About 10 years ago, I was in charge of the product definition of our next IP to be released, the PCI Express gen-1 Controller. I was also involved in the decision process to select the new functions to develop, in respect with the market size, all of this being the definition of “marketing”. The reason why our company decided not to develop Serial RapidIO was because the engineering team was far too busy (PCIe IP sales were exploding). At that time, we also had Hyper Transport protocol in the radar. Fortunately, we did not select Hyper Transport, but we may have decided to add Serial RapidIO to our port-folio. Serial RapidIO is very complementary with PCI Express, as the protocol’s strengths are the PCIe’s weaknesses:
- Serial RapidIO offers a very low latency (compared with PCIe, and Ethernet)
- Serial RapidIO is a “routable” protocol: it can be used to interconnect a (very) large number of processors together (when PCI Express native topology is based on a tree: one Root agent is interconnected to several Endpoints)
If you want to dig more, and better understand the differences between PCI Express, RapidIO and Ethernet, you will find an excellent article, on RapidIO web site, in Technology Comparison section. The article is written by Sam Fuller, and Sam was a founder of the RapidIO Trade Association and now serves as Head of System Solutions, Digital Networking at Freescale Semiconductor.
Serial RapidIO protocol is successfully deployed in various applications, like DSP and Processor farms, Wireless 3G, WiMax and 4G base stations, Video servers, IPTV, HDTV or Media gateways, but also in Storage and Servers systems, Avionics and Space. We may expect a move from x86 to ARM based multicore processors in Storage/Servers, and such a move would be an opportunity to further deploy RapidIO protocol. It’s not a scoop that x86 and PCIe are often associated together (they are brothers, both Intel’s son!). Such an association is not optimal in Storage/Servers, especially when the goal is to interconnect a large number of devices, due to the native topology of PCI Express protocol (the famous Tree). We have seen some tentative to add to the PCIe specification some complexes addendum, namely Advance Switching (AS) or Multiple Rout I/O Virtualization (MRIOV), as matter of fact, these specification have not been widely adopted. A tree stays a tree, even if you try to multiply the roots, the PCIe native topology is not optimal, especially when you have to implement a very large Switch to interconnect the many processor that are present in a Storage or a Server architecture. Thus, we may expect to see wider adoption for RapidIO protocol, along with the emergence of ARM core based server/storage chip devices.
But we all know that even the most wonderful technology or protocol would be of no use without a large ecosystem, made of IP and VIP, Test Equipment, off-the-shelf (OTS) devices like Switch Fabric… and so on. On the PHY IP side, Serial RapidIO protocol is based on XAUI or Ethernet (10G ) signaling, any PHY IP vendor supporting these protocols will be able to support Serial RapidIO.
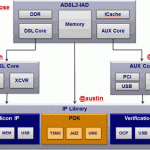
If you look at the above layered architecture, you can see that Mobiveil provides the Controller supporting SRIO 2.2, running up to 6.25 Gbps, as well as a controller extension, the RapidIO to AMBA AXI Bridge, allowing easy integration into any AMBA AXI interconnected SoC, in particular ARM CPU based processors.
You will find more complete information in Mobiveil product brief grio-pb.pdf
As I have written in one of the very blog in Semiwiki, “Design IP would be nothing without VIP”, and RapidIO Trade Organization has addressed this crucial need, as we can see here and below, extracted from the RapidIO web site:
RapidIO Bus Functional Model
The 10xN RapidIO BFM developed on behalf of the RapidIO Trade Association by Mobiveil supports RapidIO specifications 10xN (Gen3 version 3.0), 6xN (Gen2 versions 2.2 & 2.1) and 3xN (Gen1 version 1.3). The RapidIO BFM is developed in System Verilog and supports standard Universal Verification Methodology (UVM) and can be easily plugged in to any other UVM compliant verification components to extend a broader verification environment.
RapidIO BFM Features
- 1x, 2x, 4x 8x and 16x lane configurations.1.25 Gbaud, 2.5 Gbaud, 3.125 Gbaud, 5 Gbaud, 6.25 and 10.3125 Gbaud lane rates
- 66, 50 and 34-bit addressing on the RapidIO interface
- All types of packet formats
- Supports all types of IDLE sequences, Control and Status Symbols
- Scrambling/De-Scrambling and Encoding/Decoding
- Supports out of order transaction generation and handling
- Critical Request flow (CRF)
- Supports all transaction flows, with all priorities
- Test pattern generation at all protocol layers
- Error injection and error detection at all levels of protocol layers
- Provides Compliance Test Suite
- Functional Coverage
RapidIO was initially designed to serve as a processor fabric interconnect, and the protocol has most-often been used in embedded systems that require high reliability, low latency (typically sub microsecond) and deterministic operation. Using SRIO, low latency, high reliability and routable protocol should greatly help the expected explosion of ARM core based processor addressing the server/storage new applications. OTS devices, especially Switches IC from IDT, TI or LSI Logic are available, as well as RapidIO IP and VIP to support this new storage/server trend. PCI Express has been used in the past to support server/storage application, but we think that one of the main reasons was opportunistic: Intel, the market leader in these application, was obviously using x86 architecture, as well as (Intel strong promoter) PCI Express to support chip to chip interconnects, even if RapidIO would have given a better service in term of reliability and low latency. Moreover, RapidIO was defined from the beginning to serve as a processor fabric interconnects… but it was more strategic for Intel to use PCI Express than RapidIO (initially introduced by Motorola). Maybe it’s time for the server/storage industry to give a second chance to RapidIO protocol, which certainly deserve it!
From Eric Esteve from IPNEST
More Articles by Eric Esteve…..
lang: en_US