
I spoke with Steve Pateras of Synopsys last week to better understand what was happening with their Silicon Lifecycle Management vision, and I was reminded of a Forbes article from last year: Never Heard of Silicon Lifecycle Management? Join the Club. At least two major EDA vendors are now using the relatively new acronym SLM, and Synopsys defines it this way:
Silicon Lifecycle Management (SLM) is a relatively new process associated with the monitoring, analysis and optimization of semiconductor devices as they are designed, manufactured, tested and deployed in end user systems.
I had followed Moortec for a few years, and knew that Synopsys acquired this company for their embedded PVT sensors in November 2020. The second part of SLM is then to gather and analyze silicon data throughout the entire lifespan, so that even when the chips are running in a system you can analyze and even optimize the operation of your system.
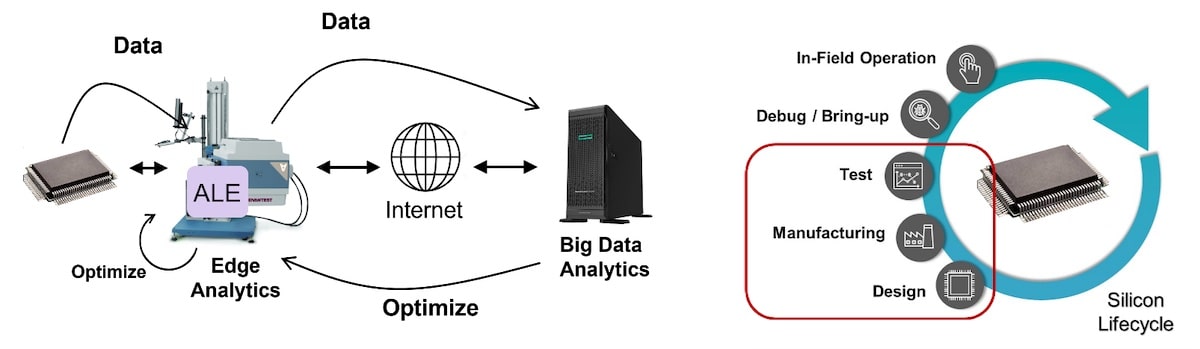
Another strategic acquisition that Synopsys made to start building up its SLM vision was Qualtera back in June 2020, and they provide big data analytics for semiconductor test and manufacturing. The early tools in SLM are well-known to IC design and test engineers, because they include DFT and ATPG. The later tools in SLM are the analytics and in-field optimization. This is precisely where the latest acquisition of Concertio comes in, because they provide AI-based optimization of a running system. Here’s a graphical flow of the SLM vision, so that you can see all of the areas that it applies to:
Specific IP and EDA tools included within SLM, include:
- DesignWare PVT monitors
- Fusion Design Platform – placement of PVT monitors
- SiliconDash – data analytics for semiconductor manufacturing
- YieldExplorer – design centric yield management
- SiliconMax high-speed access IP, TestMAX Adaptive Learning Engine
For in-field operations, the idea is to observer the software running on the system, analyze it, then tune the system. One example that comes to mind is how a vertically integrated company like Apple have optimized how their MacBook Pro laptop has it’s battery charged to optimize it’s lifespan, because they know how often each app is run, what the power and RAM use for an app is, and can then control clock speeds based on workloads, control the RPM rate of fans and ultimately extend the lifetime of the battery.
Concertio is being used by systems companies to monitor work loads, optimize the compute resources through firmware settings, OS setting and even app settings, or Kubernetes settings on cloud apps. They use reinforcement learning in their AI approach for continuous, realtime optimizations. Users of Concertio technology are reporting improvements in the range of 5-15%.
From a marketing perspective, the SLM tools fall under the platform name SiliconMAX. I learned that the Concertio company was incorporated in New York, while their R&D team is in Israel, and they serve multiple markets, like: Cloud, on-premise compute centers, silicon design, high frequency trading. Synopsys has a good record of treating acquired companies quite well, and you can still visit the concertio.com web site, as they support customers and grow their business.
I could see some similarities in the approaches between the DSO.ai technology and what Concertio offers, as they both use reinforcement learning, so it will be interesting to see what kind of synergy there may be in the future. Stay tuned for more news as Synopsys integrates Concertio technology so that PVT analytics are fed into the system optimization loop, keeping SoCs running reliably.
Related Blogs
- Synopsys Enhances Chips and Systems with New Silicon Lifecycle Management Platform
- AI and ML for Sanity Regressions
- Using Machine Learning to Improve EDA Tool Flow Results
- Less Haste More Speed – The Importance of Test Engineers







{kind=link}