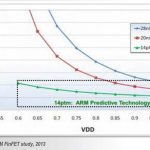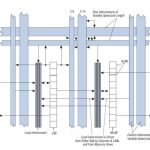
RTL designers know that their code gets transformed into gates and cells by using a logic synthesis tool, however these gates and cells are further comprised of transistors and sometimes you really need to optimize the transistor sizing to reach power, performance and area goals. I’ve done transistor-level IC design before, and the old process of manually choosing a transistor size, simulating in SPICE, analyzing, then changing the transistor size to re-iterate is a time consuming process. Once again EDA tools come to the rescue in the form of transistor-level sizing optimization.
Related: An IO Design Optimization Flow for Reliability in 28nm CMOS
I just read about an engineer at Altera named Oh Guan Hoe that wanted to use such an automated approach to design their FPGA. He presented his approach at the MunEDA User Group meeting. Alteragot started back in 1983 and offered the first reprogrammable logic semiconductor chips, and today they are #2 behind Xilinx.
The FPGA routing architecture used at Altera has two levels of hierarchy where the lowest level is an adaptive logic module (LE), and the second level is a collection of rows and columns of routing wires.
An FPGA routing switch is designed with muxing pass transistors, buffers and output demux transistors. It is the primary contributor to overall FPGA performance and hence critical for circuit optimization.
In the above diagram the buffering and drive stage has an inverter with a single PMOS device used as a half-latch to restore high levels after the single NMOS pass transistors. The final inverter size is tuned based upon the routing wire length. The NMOS pass transistors at nodes “m” and “n” represent the programmability in the routing region.Related: Five Things You Don’t Know About MunEDA…and One You Do
The performance and optimization goals were to:
[LIST=1]
The basic flow for transistor-level design and optimization at Altera is shown below:
Schematic capture is done with the popular Cadence Virtuosotool and then circuit simulation can be done with a selection of SPICE, Analog FastSPICE or FastSPICE tools. The transistor optimization step is done with a tool called WiCkeDfrom MunEDA.
An initial circuit simulation was run to establish a base line on three different driver circuits, where only DriverA actually met the driver delay goal of < 2ps:
The WiCkeD simulation analysis included:
- Simulation
- Deterministic Nominal Optimization
- Worst-case operation
Driver A was run through optimization and showed an area reduction of 12% (Green is in spec, Red is out of spec). Charts on the left-hand side are for the delay times of fall-fall, and rise-rise, respectively. The upper right chart is the delta in time delay between rise and fall. Area reduction is the final chart in the bottom right:
Results for Driver B after optimization show an area reduction of 9%:
Finally, results for Driver C after optimization show a 15% reduction in area:
In the GUI for WiCkeD you can see a comparison of nominal versus worst-case values after optimization:
Summary
Three different driver circuits were simulated and optimized at the transistor level using the WiCkeD tool to:
- Achieve a balance in rise and fall times
- Reach area reduction goals
- Run simulation and optimization in a reasonable amount of time
- The delay times were a bit off from design targets, but still within an acceptable range
Read the complete 32 page presentation here.
Upcoming Events
You can visit with MunEDA at the following events in September:
- SBCCI 2014, Brazil – Sept 1-5
- SNUG, Austin – Sept 23
- TSMC OIP, San Jose – Sept 30