
The headline of the latest Synopsys press release drops quite a tease: the newest release of Synplify delivers up to 3x faster runtime performance in FPGA synthesis. In our briefing for this post, we uncovered the surprising reason why – and it’s not found in their press release.
Quickly, for those not familiar with Synopsys Synplify, it is their vendor-agnostic FPGA synthesis tool supporting parts from Achronix, Altera, Lattice, Microsemi, and Xilinx. It comes in two versions, with Synplify Pro providing a highly capable synthesis flow. Synplify Premier extends functionality including advanced incremental and distributed synthesis, improved debug with watch points and triggers, added power optimization, and automation of high-reliability constructs such as triple modular redundancy.
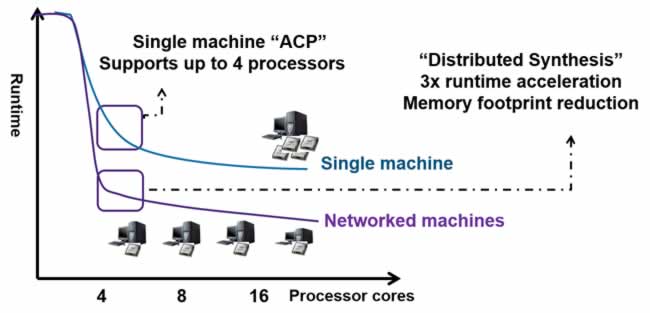
In a SemiWiki piece from May 2014, I discussed the then-new automatic compile point (ACP) technology inside Synplify. This was a big step in enabling faster runtimes. It sets known-good points from which incremental builds can proceed without recompiling the entire design. ACP also allows some multiprocessing parallelism in synthesis.
Reading this new press release quickly, it discusses “new multiprocessing technology”. Spoiler alert: Synplify was already taking advantage of multiprocessing for synthesis.

Whenever I run across something like this, I think of George Carlin and a question he used to ask in more colorful terms. If the prior release of “new & improved” product was so good – claims on the existing Synplify web page cite 10x improvement in runtimes – how does this new round of product enhancement make such a dramatic increase?
As luck would have it, I’ve been studying the subject of big data architecture for one of my consulting clients. Pawing through pages of research on Hadoop, Spark, and other distributed processing techniques, a theme emerges. Big data does not actually operate on big files. Speed comes from parsing a large file into hundreds or thousands of smaller ones, and using distributed nodes to process those smaller files. Those smaller tasks can then be analyzed to see if they fall into CPU intensive or storage intensive categories. Often times, the fix is not more processors, or bigger processors – it is a simple change in the storage techniques, like moving some elements in-memory or onto faster SSDs.
Relax, I’m not going to apply what I call the “big data paint job” to the Synopsys story just yet. FPGA design files are big, but they aren’t petabytes and beyond big. Parallelism in the basic Synplify environment is up to 4 processor cores, not hundreds; additional cores beyond 4 require additional licensing. Yet, the idea of parallelism is sound, and Synopsys is using it – we see they are hinting at 8 and 16 cores in a networked FPGA synthesis farm.
So, I asked Joe Mallett of Synopsys the question: are you using an open source technique similar to Hadoop to split the FPGA synthesis problem up? The answer was a firm “no”, but what Joe did tell me was Synopsys has spent a whole lot of time on a proprietary, distributed database underneath Synplify. They have been hunting down performance bottlenecks and making improvements in resource utilization for their FPGA synthesis workload. From what I found over in big data land, it is not surprising there were a few critical database tweaks for small-scale parallelism that could yield a substantial performance increase in Synplify.
Combining ACP with distributed synthesis capability in this release of Synplify, albeit on a smaller scale with just a few machines, leads to improvement in the key metric for FPGA developers: iterations per day. The whole idea of FPGAs is to be able to make changes quickly, but on a large device resynthesizing those changes can take time. Synplify is all about cutting integrate and build time, allowing more design exploration and faster fixes to issues uncovered at debug. This new release also adds automated handling of IP integration, dealing with RTL, netlists, and encrypted IP such as IEEE P1735.
Synopsys has also spent a lot of time on physical awareness of both the newest FPGAs and older ones – in some cases, very old. Joe shared a story of a recent project resurrecting code for an FPGA circa 1998, handled in the current version of Synplify. This is key to quality of results (QoR). Synthesis isn’t very good if it doesn’t actually fit or close on the device in question, and one size definitely does not fit all when we are talking about Altera Arria 10 and Xilinx UltraScale and other newer devices versus older technology. By understanding the device being targeted, Synplify continues to make strides in QoR.
Now you know the backstory for the Synopsys press release:
This is a big challenge, providing a synthesis tool that can handle a variety of FPGA devices with appropriate optimizations while scaling to an expanding design size frontier. If you remember those frustrating days of the overnight FPGA build only to discover something missing and requiring another build, the objective of increasing the number of iterations per day with Synplify is appreciated.
Share this post via:



Comments
0 Replies to “Why FPGA synthesis with Synplify is now faster”
You must register or log in to view/post comments.