How do I write about Apple so well? “I think of Steve Jobs, and I take away vision and creativity.” Please recognize that is a bit tongue in cheek, but I do think we are at a turning point where Apple is having a very hard time moving its loyal customers toward continued upgrades, and it is forcing them into unusual compromises. Continue reading “What if this is as good as the iPhone gets?”

Good bye and thank you, Andy Grove!
You are gone. And with you, gone is one of the greatest leaders of our times.
In the coming days many voices will speak about the ways in which you touched countless lives, inspired a generation of engineers to create and fuel the digital revolution, and demonstrated your own brand of leadership traits in pursuit of excellence. My voice is one such voice as I bid you farewell and thank you for all you did for humanity.
I was there when you were made Intel CEO and I was there when you retired from your chairman role. During your time you made Intel “my Intel,” for me. Moore’s Law was Gordon’s but its chief enforcer was you. Many of my management philosophies were shaped by watching you enact yours.
From you I learned how to make results more impactful with focus, discipline, and assumed responsibility. You showed what it means to be on top of the issues you managed. If there was a detail you did not know, it was because it was not important to the mission. If there was a detail that was important to the mission, you knew it. There was not an answer for which you did not have a good question. You were unapologetic about being on top of it. You were unafraid of being called a micro-manager. You were comfortable with discomfort. You were driven by, and to, quality results.
From your decision to get out of memories, I learned the concept of constancy of purpose and flexibility of paths to it. From that decision, I also learned what management courage truly is.
You introduced us to the practice of Constructive Confrontation. People like me who got to watch you perform understood what you meant by it. I taught it in Intel’s management classes in the 90s and tried to practice it in my Intel career. I used to explain that it is all about confronting and resolving issues head on and not about attacking and destroying persons involved. The practice of Constructive Confrontation resulted in intense efficiency with which Intel achieved amazing results during the 80s and 90s.
But this practice faded away as you faded away from Intel. I believe the word confrontation was too much for the post-Grove generation of managers to combine with the word constructive.
In 1989, I was part of a cross-section of mid-level managers at Intel attending a five day learning retreat called “Managing Through People” in Monterey California. Your Q&A session with us was the highlight of that retreat. During the 2 hours you spent with us I studied you as you tried to understand our questions with intense respect. Your answers were crisp, honest and insightful. We, the growing and hungry fibers in Intel’s management muscle (that is what you called us in that session), found your answers very useful. That day I promised myself to learn how to listen like you and how to think like you. I remember asking you how, when you were growing up in your management career, you handled the discomfort in your peers resulting from your intensity and focus. You seemed to understand exactly where I was coming from and said that you did not pay attention to any of that. Then, with a smile on your face, you said that I just need to make sure I am right more often than I am wrong.
You were infectious. You infected me and shaped me.
Good bye Andy. Peace to you and thanks to you.
Subscribe to my blog atwww.ReachForInfinity.com
Batman Vs Superman / Make IOT Data Security Talent your SuperPower
One of the biggest barriers to IOT success is a dearth of data security talent. Find supermen and –women to get your enterprise to the next level.
This week, Batman vs. Superman opens in theatres. Batman’s got his gadgets and Superman, his alien powers. What out-of-this-world powers will you need to get your IOT data security talent on board– up to speed?
There are so many challenges to sourcing IOT talent, it seems like you need superpowers to simply suss out the best candidates. Experts agree –finding talent remains one of the biggest barriers to getting value out of the IOT—and data security experts are often the most in demand.
David Weldon’s recent article in Information Management pointed to some disturbing trends in IOT security—as in, will security issues remain the biggest hurdle IOT practitioners face in getting projects off the ground?
The study from TEK in that article boldly stated that: “While 55% expect IoT initiatives to have a ‘transformational’ or ‘significant’ impact – just 22% of IoT initiatives have progressed to the implementation stage.”
That’s a huge gap! So what is standing in our way? Survey respondents from 200+ companies said that security and ROI are the biggest problems and that “information security experts are cited as the most difficult skill set to find.”
This same group of IOT leaders was asked where IOT initiatives would have the most impact in the next five years. We’ve used their responses to help you track the super skills you need for your data security team.
Survey respondents were very clear on where they expected IoT initiatives to impact their business on a long-term basis, factoring a five-year planning horizon. Top impacts expected were:
- 64 percent said creating better user and customer experiences – Here we have the data security expert who is often sourced from Cloud-based technology services that are outward facing, such as sales and CRM systems. A consumer-based data security pro will often help you check off your IOT bases faster than any other.
- 56 percent said sparking innovation – Data security experts who have done time protecting business development functions, start-ups, or tech product launches along the IOT can help you see the big picture. It doesn’t hurt to have an MBA-level degree in IT innovation (especially if they have worked as an IT innovations leader from within an executive committee in one of the industries your company serves.)
- 52 percent said creating new and more efficient working practices and business processes – One of the key differentiators among IT talent is their ability to lead process change and gain buy-in from key players in the company. In the field of IOT data security, make sure your security pros have spent time in the functional trenches of your industry. If they don’t understand the value levers in your particular business, they won’t know to protect them.
- 50 percent said creating new revenue streams, including new products and services – This is indeed the superpower to possess! Along with innovations experience, your data security leader should have new product experience—especially during launch, when experts agree, IOT start-up data is at the most risk. Commonly, “white hat hackers” in small- to- medium businesses fit the bill.
- 36 percent said an increased ROI on IT infrastructure – Too often data security is cut into two functions in large IT corporations—infrastructure and external. Your data security leader must be adept at identifying security challenges in both areas, or she won’t be able to calm the fears of your key investors or decision-makers when they ask what to build and how she will make it a safe platform for their IOT springboard.
- 35 percent said substantial cost savings and operational efficiencies—Our data security pro might seem too good to be true by now, but one thing we know he isn’t is a spendthrift. He should also be able to measure the value of what IOT data security leadership can do before any resources go into it—and clearly outline the risk of not spending enough on security to protect the whole shebang. A data security pro who is only concerned with the 1s and Os and not with the dollars and cents will cost more than he or she is worth.
If you want to make sure your IOT initiatives get off the ground, track where they will make the most difference to your business and then find data security professionals with IT experience in those areas
A word of caution: The popular “Security as a Service” (SECaaS) outsourcing model for security management might not work, according to another guru, Stephanie Ibo, at IM. “The irony lies within the fact that SECaaS will use the cloud as a mainstream deployment platform, when part of its own reason for existence is to enhance the protection of…the cloud!
I would argue that “large security service providers (who) integrate their products into a corporate infrastructure on a subscription basis, making security more cost effective to large corporations” will have a difficult time reaching “the ultimate objective of security implementation – “Security at the Core” – even if popular outsourced services like authentication and security event management get the enterprise a few steps closer.
The Apple FBI Battle: Laws and Ethics Simply Can’t Keep Up With Technology
The battle between the FBI and Apple over the unlocking of a terrorist’s iPhone will likely require Congress to create new legislation. That’s because there really aren’t any existing laws which encompass technologies such as these. The battle is between security and privacy, with Silicon Valley fighting for privacy. The debates in Congress will be ugly, uninformed, and emotional. Lawmakers won’t know which side to pick and will flip flop between what lobbyists ask and the public’s fear du jour. And because there is no consensus on what is right or wrong, any decision they make today will likely be changed tomorrow.
This is a prelude of things to come, not only with encryption technologies, but everything from artificial intelligence to drones, robotics, and synthetic biology. Technology is moving faster than our ability to understand it and there is no consensus on what is ethical. It isn’t just the lawmakers who are not well-informed, the originators of the technologies themselves don’t understand the full ramifications of what they are creating. They may take strong positions today based on their emotions and financial interests but as they learn more, they too will change their views.
Imagine if there was a terror attack in Silicon Valley — at the headquarters of Facebook or Apple. Do you think that Tim Cook or Mark Zuckerberg would continue to put privacy ahead of national security?
It takes decades, sometimes centuries, to reach the type of consensus that is needed to enact the far-reaching legislation that Congress will have to consider. Laws are essentially codified ethics, a consensus that is reached by society on what is right and wrong. This happens only after people understand the issues and have seen the pros and cons.
Consider our laws on privacy. These date back to the late 1800s, when newspapers first started publishing gossip. They wrote a series of intrusive stories about Boston lawyer Samuel Warren and his family. This led his law partner, future U.S. Supreme Court Justice Louis Brandeis, writing a Harvard Law Review article “The Right of Privacy” which argued for the right to be left alone. This essay laid the foundation of American privacy law, which evolved over 200 years. It also took centuries to create today’s copyright laws, intangible property rights, and contract law. All of these followed the development of technologies such as the printing press and steam engine.
Today, technology is progressing on an exponential curve; advances that would take decades now happen in years, sometimes months. Consider that the first iPhone was released in June 2007. It was little more than an iPod with an embedded cell phone. This has evolved into a device which captures our deepest personal secrets, keeps track of our lifestyles and habits, and is becoming our health coach and mentor. It was inconceivable just five years ago that there could be such debates about unlocking this device.
A greater privacy risk than the lock on the iPhone are the cameras and sensors that are being placed everywhere. There are cameras on our roads, in public areas and malls, and in office buildings. One company just announced that it is partnering with AT&T to track people’s travel patterns and behaviors through their mobile phones so that its billboards can display personalized ads. Even billboards will also include cameras to watch the expressions of passersby.
Cameras often record everything that is happening. Soon there will be cameras looking down at us from drones and in privately owned microsatellites. Our TVs, household appliances, and self-driving cars will be watching us. The cars will also keep logs of where we have been and make it possible to piece together who we have met and what we have done — just as our smartphones can already do. These technologies have major security risks and are largely unregulated. Each has its nuances and will require different policy considerations.
The next technology which will surprise, shock, and scare the public is gene editing. CRISPR–Cas9 is a system for engineering genomes that was simultaneously developed by teams of scientists at different universities. This technology, which has become inexpensive enough for labs all over the world to use, allows the editing of genomes — the basic building blocks of life. It holds the promise of providing cures for genetic diseases, creating drought resistant and high-yield plants, and new sources of fuel. It can also be used to “edit” the genomes of animals and human beings.
China is leading the way in creating commercial applications for CRISPR, having edited goats, sheep, pigs, monkeys and dogs. It has given them larger muscles, more fur and meat, and altered their shapes and sizes. Scientists demonstrated that these traits can be passed to future generations, thereby creating a new species. China sees this as a way to feed its billion people and provide it a global advantage.
China has also made progress in creating designer babies. In April 2015, scientists in China revealed that they had tried using CRISPR to edit the genomes of human embryos. Although these embryos could not develop to term, viable embryos could one day be engineered to cure disease or provide desirable traits. The risk is that geneticists with good intentions could mistakenly engineer changes in DNA that generate dangerous mutations and cause painful deaths.
In Dec. 2015, an international group of scientists gathered at the National Academy of Sciences to call for a moratorium on making inheritable changes to the human genome until there is a “broad societal consensus about the appropriateness” of any proposed change. But then, this February the British government announced that it has approved experiments by scientists at Francis Crick Institute to treat certain cases of infertility. I have little doubt that these scientists will not cross any ethical lines. But is there anything to stop governments themselves from surreptitiously working to develop a race of superhuman soldiers?
The creators of these technologies usually don’t understand the long term ramifications of what they are creating and when they do, it is often too late, as was the case with CRISPR. One of its inventors, Jennifer Doudna wrote a touching essay in the December issue of Nature. “I was regularly lying awake at night wondering whether I could justifiably stay out of an ethical storm that was brewing around a technology I had helped to create”, she lamented. Shehas called for human genome editing to the “be on hold pending a broader societal discussion of the scientific and ethical issues surrounding such use.”
A technology that is far from being a threat is artificial intelligence. Yet it is stirring deep fears. AI is, today, is nothing more than brute force computing, with superfast computers crunching massive amounts of data. Yet it is advancing so fast that tech luminaries such as Elon Musk, Bill Gates, and Stephen Hawking worry it will evolve beyond human capability and become an existential threat to mankind. Others fear that it will create wholescale unemployment. Scientists are trying to come to a consensus about how AI can be used in a benevolent way, but as with CRISPR, how can you regulate something that anyone, anywhere, can develop?
And soon, we will have robots that serve us and become our companions. These too will watch everything that we do and raise new legal and ethical questions. They will evolve to the point that they seem human. What happens then, when a robot asks for the right to vote or kills a human in self-defense?
Thomas Jefferson said in 1816, “Laws and institutions must go hand in hand with the progress of the human mind. As that becomes more developed, more enlightened, as new discoveries are made, new truths disclosed, and manners and opinions change with the change of circumstances, institutions must advance also, and keep pace with the times.” But how can our policy makers and institutions keep up with the advances when the originators of the technologies themselves can’t?
There is no answer to this question.
For more, visit my website: www.wadhwa.com and follow me on Twitter: @wadhwa.
Key Takeaways from the TSMC Technology Symposium Part 2
In Part 1, we reviewed four of the highlights of the recent TSMC Technology Symposium in San Jose. This article details the “Final Four” key takeaways from the TSMC presentations, and includes a few comments about the advanced technology research that TSMC is conducting.
Continue reading “Key Takeaways from the TSMC Technology Symposium Part 2”
What SOC Size Growth Means for IP Management
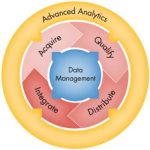
Whether or not in the past you believed all the of rhetoric about exploding design complexity in SOC’s, today there can be no debate that SOC size and complexity is well beyond something that can be managed without some kind of design management system. As would be expected, development of most larger designs relies on a data management systems, but the significant need that has arisen is for release and IP management. This is particularly true for IP, because it now constitutes such a large portion of any new SOC design.
Dedicated GPU and CPU chips have billions of transistors. SOC’s also are reaching this size and contain huge amounts of reused IP – often hundreds of blocks. It has been said that the chips of yesterday are now today’s embedded IP. This IP can be internally developed or externally sourced. Furthermore, the SOC design project itself can span multiple sites and teams. Many IP management tools used by design teams grew out of data management systems that then added on features to deal with IP and release processes. One major shortcoming of this approach is that the IP and design release process requires backtracking to add information to the design data.
Last month I spoke at length with Simon Butler, CEO of Methodics, about their approach to this problem. Rather than retrofit a data management system to attempt to add release and IP management features, they decided 5 years ago to build a complete system based on IP release and reuse. In doing so they were able to make sure their platform was data management agnostic. Simon has seen growth in the use of Perforce for enterprise revision control, and Methodics is open to it or any number of other underlying data management systems.
The most important aspect is that they use the underlying data management system in its native form, making it an open system. This makes it easier to integrate their ProjectIC into an existing corporate Perforce installation, with preexisting assets. Perforce provides a lot of valuable services, but Methodics has invested 20 man years of development on top of Perforce, to accommodate large multi-site design with potentially thousands of users. Simon says that this has consistently allowed Methodics to win challenging benchmarks.
Digging deeper, Simon explains that they have come at this problem from an enterprise IT angle, by taking concepts from DevOps, which is a movement in software development to enable rapid and continuous releases, improving quality of results by combing disciplines from development, release, testing and IT. Simon calls what they are doing “DevOps colliding with EDA”. This concept connects developers with consumers, and through continuous release monitors quality.
Methodics has gone beyond what other design management solutions are doing by implementing not just file level versioning, but by solving the more difficult challenge of using block level dedup to save space and increase performance. A fascinating example of Methodics innovation is their development of a hardware appliance, WarpStor. It is a content aware NAS optimizer that attaches to the network and links the design management software with existing high performance NAS subsystems. By serving as in intermediary with caching and intelligence about the design data, it can reduce workspace creation time, storage requirements and improve throughput.
Methodics has taken the time to rethink the nature of the IP development, release and management. Part of this comes through Simon’s previous experience in this space, and part of it is because their CTO, Peter Theunis, has an extensive background in enterprise software and infrastructure development. Their recent strong growth and 100% customer retention rate is indicative of a successful strategy and execution. For more information on Methodics you can find their website here.
Qualcomm Rounds Out IoT Offerings
Lots of chip companies like ARM Holdings, Intel, NVIDIA and Qualcomm are spending time and effort to find a place for themselves in the IoT market because they, like I, believe in a gigantic, future market. Some companies are focusing on wearables and drones while others are looking to automotive and smart home. Qualcomm previously spent a lot of their effort on repurposing smartphone chipsets for IoT purposes, which in the short term made sense, but in the long term wasn’t really sustainable.
Qualcomm saw this challenge and I believe has addressed it with a multitude of new technologies that address almost every major IoT segment. This is partially because Qualcomm is a big enough company, like Intel, that they can focus on multiple verticals at the same time and actually grow businesses out of them. At CES 2016, Qualcomm showed off the products they have designed purpose-built for IoT. These products include a smart home reference platform, an automotive grade Snapdragon 820A, an LTE modem optimized for IoT and a Bluetooth smart SoC for IoT. They also made some announcements around Wi-Fi connectivity and self-organizing networks, which still somewhat ties into IoT.
Smart home reference platform
Qualcomm’s smart home reference platform is based on Qualcomm’s Snapdragon 212 processor which is more specifically designed to provide all of the things necessary to help someone, like Nest, Ring, or Canary build a smart home device or light hub. This reference platform is designed to allow virtually all of the ‘smart’ devices in the home to communicate with one another and to enable a single, easily manageable point of control. As stated earlier, it runs a Snapdragon 212 processor which has a 1.3 GHz quad-core ARM7 processor and Adreno 304 GPU. These specs alone are enough to allow for some decent media capabilities as well as processing things like audio, voice, and video all at the same time. It also has built-in wireless connectivity with 802.11a/b/g/n as well as Bluetooth 4.1, Bluetooth LE and NFC. These specs make it quite clear that this platform isn’t designed for the high-end and that its purpose is to satisfy the needs of the soon-to-be-mainstream smart home market. What is interesting, however, is the added support for a display and 8 MP camera, which allows smart home hub designers to run with their designs and integrate displays and cameras into their hubs if they want.
Internet of autos
In the automotive sector, Qualcomm announced the Snapdragon 820A, an automotive variant of the Snapdragon 820 smartphone processor. This processor is designed to deliver the absolute best Qualcomm performance and experience to users and is very likely why they’ve introduced the Snapragon 820A because the only other automotive chip Qualcomm had was the Snapdrgon 602A. This upgrade to the Snapdragon 820A means that automakers, like Audi who will be using the 602A in their 2017 vehicles for their MMI (Multi-Media Interface), now have access to significantly more horsepower to power the infotainment of the vehicle. Qualcomm said the Snapdragon 602A will be shipping in the A5 and Q5 models in Audi’s 2017 lineup. It appears now like NVIDIA will hold the higher models like the Q7 and A8.
The Snapdragon 820A has all of the features of the Snapdragon 820 which include the powerful Kryo CPU cores, Adreno 530 GPU and Hexagon 680 DSP. There is also a Snapdrgaon 820Am which integrates a Snapdragon X12 LTE modem, much like the consumer version of the Snapdragon 820. This part could be Qualcomm’s key to success as it enables 600 Mbps downlink and 150 Mbps uplink and is essentially designed with car manufacturers’ update cycles in mind. Because the X12 LTE modem is so far ahead of where most networks are today, car manufacturers are essentially ‘future proofing’ their wireless connectivity for the next 2-3 years. Plus, having the modem integrated into the SoC is something that most automotive manufacturers would love to have since it allows them to free up space not having to find a place for and run wires for two different chipsets. In addition to industry- leading connectivity, the 820A also has “smart” (aka cognitive) features like its Zeroth technology which allows the vehicle to identify, through computer vision, objects and potential dangers and to continually learn as it continues to be used.
The Snapdragon 820A also features driver assistance with lane departure warnings, vehicle detection and traffic sign recognition. These features are designed to get Qualcomm into the heart of the connected car rather than just powering the infotainment system. They want to control the dash and center console in addition to the infotainment system. This means more, future integration of Snapdragon capabilities in cars and more chips shipped. Qualcomm also incorporates V2X capabilities which are designed to prevent collisions with other vehicles or people through vehicle to vehicle communication or vehicle to mobile device communication.
I’m fascinated between the back and forth between Qualcomm, NVIDIA and Intel in this space.
Low power LTE for IoT
One feature missing from most wearables today is a low power, wireless solution, so one doesn’t need to have their phone to make it useful. Battery-powered, industrial IoT solutions or even drones need this same capability, too. As Qualcomm is a connectivity company, it comes as little surprise that the company announced a new LTE modem at CES 2016, the Snapdragon X5 LTE (9×07) which is designed to cover the company’s bases in the LTE connectivity area while also providing IoT connectivity. In fact, the X5 LTE is pin compatible with Qualcomm’s other IoT chipsets, the MDM9207-1 and MDM9206. The X5 LTE modem also features a tiny, integrated ARM Cortex A7 applications processor to allow for a complete solution that supports LTE connectivity up to LTE Cat 4. This is the first time Qualcomm has integrated a “true” applications processor into a modem to my knowledge as they’ve traditionally integrated modems into their applications processors. This is yet another move by Qualcomm to help keep down costs for their customers by utilizing less board space and having a smaller bill of materials. These chips are all designed to fill the connectivity needs of IoT OEMs and to allow for them to build the best possible devices at the lowest possible cost. This strategy should allow Qualcomm to be somewhat competitive with others in the space, since they are offering three different connectivity options that are all pin compatible with each other.
New “BlueTooth” SoC
Another connectivity announcement, born out of Qualcomm’s acquisition of CSR is the CSR102X family of Bluetooth 4.2 SoCs designed for ‘always-on’ Bluetooth connectivity. This chip is squarely focused on satisfying the Bluetooth needs of the lowest power wearable, home automation platforms and smart remote controls where performance and battery life are absolutely crucial. This family of Bluetooth chips is also designed to improve the Bluetooth audio capabilities of devices connected via Bluetooth for improved voice commands and audio quality. I could see a processor like this targeted at a FitBit versus and Apple Watch.
Wi-Fi SON makes sense of multiple Wi-Fi frequencies and features
Last but not least is Qualcomm’s introduction of Wi-Fi SON (Self-Organizing Networks) as a part of their suite of Wi-Fi capabilities. Wi-Fi SON borrows the SON capability from the 3GPP Release 8 LTE standard and is borrowed from Qualcomm’s own UltraSON technology designed for small cell LTE networks. These Wi-FI SON features are designed to bring the cellular experience to Wi-Fi networking by making the process of connecting and sending data much less painful than it is today. This means that the routers have self-configuring, self-managing, self-healing and self-defending capabilities thanks to the chips built into the access point.
These features are designed to make Wi-Fi more plug and play while also having autonomous QoS (quality of service) management for different types of data as well as being able to enable mesh and multi-hop network topologies with multiple access points connected together to deliver optimal coverage. The self-defending capabilities are also extremely important to prevent people from hacking into a wireless network purely by bruteforcing their way in. With learning capabilities, the Wi-Fi SON routers can adapt to the security situation and prevent unauthorized access. Companies like Linksys, ASUS, TP-Link and D-Link are already on-board with Wi-Fi SON capabilities and D-Link already won an innovation award for that capability. Qualcomm also said that they expect to have cellphone-side features that can make of Wi-Fi SON in the future as well, but didn’t give many details. Wi-Fi SON is also designed to work on not just the latest 802.11 standards, like 802.11ac, but also downwards towards N as well.
Wrapping up
Overall, Qualcomm’s announcements at CES 2016 were squarely focused on more firmly placing the company’s foot in the IoT space and gives the company a more solid foundation for when IoT starts to become commonplace. Until then, we are going to have to wait and see what products get created with all of these new and different chips and wireless capabilities. Qualcomm is establishing themselves as one of the big wireless solutions providers for IoT and enabling their customers to deliver the same kinds of IoT experiences that their smartphone customers expect to receive while also being cost-sensitive and supporting the right standards.
More from Moor Insights and Strategy
4 goals of memory resource planning in SoCs
The classical problem every MBA student studies is manufacturing resource planning (MRP II). It quickly illustrates that at the system level, good throughput is not necessarily the result of combining fast individual tasks when shared bottlenecks and order dependency are involved. Modern SoC architecture, particularly the memory subsystem, presents a similar problem. Continue reading “4 goals of memory resource planning in SoCs”
Of Steering Wheels and Buggy Whips
At the heart of automated driving is control of the steering wheel, gas and brake pedals in the car. Based on NHTSA’s recently negotiated agreement with car makers, those selling cars in the U.S. will add automatic emergency braking to their cars by 2022. So it seems that we humans are already ceding control of the brake pedal. Can the steering wheel be far behind? (Cars with automated driving will also see the gear shift removed.)
A three-way battle is emerging for control of that steering wheel in the car. NHTSA and European regulators want to keep it in the car. Google wants to remove it. Tesla wants to leave steering wheel control entirely at the discretion of the driver at his or her own risk.
I mention Tesla because the company has managed to straddle NHTSA’s and SAE’s defined levels of automated driving to the consternation of the rest of the automotive industry. But more on this in a moment.
At the core of the battle is whether or not a computer can handle the steering entirely on its own or requires the help of the driver and, if it does require assistance, how much and under what conditions and legal obligations? Google is suggesting the computer can and should handle the entire steering process without human assistance. NHTSA and SAE believe the driver should be prepared and able to steer at all times within specified guidelines. Tesla wants to leave steering decisions to the computer or the driver depending on circumstances and at the driver’s risk and discretion with no guidelines.
(Clarification: Multiple car makers are preparing Level 3 automation for use in predefined areas with predictable automation activation and de-activation. This contrasts with the ad hoc Tesla approach.)
I met with a supplier of resistive touch sensors for steering wheels this week, Guttersberg Consulting, to explore this topic. I couldn’t help but wonder if it was actually the turn of the century and I was meeting with a maker of buggy whips. Aren’t steering wheels going to become superfluous? This gentleman assured me that steering wheels will continue to be in high demand far into the future.
Supporting his contention that steering wheels will endure is the preference expressed by regulators in the U.S. and Europe – that steering wheels remain in cars. (The Vienna Convention, which applies in Europe, also requires a driver to be physically present.) This executive from Guttersberg Consulting, living in Germany and, therefore, Europe, believes consumers everywhere are still enthusiastic about driving – which helps explain the interest in steering wheels and Level 3 automated driving.
Level 3 automated driving – based on NHTSA and SAE guidelines – is a hybrid driving experience that provides for the driver standing by, ready to re-take control of the car. Level 3 requires a driver detection system and a process for determining when the driver is present and when that driver must take control with a sufficient amount of time provided for transition to human driving.
Level 3 contrasts with the approach of Tesla Motors which has no system for driver detection or driver awareness determination – though there is a driver alert when the computer discovers it can no longer proceed on its own. The lack of driver detection explains the YouTube videos with Tesla “drivers” pictured in the rearseat during vehicle operation. Tesla’s autopilot is almost entirely ad hoc and up to the driver with Tesla relieved of responsibility.
Outside of Germany, most car companies have indicated their plans to skip Level 3 because of what is seen as an insurmountable challenge of somehow implementing a safe hand-off of control from computer to human. German car companies are so far still seeking to enable a Level 3 experience since it appeals to their interest in preserving and extending the role of the human driver in vehicle control – ie. BMW’s “Ultimate driving experience.” Maybe this becomes the ultimate ASSISTED driving experience.
The question, therefore, is how long it will take to transition from a steering wheel-centric Level 2 automated driving experience to a steering wheel-optional Level 4 and whether Level 4-capable cars will continue to have steering wheels. And, further, what role will this Level 4 vehicle play? Will the car be owned and will anyone want to own this car?
My steering wheel-enhancing friend at Guttersberg is approaching automated driving from a completely different standpoint. Rather than STARTING with automated driving as the goal of the complete driving experience, his company views automated driving as a default system to protect the driver from him or herself or in the event of incapacitation or driver distraction.
Guttersberg’s technology is intended to recognize when the driver has taken control or re-taken control of the car or, even more importantly, when the driver has lost control of the car. In the event of driver distraction or a medical emergency, Gutterberg’s technology will detect the presence or absence of a hand on the wheel.
Should the driver’s hand leave the wheel due to fatigue or medical emergency, the Guttersberg-enhanced steering wheel will alert a system that will allow the car to shift automatically to an automated safe mode and call for assistance, if appropriate. The steering wheel airbag will also be there to protect the driver in the event of a crash.
A host of companies including TRW and Autoliv are focused on enhancing the steering wheel to make driving safer, while companies like Guttersberg and Neonode are focusing on using the steering wheel as the ultimate driving sensor and interface. The steering wheel of the future will detect the driver and his or her attention to the driving task.
Guttersberg’s vision of automated driving is a compelling one. Automated driving becomes the ultimate safety system – always standing by to take control when the car is in danger of a potentially catastrophic maneuver. Guttersberg’s resistive sensors, which do not interfere with steering wheel heating, also enable interfaces for accessing content and other applications.
Automated driving becomes the default driving mode in this view, rather than the primary driving mode. Looking at automated driving this way shifts the automated driving thought process away from a door-to-door Level 4 phenomenon with all of the related challenges and ownership disruption, to the ultimately safe driving experience desired by most car buyers. In such a world steering wheels are far from buggy whips. They are an essential tool for making driving safer.
Roger C. Lanctot is Associate Director in the Global Automotive Practice at Strategy Analytics. More details about Strategy Analytics can be found here: https://www.strategyanalytics.com/access-services/automotive#.VuGdXfkrKUk
Waze May Not Be So Evil After All
In contrast to the opinions in a recent article here, I think Waze is extremely beneficial to the individuals who use it, other drivers – by virtue of more efficient road usage, and the various jurisdictions that oversee roads and highways. For those not familiar with Waze, it is a smartphone app that provides navigation and route planning using real time traffic information. The major premise is that by using GPS information and user reports, Waze can assemble a more accurate picture of road conditions and hazards. By combining crowd sourced traffic and hazard information with route planning, Waze is effective at shortening commute travel time and improving safety.
Waze is really good at route planning. When it sees congestion it will direct users to other roads that can be quicker. Instead of leading to more congestion on side roads as has been suggested, my experience is that it has a bias towards highways – they are usually faster after all. Plus, if one of the alternate routes becomes overloaded, Waze will plan routes that avoid that congestion too. Waze serves as a load leveling system for roads that increases overall utilization and efficiency.
More than once, when I have encountered traffic and flagged it, immediately Waze will update the map to make the route yellow or red. Waze ranks user reports based on how long the user has been using Waze, and probably on the accuracy of their previous reports. It is not unlike a consumer credit scoring system for Waze traffic reporters. One complaint about crowd sourced traffic is that individuals might try to rig the system by falsely reporting traffic on their favorite route home. This is prevented by checking to see if their vehicle is actually moving – as opposed to parked – and by comparing that one user’s report to other vehicles in the same area.
Because Waze uses real time information, its maps and traffic info are up-to-the-minute, avoiding a major problem that traditional GPS navigation systems encounter. Waze will even provide ETA updates or route changes based on changing traffic conditions during a drive. Having Waze run on a smartphone is also good because phones are more easily updated than built-in navigation systems found in most cars. My 2005 SUV has an obsolete boat-anchor GPS system that has become unusable due to its ancient user interface, limited capability, and inability to read its outdated road data DVD. Updating it with a newer system is simply not an option. During the life of a car, its owner(s) will likely go through several generations of smart phones and app updates.
The Waze user interface is very easy to use and is not distracting. I’d probably have a harder time using a frozen in time built in navigation system. Furthermore, Waze can fine tune their app to continuously improve the ease of use and minimize driver distraction. Yes, it does display ads, but only when you are stopped.
Next comes the topic of how municipal traffic information should be shared. Contrary to the assertion that Waze is stealing the keys to the city, Waze is sharing information exactly as it should be. Cities have closure and road condition information that needs to be distributed – in any and every way that is feasible. Choosing to share this information with Waze in no way limits their ability to share it with others.
Waze too has useful information sourced from its users. Sharing this with municipalities makes sense, especially in emergencies and during unpredictable events. There does not seem to be a down side to the exchange of information when both parties, and the public stand to benefit.
Perhaps, as some argue, Waze is undermining 511 initiatives. However, 511.org openly makes their database available to app developers and even features Waze and other navigation and traffic apps on their site. The type of information that 511 systems can provide is best delivered in a frictionless manner during navigation system route planning and visually in real time on the road. Far from being a threat to 511 Waze seems to be complimentary.
Along with pot holes, objects in the road and stalled vehicles, users can report police car locations. People usually don’t bother reporting police cars that are in motion. Only the ones parked by the road are reported, so Waze is not a useful way to locate police if you are contemplating a crime. And, anyways, for that there are police radio scanners. However, for the same reason police cars are marked to begin with, these reports can help encourage drivers to slow down and drive more cautiously near a police car location. Isn’t that to goal of traffic enforcement anyway, not simply to issue tickets?
We have all seen empty highway patrol vehicles when they park near road construction projects – same idea. In fact, the Highway Patrol probably wants Waze users to report them. What’s more, the absence of a reported police car on Waze offers no assurance that you are in a free for all speeding zone.
Another previously stated comment related to the federal railway administration’s efforts to ensure that Google maps has accurate information for railway crossings on roads. I’m certain that this information is not being made exclusively available to Google. But regardless, the good news is that Waze shares Google Map information – so train crossing information will be incorporated into the Waze App. By the way, Google acquired Waze some time ago, so Waze already benefits from Google traffic info and other map features. And, as was incorrectly asserted, Google Maps is not just a smartphone app, but an extensive database used through the web and programs like Google Earth.
Waze is not some evil plot to sequester road and traffic information. Rather it is a brilliant and in many ways obviously useful service that helps optimize traffic levels. More than once it has saved me from wasting time in traffic by finding an alternative route that simply avoided congestion.