with 7nm, again using the same fabs.
7nm was the focus of the technical discussions of course because it represents several firsts for our industry. 7nm will also represent the biggest market share for TSMC for one node, second being 28nm I believe. It would be easier to count the big semiconductor companies that are NOT using TSMC 7nm and the only two I can think of are Samsung and Intel.
In comparison to 16FF+, TSMC 7nm is said to offer a 3.3x density, 30% speed, and a 60% power improvement. TSMC will again offer multiple versions of 7nm for platform specific applications (Mobile, IoT, AI, and Automotive). The 7nm SRAM bit cell is .37x compared to 16nm which I believe will be the smallest SRAM bit cell in production so congratulations to the SRAM team in Hsinchu. 7nm will hit risk production in April and HVM in the first half of 2018, and yes, next year’s iProducts will sport TSMC 7nm SoCs.
The big shocker to me was that TSMC is still committed to introducing EUV at 7nm in 2019. Based on what I saw at the SPIE conference last month EUV would miss 7nm completely. This will be another first for the industry (EUV in production) so I can see the incentive but I highly doubt the ROI will be there at 7nm.
TSMC also stated that 5nm development is progressing according to plan with good SRAM yield. TSMC is still scheduling 5nm for 2020 but they did not say at what level EUV would be used. Probably because it depends on the EUV success at 7nm.
Also read: Top 10 Updates from the TSMC Technology Symposium, Part I
TSMC Design Platforms Driving Next-Gen Applications
Coming up is the 23rd annual TSMC Technology Symposium where you can get first-hand updates on advanced and specialty technologies, advanced backend capabilities, future development plans, and network with hundreds of TSMC’s customers and partners. This year the Silicon Valley event kicks off at the Santa Clara Convention Center. For more information the Symposium landing page is HERE but first lets talk about design platforms.
The semiconductor design ecosystem, semiconductor companies, and TSMC are uniting around new methods to overcome chip design challenges by integrating the right tools and technologies into customized, powerful design platforms.
It is becoming apparent that the next growth driver for the IC industry is “ubiquitous computing” where data is generated, collected, filtered, processed and analyzed not just in the cloud or network, but also locally in smart devices all around us. To help its customers seize these opportunities, TSMC and its Open Innovation Platform® partners have developed four application-specific platforms for the next generation of high-growth applications: Mobile, High-Performance Computing (HPC), Automotive, and Internet of Things.
Smartphones occupied much of the last decade’s engineering resources and continue to grow at a healthy clip – Gartner reports 1.5 billion units sold in 2016 – pushing advanced semiconductor technology and design to new heights. However, it is now clear that mobile was just the beginning of a new silicon revolution as industry focus rapidly shifts to the optimization of advanced technology for automotive, HPC and IoT.
In mobile, growth in silicon content per device is driven by features such as dual camera, fingerprint sensors, AR/VR and migration to 4G, 4G+ and 5G. For HPC, artificial intelligence and deep learning will have significant impacts on many industries including healthcare, media and consumer electronics. On the automotive front, ADAS, night-vision, and smart energy for hybrid and electric vehicles promise to make driving more convenient, safe and green. Finally, IoT opens up a multitude of opportunities for ICs that will transform the way we live and improve how societies can be organized and managed through improved efficiency and pervasive communication.
Dr. Cliff Hou, TSMC Vice President of Research & Development, Design and Technology Platform, has pioneered the evolution of design ecosystems to design platforms and the application-specific design enablement that addresses distinct product requirements of each of these four segments. Dr. Hou asserts that application-specific design platforms deliver greatly enhanced solutions that simplify highly complex design activity, reducing the time and effort needed to bring products to market for these high-growth opportunities.
Each TSMC process and packaging optimized design platform includes reference subsystem designs to facilitate innovation; processor cores (CPU, GPU); standard interfaces, Analog/Mixed Signal IP; foundation IP that includes standard cells, SRAM and I/O; design flow, design guideline and EDA tools; and PDK and Tech Files. The goals and readiness of each platform is summarized below:
If you were lucky enough to get a golden ticket to this event it would be a pleasure to meet you. SemiWiki bloggers Tom Dillinger, Tom Simon, and myself will be there blogging live and I will be giving away signed copies of our book on The History of ARM “Mobile Unleashed” in the Solido booth during the lunch break. If you would like to do a meet and greet and get a free book stop on by and say hello.
About TSMC
TSMC created the semiconductor Dedicated IC Foundry business model when it was founded in 1987. TSMC served about 470 customers and manufactured more than 8,900 products for various applications covering a variety of computer, communications and consumer electronics market segments. Total capacity of the manufacturing facilities managed by TSMC, including subsidiaries and joint ventures, reached above 9 million 12-inch equivalent wafers in 2015. TSMC operates three advanced 12-inch wafer GIGAFAB™ facilities (fab 12, 14 and 15), four eight-inch wafer fabs (fab 3, 5, 6, and 8), one six-inch wafer fab (fab 2) and two backend fabs (advanced backend fab 1 and 2). TSMC also manages two eight-inch fabs at wholly owned subsidiaries: WaferTech in the United States and TSMC China Company Limited, In addition, TSMC obtains 8-inch wafer capacity from other companies in which the Company has an equity interest.
TSMC’s 2015 total sales revenue reached a new high at US$26.61 billion. TSMC is headquartered in the Hsinchu Science Park, Taiwan, and has account management and engineering service offices in China, Europe, India, Japan, North America, and, South Korea.
EUV is NOT Ready for 7nm!
The annual SPIE Advanced Lithography Conference kicked off last night with vendor sponsored networking events and such. SPIE is the international society for optics and photonics but this year SPIE Advanced Lithography is all about the highly anticipated EUV technology. Scotten Jones and I are at SPIE so expect more detailed blogs on the keynotes and sessions this week.
Attend SPIE Advanced Lithography
Come to the world’s premier lithography event. For over 40 years, SPIE has brought together industry leaders to solve the latest challenges in lithography and patterning in the semiconductor industry. Check out the 2017 News & Photo page andStay on top of what is happening before, during, and after the 2017 SPIE Advanced Lithography meeting in San Jose.
The many BILLION dollar question of course is: When will EUV be ready for high volume manufacturing?
According to Intel EUV Manager Dr. Britt Turkot, at this point in time, EUV is not ready for HVM and may not be ready for 7nm. Britt has been with Intel for 20+ years and is a regular presenter at SPIE. In fact, Britt did a similar presentation last year which was nicely summarized by Scotten Jones: TSMC and Intel on the Long Road to EUV, by Scotten Jones, Published on 02-23-2016 05:00 AM. You can get a full list of Scotten’s blogs HERE.
If you look point-for-point, according to Britt, not much has changed. As Scotten pointed out, three years ago the key issues were: Photoresist – line width roughness (LWR) and outgassin, Tools – source power and availability, and Reticle – killer defects and pellicles.
Photoresist technology continues to improve but no breakthroughs have been reported.
The current power roadmap is to have 250 watts in the 2016-2017 timeframe, >250 watts in the 2018-2019 timeframe. From what I have heard thus far, power in the field is closer to 100 watts than 200 so we still have a ways to go before HVM.
One of the most interesting points was particles and pellicles. According to Britt, particles are a much bigger problem than ASML has disclosed so pellicles will be required. I’m sure we will hear more about this during the conference but pellicles are a double edge sword. They do reduce the number of wafer defects caused by particles but they also draw source power which is already a key issue for throughput and machine availability.
EUV photomask inspection was also discussed. Intel has been pushing for an actinic based inspection tool and that push continues. The question of course is: Who is going to pay for it? My guess is that, as with most semiconductor manufacturing roadblocks, there will be an inspection workaround to get EUV into production before R&D dollars are spent on actinic.
As we already know TSMC has skipped EUV for 7nm but is planning on exercising EUV at 7nm in preparation for EUV at 5nm. At last year’s SPIE, Intel, Samsung, and GLOBALFOUNDRIES still had EUV planned for 7nm but we have heard some waffling on the subject. It will be interesting to get another EUV update on 7nm and 5nm from the people who are actually using it.
Later today Intel will again keynote SPIE and present “EUV readiness for HVM” and Samsung will again present “Progress in EUV Lithography toward manufacturing”. Scotten will do thorough blogs on the conference as he has in the past. You can read Scotten’s very technical event related blogsHERE. If you are attending SPIE it would be a pleasure to meet you, absolutely.
Also read:An Steegen ISS Talk and Interview – Patterning Options for Advanced Nodes
SPIE Advanced Lithography and Synopsys!

SPIE is the premier event for lithography held in Silicon Valley and again Scotten Jones and I will be attending. EUV is generally the star of the show and this year will be no different now that TSMC has committed to EUV production in 2019.
Last year at SPIE, TSMC presented the history of EUV development from the beginning in 1985 as Soft X-Ray to the name change to EUV in 1993. TSMC forecasted that they will “exercise” EUV at 7nm and will introduce EUV for production use at 5nm. TSMC now says they will in fact insert EUV into 7nm in the second year of production (2019) in preparation for EUV at 5nm in 2020. So finally we will have EUV in production after more than 30 years of R&D and so many false starts!!!!!
This year Intel will again keynote SPIE and present “EUV readiness for HVM” and Samsung will again present “Progress in EUV Lithography toward manufacturing”. Scott will do thorough blogs on the conference as he has in the past. You can read Scott’s very technical event related blogs HERE. If you are attending SPIE it would be a pleasure to meet you, absolutely.
A new event at this year’s SPIE is the Synopsys Technical Forum where you will learn the latest on Synopsys Manufacturing’s mask synthesis, mask data prep and lithography simulation solutions. The Tech Forum is peer-to-peer, giving you the opportunity to hear how your lithography colleagues have addressed the challenges of 10nm and 7nm.
Overview
Synopsys provides industry-proven EDA solutions to meet the demands of today’s advanced IC manufacturing processes while setting the standard in platform flexibility to enable innovative and custom solutions for next-generation technology nodes. Synopsys’ comprehensive Mask Synthesis, Mask Data Preparation, TCAD, and Yield Management tools provide leading edge performance, accuracy, quality, and cost of ownership for all your production and development needs.
Synopsys Technical Forum Agenda
[TABLE] cellpadding=”5″ style=”width: 100%”
|-
| align=”center” valign=”top” | Time
| valign=”top” style=”width: 400px” | Presentation Title
| align=”center” valign=”top” | Speaker
| align=”center” valign=”top” | Company
|-
| valign=”top” | 12:30
| colspan=”3″ valign=”top” | Registration & Lunch
|-
| valign=”top” | 1:00
| valign=”top” | Welcome & Introduction
| align=”center” valign=”top” | Howard Ko
| valign=”top” | Synopsys
|-
| valign=”top” | 1:30
| valign=”top” | DTCO Metrics for Patterning Design Arc Definition at 7nm and Beyond
| align=”center” valign=”top” | Derren Dunn, Ph.D.
| valign=”top” | IBM
|-
| valign=”top” | 2:10
| colspan=”3″ valign=”top” | Break & Prize Drawing #1
|-
| valign=”top” | 2:25
| valign=”top” | ILT Optimization of EUV Masks for Sub – 7nm Lithography
| align=”center” valign=”top” | Kevin Lucas
| valign=”top” | Synopsys
|-
| valign=”top” | 3:05
| valign=”top” | Keynote: Advanced Patterning and Litho Options for Challenging Geometries
| align=”center” valign=”top” | Hyunjo Yang
| valign=”top” | SKHynix
|-
| valign=”top” | 3:50
| colspan=”3″ valign=”top” | Thank You & Drawing #2
|-
Visit Synopsys at Booth #206
Tuesday, February 28: 10:00 a.m. to 5:00 p.m.
Wednesday, March 1: 10:00 a.m. to 4:00 p.m.
Location
San Jose Convention Center
Directions
Synopsys Technical Program
Security applications for direct-write lithography(Keynote Presentation)
Mike Borza, Synopsys Inc. (Canada) [10144-3]
Correlation of experimentally measured atomic scale properties of EUV photoresist to modeling performance: an exploration
Yudhishthir Kandel, Synopsys, Inc. (USA); Jonathan Chandonait, SUNY Polytechnic Institute (USA); Sajan Marokkey, Lawrence S. Melvin III, Qiliang Yan, Benjamin D. Painter, Synopsys, Inc. (USA); Gregory H. Denbeaux, SUNY Polytechnic Institute (USA) [10143-7]
Modeling EUVL patterning variability for metal layers in 5nm technology node and its effect on electrical resistance
Weimin Gao, Synopsys GmbH (Belgium); Lawrence S. Melvin III, Synopsys, Inc. (USA); Itaru Kamohara, Synopsys GmbH (Germany); Vicky Philipsen, Vincent Wiaux, Eric Hendrickx, Ryoung-Han Kim, IMEC (Belgium)[10143-14]
Advanced fast 3D DSA model development and calibration for design technology cooptimization
Kafai Lai, IBM Thomas J. Watson Research Ctr. (USA); Balint Meliorisz, Thomas Mülders, Hans-Jürgen Stock, Synopsys GmbH (Germany); Sajan Marokkey, Synopsys, Inc. (USA); Wolfgang Demmerle, Synopsys GmbH (Germany); Chi-Chun Liu, Cheng Chi, Jing Guo, Albany NanoTech (USA)[10144-16]
Experimental characterization of NTD resist shrinkage
Bernd Küchler, Thomas Mülders, Synopsys GmbH (Germany); Hironobu Taoka, Nihon Synopsys G.K. (Japan); Weimin Gao, Synopsys NV (Germany); Ulrich Klostermann, Synopsys GmbH (Germany); Sou Kamimura, FUJIFILM Corp. (Japan); Grozdan Grozev, FUJIFILM Corp. (Belgium); Masahiro Yoshidome, Michihiro Shirakawa, FUJIFILM Corp. (Japan); Waikin Li, IMEC (Belgium)[10147-14]
Modeling of NTD resist shrinkage
Thomas Mülders, Hans-Jürgen Stock, Bernd Küchler, Ulrich Klostermann, Wolfgang Demmerle, Synopsys GmbH (Germany)[10146-21]
Source defect impact on pattern shift
Artak Isoyan, Chander Sawh, Lawrence S. Melvin III, Synopsys, Inc. (USA) [10147-21]
Cost effective solution using inverse lithography OPC for DRAM random contact layer
Jinhyuck Jeon, Jae-Hee Hwang, Jaeseung Choi, Seyoung Oh, Chan-Ha Park, Hyun-Jo Yang, SK Hynix, Inc. (Korea, Republic of); Thuc Dam, Synopsys, Inc. (USA); Munhoe Do, Dongchan Lee, Synopsys Korea Inc. (Korea, Republic of); Guangming Xiao, Jung-Hoe Choi, Kevin Lucas, Synopsys, Inc. (USA)[10148-8]
Resist 3D aware mask solution with ILT for resist failure hotspot repair
Guangming Xiao, Kosta S. Selinidis, Kevin Hooker, Synopsys, Inc. (USA); Wolfgang Hoppe, Synopsys, Inc. (Germany); Thuc Dam, Kevin Lucas, Synopsys, Inc. (USA)[10147-25]
New methodologies for lower-K1 EUV OPC and RET optimization
Kevin Hooker, Yunqiang Zhang, Kevin Lucas, Aram Kazarian, Joshua P. Tuttle, Guangming Xiao, Synopsys, Inc. (USA)[10143-45]
Exposure source error and model source error impact on optical proximity correction
Lawrence S. Melvin III, Artak Isoyan, Chander Sawh, Synopsys, Inc. (USA)[10147-32]
Guiding gate-etch process development using 3D surface reaction modeling for 7nm and beyond (Invited Paper)
Derren N. Dunn, IBM Research (United States); John R. Sporre, Univ. of Illinois at Urbana-Champaign (United States); Ronald Gull, Synopsys Switzerland, LLC (Switzerland); Peter Ventzek, Tokyo Electron America, Inc. (United States); Alok Ranjan, TEL Technology Ctr., America, LLC (United States) [10149-36]
Synopsys Posters
Compact modeling for the negative tone development processes
Lawrence S. Melvin III, Synopsys, Inc. (USA); Chun-Chieh Kuo, Synopsys, Inc. (Taiwan); Jensheng H. Huang, Synopsys, Inc. (USA)[10147-63]
Addressing optical proximity correction (OPC) challenges from highly nonlinear OPC models
Stephen Jang, Synopsys, Inc. (USA) [10147-64]
Stitching-aware in-design DPT auto fixing for sub-20nm logic devices
Soo Han Choi, David Pemberton-Smith, Sai Krishna K.V.V.S, Synopsys, Inc. (USA)[10148-46]
Using pattern matching to increase performance in hotspot fixing flows
Bradley J. Falch, Synopsys, Inc. (USA) [10148-49]
AAPl Vs QCOM Who wins?
Things just got interesting in the iPhone supply chain with the $1B AAPL Vs QCOM legal action filed this week. For the life of me I could not understand why Apple second sourced the normally QCOM modem in the iPhone 7. It caused quite a stir in the technical community but we could only surmise that it was a price issue on the business side. Well, clearly it was more than just price.
AAPL:“For many years Qualcomm has unfairly insisted on charging royalties for technologies they have nothing to do with. The more Apple innovates with unique features such as TouchID, advanced displays, and cameras, to name just a few, the more money Qualcomm collects for no reason and the more expensive it becomes for Apple to fund these innovations. Qualcomm built its business on older, legacy, standards but reinforces its dominance through exclusionary tactics and excessive royalties. Despite being just one of over a dozen companies who contributed to basic cellular standards, Qualcomm insists on charging Apple at least five times more in payments than all the other cellular patent licensors we have agreements with combined.”
Apple seems to be piggy backing on the legal actions against QCOM from China, Korea, Taiwan, EU, and the USA. But Apple’s problems may have started when they used Intel modems and broke an exclusivity clause with QCOM. Either way this is a legal mess that may not be resolved for months or even years.
QCOM:Apple’s complaint contains a lot of assertions. But in the end, this is a commercial dispute over the price of intellectual property. They want to pay less than the fair value that QUALCOMM has established in the marketplace for our technology, even though Apple has generated billions in profits from using that technology
In the meantime let’s look at the modem issue and see who will ultimately profit. My bet is TSMC of course and here is why:
Remember, even though Intel supplies the XMM 7360 LTE modem used in the iPhone 7, TSMC manufactures it on their 28nm process. The next-in-line Intel modem is the XMM 7480 which was announced one year ago and is now being qualified by AT&T and other carriers. Intel has made statements in the past that they will move modem manufacturing from TSMC to Intel so the $1B question is: Who will manufacture the XMM 7480?
Here is the answer from the J.P. Morgan Tech Forum at CES 2017:
Q – Harlan Sur: So you guys recently got qualified with your next-gen XMM 7480 modem. Help us understand, first of all, is this product being manufactured by Intel internally or is it still being manufactured at TSMC?
A – Navin Shenoy: We’ll make decisions on where we manufacture the modem on a pragmatic basis. I’m not going to tell you right now yet where we’re going to manufacture XMM 7480 or the subsequent ones. But suffice it to say, we’re looking at both internal and external options.
Clearly that decision has already been made since the chip is in production. As you can tell Navin (Intel Client Computing Group VP) is a career Intel employee well versed in doublespeak. I was hoping Murthy Renduchintala (Navin’s boss) would rid Intel of double speakers but clearly that is not the case, yet.
If it was on an Intel process you can bet Navin would have proudly boasted, so my bet is that the XMM 7480 is already in high volume manufacturing using TSMC 28nm and it is highly unlikely it will be moved to Intel 14nm. In my opinion the first Intel modem to use an Intel process (14nm) is the 5G modem they announced this month. 4G modems are a price driven commodity and nobody does 28nm better than TSMC. I would also argue that the TSMC 16FFC process is better than Intel 14nm for price and power but Intel needs to prove their ability to manufacture mobile chips to justify the huge investment they have made so it will probably be Intel 14nm.
The other winner of course is one of my favorite IP companies (CEVA) as their IP is designed in the Intel 4G modem. Intel licensed CEVA-XC core for LTE chips back in 2010 at around the same time it acquired Infineon’s wireless business unit. Infineon is also a CEVA licensee for their ARM-based 3G and 4G LTE modems.
The Intel Corporate Earnings call is tonight so we can continue this discussion in the comments section…
DARPA Flex Logix and TSMC!
When I first saw emerging semiconductor IP company Flex Logix actively involved with TSMC I knew something big was coming and boy was I right. DARPA announced today that an agreement is in place with Flex Logix to develop EFLX eFPGA technology on TSMC 16FFC for use by companies or Government agencies designing chips for the US Government. Wow! GO DARPA!
“Embedded FPGA technology is a game changer in the chip design process and we are pleased to be working with DARPA,” said Geoff Tate, CEO and co-founder of Flex Logix. “Chip development costs and lead times keep increasing and the ability to reconfigure RTL at any time can eliminate expensive chip spins, enable one chip to address many customers and applications, and extend the life of chips and systems. As a result, designers can easily keep up with changing standards and customer requirements.”
Digging a little deeper you will find that this announcement is tied to the DARPA Microsystems Technology Office (MTO) and specifically the Craft Project:
It can cost up to $100 million and take more than two years for a large team of engineers to design custom integrated circuits for specific tasks, such as synchronizing the activity of unmanned aerial vehicles or the real-time conversion of raw radar data into tactically useful 3-D imagery. This is why Defense Department engineers often turn to inexpensive and readily available general-purpose circuits, and then rely on software to make those circuits run the specialized operations they need. This practice can speed up design and implementation, but it also results in the deployment of unnecessary and power-hungry circuitry. And that, in turn, can lead to technology that requires more power than can be practically supplied on small flying platforms or on warfighters already burdened by too much battery weight.
The Circuit Realization at Faster Timescales (CRAFT) program seeks to shorten the design cycle for custom integrated circuits to months rather than years;devise design frameworks that can be readily recast when next-generation fabrication plants come on line; and create a repository of innovations so that methods, documentation, and intellectual property can be repurposed, rather than reinvented, with each design and fabrication cycle. This novel, less expensive design paradigm also could help diversify the innovation ecosystem by making it practical for small design teams to take on complex custom circuit development challenges that are out of their reach today.
Reducing the time and cost for designing and procuring custom, high-efficiency integrated circuits, should drive more of those in the DoD technology community toward best commercial fabrication and design practices. A primary payoff would be a versatile development environment in which engineers and designers make decisions based on the best technical solutions for the systems they are building, instead of worrying about circuit design delays or costs.
The program manager on Craft is Dr. Limton Salmon who came to DARPA from both sides of the semiconductor industry. He spent 15 years in executive roles directing development of CMOS technology from the 130nm through the 7nm node at GlobalFoundries, Texas Instruments and Advanced Micro Devices. Prior to that Dr. Salmon was an academic at Case Western Reserve University and Brigham Young University.
We have been covering FlexLogix on SemiWiki for 12 months now and have a dozen articles on different aspects of the technology and company. The SemiWiki Flex Logix landing page is HERE.
Congratulations to the hard working people at DARPA, Flex Logix, and TSMC, absolutely.
About Flex Logix
Flex Logix, founded in March 2014, provides solutions for reconfigurable RTL in chip and system designs using embedded FPGA IP cores and software. The company’s technology platform delivers significant customer benefits by dramatically reducing design and manufacturing risks, accelerating technology roadmaps, and bringing greater flexibility to customers’ hardware. Flex Logix recently secured $7.4 million of venture backed capital. It is headquartered in Mountain View, California and has sales rep offices in China, Europe, Israel, Taiwan and Texas. More information can be obtained at http://www.flex-logix.com or follow on Twitter at @efpga.
Another Interesting Thing From TSMC!
As I mentioned in my previous post, the TSMC investor call this month was very interesting and Morris Chang was in fine form during the Q&A. As a semiconductor professional I think some of the questions are ridiculous but maybe they have value to the financial people. This one question from Randy, who I think is very astute, is SemiWiki discussion worthy:
Randy Abrams
Yes, thank you. The first question, I wanted to ask your outlook is more in line with the industry where you are guiding 5% to 10% for foundry near similar levels. Could you talk about the factors to be more inline after gaining the last few years? And can you also address the China business; we are seeing the China foundries grow faster. SMIC is growing 20% to 30%, how does TSMC combat or defend share more on the mature nodes, where they’re starting to grow faster?
(At the bottom it says SMIC is partially owned by TSMC. TSMC did get a 10% equity stake after the IP litigation which I thought TSMC had already divested. Please post a comment if you know otherwise.)
First and foremost, TSMC is being conservative as they always are and they are shielding their #1 customer which is Apple. There is no way the second half of the year will be 5% growth with Apple single sourcing 10nm from TSMC for the next iPhone and iPad. TSMC will again be in double digits (10-15% revenue growth) for 2017 as I previously stated.
This is going to be another strong year for the foundries but I do find it interesting that while the semiconductor foundry business is posting double digit gains the semiconductor industry as a whole is relatively flat… Comments?
Second, SMIC is surging on 2[SUP]nd[/SUP] source business now that they are shipping a TSMC compatible 28nm, most of which is in China. How does TSMC combat or defend the mature nodes? In China they don’t, they push the market to FinFETs. Remember, the TSMC GDS compatible market stops with FinFETs and SMIC does not expect to have 14nm until 2020 or so. Meanwhile TSMC is getting ready to release a fourth generation (12nm) FinFET process optimized for density and cost. In fact, I hope TSMC shows an updated version of the infamous Intel chip scaling graph shown below.
Remember, this graph was based on a paper done by TSMC before 16nm went into production. TSMC then released 16FF+, 16FFC, and now 12nm.
My guess is that TSMC 12nm will easily be on par with Intel 14nm in regards to chip density and superior in cost per transistor… Comments?
Unfortunately, Intel is still flogging this outdated slide. In fact, just this month at the J.P. Morgan 2017 Tech Forum, Intel Client Computing Group VP Navin Shenoy said Intel 14nm is equivalent to Samsung and TSMC 10nm so they are considering renaming their 10nm:
“I’m confident that when 10 nanometer — our 10 nanometer — comes out, and this is something that maybe we should rename it, I don’t know, we’ll think about that, but when our 10 nanometer comes out, we will have a clear density advantage, and a clear performance and power advantage versus what others in the industry have.”
Well, yes and no. Unfortunately for Intel their 10nm will come out about the same time as TSMC 7nm so no, Intel will not have a clear density advantage:
Morris Chang
I think 2017 will be pretty strong in terms of technology, it will be a pretty strong 16 or 14 FinFET year, and our market share in 16, while it’s quite high, is not as high as I would like, it’s actually in the close to 70% or 65% to 70%. Now that is not quite as high as our 28 nanometer which even now, you know, like almost 80% and now, 2017 is – I think it’s a pretty – we think will be a pretty strong year and result.
Absolutely…
Fan-Out Wafer Level Processing Gets Boost from Mentor TSMC Collaboration
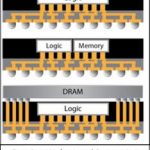
I caught up with John Ferguson of Mentor Graphics this week to learn more about a recent announcement that TSMC has extended its collaboration with Mentor in the area of Fan-Out Wafer Level Processing (FOWLP).
In March of last year Mentor and TSMC announced that they were collaborating on a design and verification flow for TSMC’s InFO (integrated Fan-Out) packaging technology using Mentor’s Xpedition Enterprise and Calibre nmDRC/RVE platforms. That flow allowed designers to layout the InFO structures with Mentor’s Xpedition Package Integrator and then use Calibre nmDRC for design rule checking with cross probing back into Xpedition using Calibre RVE.
Since then, the Mentor and TSMC teams have been working closely together to enhance the flow to shorten design cycle times, minimize designer effort and ensure higher quality GDS hand-offs to improve first-time success rates. Key to the collaboration were efforts to ensure seamless assimilation of TSMC’s newest technologies whether it be single or multiple die on InFO packaging, with or without a substrate, and with or without package-on-package. To achieve this, Mentor has attacked several different areas.
Firstly, Mentor developed new Xpedition Enterprise functionality to make it easier to create InFO-specific fab-ready metal structures such as seal rings, parameterized mesh pad generation, degassing holes and additional metal for balancing metal density.
Mentor next added HyperLynx DRC technology to the flow for in-design InFO-specific manufacturing verification checks. HyperLynx DRC allows designers to find and fix DRC issues while still in the design phase reducing the number of iterations out to GDSII for DRC checking in Calibre. Final sign-off rule checking is still done with Calibre nmDRC for both die and InFO package design rule checks.
New to the flow with this release is the addition of Calibre 3DSTACK and the capability to do sign-off level layout-vs-schematic (LVS) checks for inter-die connectivity verification of the entire InFO-based package.
For IC designers this may sound trivial, but when you realize that you are possibly dealing with multiple die, each with their own CAD database, as well as data for the silicon wafer providing the InFO connectivity you start to see how messy the CAD flow can get. Also considering each die may have thousands of pins you also realize how easy it would be to get something hooked up wrong and how hard it would be to find a mistake without good LVS tools. This will be a much appreciated addition to the flow.
In December of 2016, John was interviewed for an article in Chip Scale Review in which he outlined how TSMC has worked with EDA companies like Mentor to develop EDA solutions for IC and package design with an intent to ensure that InFO designs would be fully compliant with TSMC’s packaging design rules and sign-off requirements. At that time, John mentioned that TSMC was in fact working to expand the InFO tool support into sign-off electrical analysis to enable designers to analyze the parasitic impacts from InFO and its neighboring layers. It appears this is now in place for the Mentor flow, with the addition of signal integrity checking of the InFO interconnects using signal path tracing, extraction, simulation and netlist export.
The flow also now supports integration to thermal analysis and thermally-aware post-layout simulation flows to provide early identification of potential system level heat issues. The connection to the simulation world also enables such things as multi-die reliability analysis including analysis of electromigration and IR drop.
While Fan-Out Wafer Level Processing is catching on with its promises of low cost, small form factors, and low power with high performance, the addition of a fully integrated IC and package design flow goes a long way toward making this a truly usable technology. TSMC is using its extensive expertise in generating process design kits for advanced IC processes along with their significant experience and long historic relationships with EDA players like Mentor Graphics to jump out well ahead of their OSAT (outsource assembly and test) competitors in bringing FOWLP technology into real production use.
See Also: