
If we look at the semiconductor industry expansion during the last 25 years, adoption of design IP in every application appears to be one of the major factors of success, with silicon technology incredible development by a x100 factor, from 250nm in 2018 to 3nm (if not 2nm) in 2023. We foresee the move to chiplet-based architecture to soon play the same role that SoC chip-based architecture and massive use of design IP has played in the 2000’s.
The question is how to precisely predict chiplet adoption timeframe and what will be the key enablers for this revolution. We will see if diffusion of innovation theory can be helpful to fine-tune a prediction, determine what type of application will be the driver. Chip-to-chip interconnect protocol standard specifications allowing fast industry adoption, driving applications like IA or smartphone application processor quickly seems to be the top enabler, but EDA tools efficiency or packaging new technologies and dedicated fab creation, among others, are certainly key.
Introduction: emergence of chiplet technology
During the 2010-decade, the benefits of Moore’s law began to fall apart. Moore’s law stated transistor density doubled every two years, the cost of compute would shrink by a corresponding 50%. The change in Moore’s law is due to increased in design complexity the evolution of transistor structure from planar devices, to Finfets. Finfets need multiple patterning for lithography to achieve devices dimensions to below 20-nm nodes.
At the end of this decade, computing needs have exploded, mostly due to proliferation of datacenters and due to the amount of data being generated and processed. In fact, adoption of Artificial Intelligence (AI) and techniques like Machine Learning (ML) are now used to process ever-increasing data and has led to servers significantly increasing their compute capacity. Servers have added many more CPU cores, have integrated larger GPUs used exclusively for ML, no longer used for graphics, and have embedded custom ASIC AI accelerators or complementary, FPGA based AI processing. Early AI chip designs were implemented using larger monolithic SoCs, some of them reaching the size limit imposed by the reticle, about 700mm2.
At this point, disaggregation into a smaller SoC plus various compute and IO chiplets appears to be the right solution. Several chip makers, like Intel, AMD or Xilinx have select this option for products going into production. In the excellent white paper from The Linley Group, “Chiplets Gain Rapid Adoption: Why Big Chips Are Getting Small”, it was shown that this option leads to better costs compared to monolithic SoCs, due to the yield impact of larger. These chip makers have designed homogenous chiplet, but the emergence and adoption of interconnect standard like Universal Chiplet Interconnect Express (UCIe) IP is easing adoption of heterogeneous chiplet.
The evolution of the newer, faster, protocol standards is picking up speed as the industry keeps asking for higher performance. Unfortunately, the various standards are not synchronized by a single organization. New PCIe standards can come one year (or more) earlier or later than the new Ethernet protocol standard. Using heterogeneous integration allows silicon providers to adapt to the fast-changing market by changing the design of the relevant chiplet only. Considering advanced SoC design fabrication requires massive capital expenditures for 5nm, 4nm or 3nm process nodes, the impact of chiplet architectures is tremendous to drive future innovation in the semiconductor space.
Heterogeneous chiplet design allows us to target different applications or market segments by modifying or adding just the relevant chiplets while keeping the rest of the system unchanged. New developments could be launched quicker to the market, with significantly lower investment, as redesign will only impact the package substrate used to house the chiplets. For example, the compute chiplet can be redesigned from TSMC 5nm to TSMC 3nm to integrate larger L1 cache or higher performing CPU or number of CPU cores, while keeping the rest of the system unchanged. Chiplet integrating SerDes can be redesigned for faster rates on new process nodes offering more IO bandwidth for better market positioning.
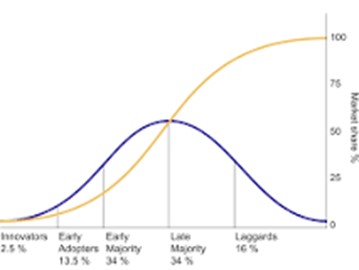
Using heterogeneous chiplet will offer better Time-to-Market (TTM) when updating system, reusing the part of system with no change if it’s designed in chiplet. This will also be a way to minimize cost when keeping some functional chiplet on less advanced nodes, cheaper than the most advanced. But the main question is to forecast when the chiplet technology will create a significant segment of the semiconductor market? We will review the IP adoption history as chiplet and IP are similar, both have to break the NIH syndrome to become successful. We will extract the main causes of chiplet adoption and build a forecast, using the innovation theory and the defined category (Innovators, Early Adopters, etc. see Figure below).
We will review ARM CPU IP adoption through 1991 to 2018 and IP adoption history through 1995 to 2027, and check how this adoption rate stick with the Innovation Theory.
We will explain why chiplet adoption will be boosted, reviewing the technology and marketing related reasons:
- From IP-based SoC to chiplet-based system
- Interoperability, thanks to chiplet interconnect preferred protocol standard
- Explaining why high-end Interface IP are key for Chiplet adoption
- Design-related challenges to solve.
- Last but not least, investment made by foundry
Finally, we can build a tentative chiplet adoption forecast, based on innovation theory. Just to mention, the industry just moved in the “Early adopters” phase, seeing numerous IP and chiplet vendors serving HPC and AI.
If you download the white paper, you will enjoy with all the text, and numerous pictures, some of them beeing created exclusively for this work.
By Eric Esteve (PhD.) Analyst, Owner IPnest
Alphawave sponsored the creation of this white paper, but the opinions and analysis are those of the author. Article can be found here:
https://awavesemi.com/resource/will-chiplet-adoption-to-mimic-ip-adoption/
Also Read:
Disaggregated Systems: Enabling Computing with UCIe Interconnect and Chiplets-Based Design
Interface IP in 2022: 22% YoY growth still data-centric driven
Share this post via:



Comments
2 Replies to “Will Chiplet Adoption Mimic IP Adoption?”
You must register or log in to view/post comments.