In the course of building my understanding of functional safety, particularly with respect to ISO 26262, I have developed a better understanding of the design methods used to mitigate safety problems and the various tools and techniques that are applied to measure the impact of those diagnostics against ASIL goals. One area in which I was struggling was the failure mode effects analysis (FMEA), which seems to be viewed as a “given” in many presentations. I didn’t see any explanations on how the FMEA was developed in the first place. That was a problem for me because everything else in functional safety is built on top of the FMEA; get that wrong and the rest of your effort is pointless, no matter how cleverly applied. So I asked Alexis Boutillier (Corporate Apps Manager and Safety Manager at Arteris IP) to explain.
Alexis started with a great question – how are you going to prove to your customer that your safety analysis is satisfactory? Obviously you can’t get away with “our experts checked it out and all possible failures are covered”. But you also can’t get away with “here’s a list of all the safety-critical features and related diagnostic logic”. The analysis has to be more objective and reviewable by someone not expert in your design. This is what the FMEA (within the standard) provides; a method to remove opinion, no matter how expert, from the loop.
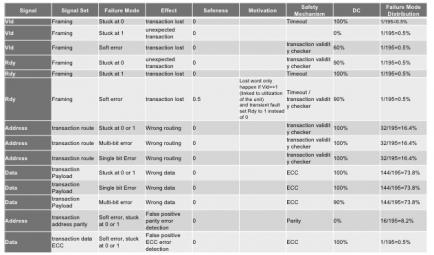
Alexis demonstrated using a routing component in a NoC IP as an example (see the table figure). The table looks at each signal at a time and considers the potential impact of different types of error on that signal, both permanent and transient. Since this is a router, there can be impact from failures affecting the header and failures affecting the payload. Permanent (e.g. manufacturing) errors are modeled as stuck at zero or one and transient errors (e.g. soft errors from neutron-induced ionization) might result in bit flips and/or might lead to multi-bit errors.
Then in each case, you determine the effect of that failure. An error in framing might lead to a transaction being lost or an unexpected transaction. An error in the address could lead to incorrect routing and an error in the data naturally leads to bad data. You can also qualify these assessments with an explanation if they will only happen in certain circumstances. Next you describe a safety mechanism to either detect or correct for that error, along with your estimate of the effectiveness of that mechanism. So now you know, for each possible failure, the coverage you have in mitigating that failure. So far, so good. Very systematic, you could share this with a customer and they would agree you have done a comprehensive and objective job of covering possible the possible failure modes.
The really interesting question is – how likely is each of these failure modes? This is where it would be easy to slide back into opinion-based debate which would undermine the objectivity goal. One way to overcome this is to base failure distribution on the number of signals in that mode as a percentage of the total number of signals in the design. In the first entry on the table the mode is associated with a single signal out of 195 total signals, so it contributes just 0.5% to the distribution. This single-point fault analysis is in line with the standard and better meets an expectation of objectivity than would expert judgement. From a Tier1 or OEM viewpoint there’s nothing objective about being asked to trust a semiconductor supplier design expert for their opinion on probable distributions.
This would make building and FMEA very challenging if you started with a decent-sized IP which hadn’t been designed from the outset around these objectives. A big chunk of flat RTL would be painful to analyze comprehensively (many more possible failure modes) as would logic where failure modes had interdependencies between sub-functions (which would have to be grouped together for FMEA, I would guess). Analyzing big complex FMEAs would also make for challenging compliance reviews with customers (tell me again why this covers all possible failure modes? I got lost 20 pages back…) But if the IP is designed bottom-up for this kind of support, each component FMEA is easier to understand and these will drop neatly into FMEA analysis in the larger system (where FMEAs can also be composed together more automatically). The net of this is that it’s best to compose FMEAs in a modular and hierarchical fashion, which you can do if the IP has been micro-architected from the outset to support this analysis.
There’s a lot more to safety and how IP suppliers need to support their customers in their safety activities. I touched on some of this in my last blog for Arteris IP (ISO 26262: My IP Supplier Checks the Boxes, So That’s Covered, Right?). All of this that support starts with the FMEA. You can learn more about Arteris IP approaches safety in their design HERE.
Share this post via:



Comments
There are no comments yet.
You must register or log in to view/post comments.