Now that we’ve looked at the basics, we wrap up this three-part series exploring PVRTC texture compression. We’ll take a brief look at PVRTC2, the latest version of the technology, and then explore the issues behind visual quality from several different angles.
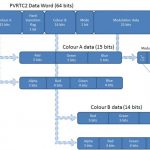
PVRTC2 is supported on the newest Series5XT or Series6 GPU cores from Imagination, retaining the modulated dual-image scheme found in PVRTC. The number of options for handling modulation data has effectively been doubled by using two new flags: an opacity flag for the entire data word, and a hard transition flag used for sub-texturing. The hard transition flag contributes to “non-interpolated” and “local palette” modes, which improve handling of discontinuities and contrasting colors.
Also introduced in PVRTC2 is support for NPOT (non power of two) textures, a feature defined in OpenGL ES 2.0. Prior to NPOT support, texture sizes had to be squared off up to the next power of two resolution, potentially wasting memory in many situations. In an extreme example, a 1600×1200 texture would have to be represented in a 2048×2048 surface. With NPOT, any size can be supported in PVRTC2; this is a big hitter removing one of the stronger objections to PVRTC.
So, let’s get to the question: how good is PVRTC2 decompression compared to other popular schemes?
PVRTC targeted block-level contemporaries and their primary shortcomings. Even the Ericsson team readily admits that ETC1 has weaknesses: “… if a block contains a number of pixels with very different chrominance, the results will be poor.” That may be overly self-deprecating, but captures the sentiment that efficiency is only part of the equation.
We see proof of “efficiency”, in terms of execution time, in a blog directly comparing the speed of ETC1 to PVRTC. The results show a big difference in initial load time (file size and memory bandwidth), and a significant difference in subsequent loads (how well the GPU and algorithm decompress the loaded images), especially applying 2bpp compression. But this poster concludes, as many others have, increased PVRTC 2bpp efficiency often comes at a price – in some situations, reduced visual quality. (I wouldn’t expect PVRTC2 to be a lot different in terms of execution time compared to PVRTC, but being supported on newer, faster GPUs may be a consideration.)
The other comment in that blog has to do with how PVRTC handles alpha transparency compared to ETC. Imagination obviously heard this type of feedback in designing PVRTC2, adding modes to handle alpha better. Game effects obviously rely heavily on transparency, but I’m intrigued by the recent debate on “flat” images in user interface design. iOS7 got a lot of criticism for going flat, but there may be some method to the madness: flat textures process a lot faster, and that can be a big contributor to a smoother user experience.
Let’s get back to overall visual quality. Eyeball tests with pixilated, jagged images yield fairly obvious conclusions when results degrade to the unacceptable. For the Imagination viewpoint, they offer a brief a case study on PVRTC2 discussing visual quality, but they only show comparisons with ETC and BC3 (one of the S3TC family) formats.
In the four test images Imagination selected – a synthetic image with color transitions, a photo, an icon typical of a user interface, and a game surface texture – it was a bit surprising to see BC3 look so bad. In this set, it is harder to tell the difference visually (at least on my monitor, and to get this to size up I had to JPG it at 100% quality which probably took out some differences) but PVRTC2 4bpp looks very comparable to ETC1 4bpp, and statistically it appears slightly better in some cases.
Many sources try to use a standardized set of compression test images like the Kodak lossless true color image suite, or the Tecnick Testimages set. For instance, Squish has done some outstanding work on the Tecnick Testimages set, comparing the statistical performance of most of the texture compression schemes available in OpenGL ES. Statistics are interesting, and one can debate the significance of some of these results. Most human eyeballs calibrate to a 2dB SNR difference, but we’d have to look much closer at standard deviation figures to see if pixelation and jaggedness are represented accurately.
For the moment, let’s take the Squish results at face value, assuming statistical figures of merit bear out in qualitative viewing. We notice PVRTC2 4bpp places right around ETC2 in most cases, only outstripped by some modes of ASTC. Interesting, ASTC was left out of the Imagination comparison … for several reasons; one is the caveat of “existing silicon” at the time of writing. ARM has the distinct benefit of late entry into this fray, with official release of ASTC in 2012, years after PVRTC debuted in late 2003. There is a great presentation on ASTC from its creators, exploring the issues they set out to address in engineering a newer solution.
Like some modes of an algorithm are better than others, there are also differences in technique that can affect results substantially. Obviously, the vast majority of images in a game or user interface are non-standard. I spent hours looking at image size and speed comparisons until finding this on improving PVRTC texture quality using Photoshop, which tells me (not surprisingly) just tossing images into the compressor and wondering why they come out fuzzy may not be the compressor’s problem. Some attention needs to be paid as to how images are designed prior to compression to get the best results.
courtesy Heyworks Unity Studio
Takeaways from this PVRTC discussion:
If you are selecting IP for an SoC, PVRTC2 is a solid choice running on a Series5XT or Series6 GPU. PVRTC is widely fielded, and state of the art is always advancing. Consider the end-to-end ramifications of software tools, GPU performance, compatibility, licensing, and other criteria when making a choice.
If you are writing apps for an Apple platform, you are already soaking in PVRTC2 – learn how to get the most from it. NPOT is a huge enhancement. 4bpp is solid, 2bpp should be evaluated carefully but it may be suitable for some images. The rebirth of flat design may be more than just an aesthetic trend, with tangible benefits in user interface performance.
If you are writing apps for Android, OpenGL ES embraces multiple texture compression formats which may or may not be supported in a particular mobile GPU – remember, software decompression in mobile is a bad, bad thing. To run in hardware on a variety of SoCs, most Android apps will need to deliver all OpenGL ES texture compression formats, perhaps using something like Adobe ATF as a container.
We’ve tried to give you a fair look at PVRTC in this series, showing what it does well and where there is room for debate. What are your thoughts and experiences?
More articles by Don Dingee…
lang: en_US