Thermal considerations have always been a concern in electronic systems but to a large extent these could be relatively well partitioned from other concerns. Within a die you analyze for mean and peak temperatures and mitigate with package heat-sinks, options to de-rate the clock, or a variety of other methods. At the system level you might rely on passive cooling or plan for forced air or even liquid cooling. These methods treat heat as more or less a bulk property to be managed. But that approach alone is breaking down in a number of modern applications, for which automotive (in ADAS and autonomy) provides good examples.
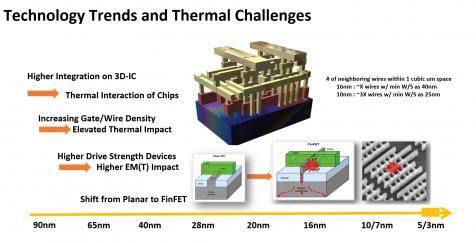
What changed? Ambient temperatures in a car (up to 150[SUP]o[/SUP]C) are a lot more stressful than mobile devices have to consider. This isn’t new but we’re now packing those mobile technologies and more into the car, with much higher safety expectations. That’s just to start. Automakers need higher levels of integration of heterogenous technologies, in part driving a trend to advanced packaging where we now have to consider not only thermal effects within a die but also between stacked die. System builders also moving much more aggressively to advanced processes because they need the performance and lower standby power. But this means gates and wires crammed closer together with more heat concentrated in smaller areas. Worse yet, FinFETS with their wrap-around gates are unable to dissipate heat as effectively as traditional planar gates.
FinFETs have higher drive strengths, which is good for performance, but into narrower interconnects which increases the risk of electromigration (EM), impacting device reliability. Local heating also accelerates EM, and it increases power consumption and risk of timing failures. Heat can cause mechanical problems. In 3D stacks, or 2/5D on interposer, also on the board, heating can lead to warping between layers (Toyota had a recent problem with cracking solder joints caused by thermal stress). None of this is acceptable in automobile safety-critical functions.
OK, you get it. We need to analyze thermal more carefully, but there’s another challenge. In product design we like to split our analysis into different domains: timing, power, thermal, EM, die-level, package-level, board-level and system-level. It’s just too hard to do it any other way, right? We do detailed analysis in one domain at a time and we handle inter-dependencies between domains using margins. But increasingly the margin approach is requiring impractical over-design. More importantly, the automakers/Tier1s are demanding more cost-effective high-reliability solutions, which can only be accomplished though co-design and optimization from the system down to the die (incidentally this is also driving closer collaboration between the semis and the OEMs/Tier1s.) Effective thermal analysis has to span all of these domains, though here I’ll just touch on thermal analysis from system to die and related mechanical analysis.
Using ANSYS products, analysis spans a wide range of technologies, from RTL power analysis and RedHawk thermal, up to computational fluid dynamics (CFD) to model cooling at the system level, and ANSYS/Mechanical to model thermal-induced warping. Many of these are multi-physics analyses, pulling together fine-grained data from multiple domains (thermal, fluid modeling, mechanical, …) to provide accurate analytics for potential hotspots, rather than the approximations inherent in a domain-by-domain approach.
ANSYS starts with profiling at RTL, these days often driven through emulation-based modeling, so you might characterize for power profiles (developed in PowerArtist) during OS boot versus 4K streaming. From this they develop block power profiles and then chip profiles based on the floorplan. RedHawk CTA then builds a chip thermal model (CTM) containing understanding of hotspots in that die. In a multi-die package these analyses can be combined to provide a package-level thermal analysis, combined with a mechanical analysis of stress (and potential warping) in that configuration.
Up at the system level, thermal models for each of the components (chips, voltage regulators, sensors, …) are combined in an Icepak CFD analysis to assess steady state and transient thermal profiles, including whatever passive or active cooling may be provided. Naturally this analysis is iterative; you model system-level thermal profiles and take this back to the die for refined modeling. That gives you improved data on EM and other risks across the die, to which you can respond with appropriate design optimizations. Which in turn should provide a more accurate handle on thermal-related failure rates across the system. I don’t know if anyone in the automotive value chain is looking at this yet but based on what I’ve heard about rising expectations in ISO 26262, I wouldn’t be surprised to see this kind of analysis become a requirement at some point.
You can watch the recorded webinar (delivered by Karthik Srinivasan, Sr. Corporate AE Manager in the Semiconductor BU at ANSYS) HERE. He covers a lot more detail, including local thermal effects and doing power/thermal loop simulations using SIwave and Icepak at the system level. There is also some interesting discussion on where these methods are important beyond automotive. Well worth watching.