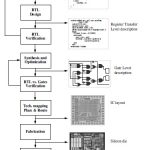
We have had the Snowden revelations that the NSA has gone rogue, Target lost a zillion credit cards, the Heartbleed bug meaning that main security protocol of the internet had been coded up wrong for a couple of years, theft of records from RSA and more. One result is that people do not completely trust a security system that depends only on software. It is too easy to break into it. People want to see that low levels of security in hardware where it is out of the reach of software breakin.
But that creates a new problem. How do you make sure that the hardware implementation isn’t equally full of loopholes. Oh, and if that isn’t enough, coming soon, the internet of things (IoT) with 50 billion devices and more on your body, in your body, in your home, your car. It is one thing if your smartphone crashes but bugs in your insulin monitor or blood-pressure monitor are more serious. Plus, while I might not care that people know I checked into a restaurant on Facebook, I don’t think I want them knowing my blood pressure hour by hour, never mind altering my insulin dosage (actually I don’t take insulin but you get the idea).
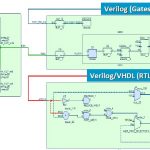
Sonics network on chip (NoC) has a lot of security features that can be enabled. A very basic one, for example, is that block A can only receive signals from block B. If block A is where the secret keys are kept, then making sure that nobody can access it from the wireless network is a big step to guaranteeing security.
Handling errors is another big one. It is almost impossible to guarantee that every block will always behave perfectly on the chip, but again the NoC sits between all the blocks and is in a position to ensure that errors do not propagate. A particular kind of error is starvation, where data get blocked because other data consume all the bandwidth, and again the NoC firewall-on-chip is the traffic cop to guarantee terms of service.
My last blog on NoC security, which goes into more under-the-hood details, is here. But I wanted to leave some room for another topic.
And now for something completely different.
This morning Gartner let Sonics publicise data for the on-chip interconnect segment. Per Gartner’s numbers, Sonics is the 7th biggest IP company and since the first 6 are all public that means they are the largest private IP company. Their revenues grew from $25M in 2012 to $36.2M in 2013, up 44.8% to a market share of almost 2/3. Mentor were next (I’m not even sure what they sell that falls in this classification, they don’t have a NoC) shrinking “only” 26.7% to end up with 21.3% market share. And Gartner reckon that Arteris went from $17.0M to $5.7M ending up with just 10% market share. One obvious question is whether that is partially due to the Qualcomm acquisition of Arteris’s technology and team, which presumably by the end of the year anyway, took that business out of the merchant market. But I can’t believe Qualcomm were 2/3 of Arteris’s revenue so that doesn’t completely match.
Of course Gartner will sell you the whole IP report Market Share: Semiconductor Design Intellectual Property, Worldwide, 2013
The full press release should be on this page.