You are currently viewing SemiWiki as a guest which gives you limited access to the site. To view blog comments and experience other SemiWiki features you must be a registered member. Registration is fast, simple, and absolutely free so please,
join our community today!
Radiation hardening is admittedly not a challenge every SoC design team faces. Methods to address this challenge typically involve a new process technology, a new library or both. Trusted, secure design is something more design teams worry about and that number is growing as our interconnected world creates new and significant… Read More
HCL Compass is quite a powerful tool to accelerate project delivery and increase developer productivity. Last August I detailed a webinar about HCL Compass that will help you understand the benefits and impact of a tool like this. This technology falls into the category of DevOps, which aims to shorten the systems development … Read More
Everyone is talking about 5G these days. The buildout is beginning. The newest iPhone supports the new 3GPP standard. Excitement is building. But there is a back story to all this. Silicon Catalyst recently added a new company called mmTron to their incubator program. These folks are millimeter wave experts and that turns out to… Read More
In 2019 I was involved in a major project to move all our engineering and financial systems to the cloud. We succeeded in this endeavor, but it wasn’t easy. We faced a lot of infrastructure challenges during our journey. The freedom from facility management and capital budgeting offered by the cloud was significant, however. If … Read More
Let’s face it, AI is everywhere. From the cloud to the edge to your pocket, there is more and more embedded intelligence fueling efficiency and features. It’s sometimes hard to discern where human interaction ends, and machine interaction begins. The technology that underlies all this is quite complex and daunting to understand.… Read More
As I’ve discussed before, HCL Compass is a very flexible tool to define and manage development and release processes at the enterprise level. In HCL’s own words: Low-code/no-code change management software for enterprise level scaling, process customization, and control to accelerate project delivery and increase developer… Read More
The move from single-chip design to system-in-package design has created many challenges. The rise of 2.5D and 3D technology has set the stage for this. Beyond the modeling requirements and the need for ecosystem collaboration to get those models, there is a significant challenge in understanding the data. The only way to truly… Read More
Anyone even remotely associated the EDA industry will know about the Phil Kaufman award. Every industry has its ultimate recognition – the Academy Awards and the Grammys are familiar ones in pop culture. The Nobel Prize gets a bit geekier and the Morris Chang award from the GSA is geekier still. If you’re an EDA geek, the Phil Kaufman… Read More
Last August I detailed a webinar about HCL Compass, a tool that provides low-code/no-code change management capability for enterprise scaling, process customization and control to accelerate project delivery and increase developer productivity. There is a lot of activity these days to migrate various enterprise applications… Read More
Work from home (WFH) has become a normal occurrence this past year. “Do you work from home?” “Of course, where else?” Samtec is taking the whole work from home thing up a notch with a new webinar lineup for 2021. Back by popular demand, they are launching a new series of educational webinars. Started last year, the gEEk SpEEk Webinar… Read More





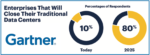
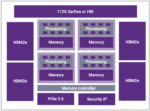













The Silicon Shield Has Never Been Stronger!