Thermal modeling has become a hot topic for designers of today’s high-speed circuits and complex packages. This has led to the adoption of better and more sophisticated thermal modeling tools and flows as exemplified in this presentation by Micron at the IDEAS Digital Forum. The presentation is titled “Thermal Aware Memory Controller Design with Chip Package System Simulation” and covers the latest developments in both power modeling and thermal modeling by the Controller design team at Micron.
The first presenter is Shiva Shankar Padakanti, a senior physical design manager at Micron with over 17 years of experience in backend design and more than 33 tape-outs down to 7nm. Shiva introduces the two major thermal issues faced by his team: (a.) avoiding overly pessimistic thermal limits that degrade a chip’s performance, and (b.) avoiding thermal runaway – a reliability issue where local hotspots cause increased device leakage, which increases the temperature yet further.
Shiva sets the stage by discussing their traditional thermal analysis flow that assumed a uniform temperature across the entire chip based on total power and relied on simple power/temperature limits with a large safety margin. This constrained power signoff to use un-realistically pessimistic temperature limits because the analysis under-reported the true maximum temperature. This could lead to compromise in the design’s specification and significant loss in chip performance due to over-design. The first attempt to improve their analysis capability was to analyze the power on a block-by-block basis instead of full-chip. This gave a more realistic non-uniform temperature distribution but was still unable to account for temperature-dependent leakage power.
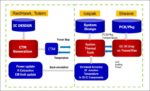
Working with Ansys, Micron developed a new analysis flow that uses the Chip Thermal Model (CTM) technology augmented with the APL Leakage Model. A CTM cuts each layer in the chip into a fine grid and then describes the power output of each grid square as a function of the temperature. The APL Leakage files capture how device leakage varies with temperature. These models are generated by Ansys RedHawk™ or Ansys Totem™ power integrity signoff and gives a much more accurate and fine-grained power model. This was then handed off to the Thermal team to enable their package and system thermal analysis.
Fig.1 Thermal analysis flow using Chip Thermal Models (CTM) generated by Ansys RedHawk or Ansys Totem power integrity signoff tools, and then used for package and system thermal analysis by Ansys Icepak.
The advantage of the CTM technology is that it accurately predicts the location of thermal hotpots and, in this test case, predicted a temperature 12% higher than the simpler block-based approach (see Fig.2). This higher temperature results from the accurate modeling of temperature-dependent leakage which was not considered in the block-based or traditional flows.
Fig.2 Shows a comparison of the temperature profile using the simpler block-based thermal modeling approach against the more accurate Chip Thermal Model that relies on a per-layer gridded model. The CTM technology accurately identifies the hotspot locations and predicts a 12% higher temperature based on temperature-dependent leakage
The second part of the presentation is narrated by Ravi Kumar, senior principal engineer at Micron with over 9 years’ experience in thermal management of electronics. Ravi starts by pointing out that chip, package, and system analyses are each at a different scale – from microns to centimeters and thus require a range of simulation technologies to span this range. Also, simulating a complete stack as shown in Fig.3 is very computationally expensive for each temperature point, often limiting the scope of thermal analysis.
Fig.3 Cross section of the complete chip-package-system stack for the Micron controller under thermal analysis, including the PCB substrate and the external heat sink. The cooling airflow over the heatsink is modeled by Icepak using Ansys’ computational fluid dynamics technology.
However, by using the CTM modeling approach, Ravi’s team was able to speed up the thermal simulation time by 90% due to the higher efficiency and faster convergence of the CTM approach. The final operating temperature depends, of course, on its power output. But the power output is also temperature dependent. Icepak executes internal iterations using the CTM to arrive at a stable operating temperature. In this test case, the heat sink was designed to radiate an estimated 50W, but the system actually ended up generating closer to 60W. Failure to anticipate the real heat flow can heat stress the package and impact the performance and reliability of the entire system.
A final benefit highlighted by the Micron team was the ability to optimize the placement of thermal sensors on the chip. The traditional techniques had not accurately placed the sensors at the true maximum hotspots and under-measured the hotspot temperature by 8.1°C. The new CTM-based approach optimized their placement and reduced the risk of thermal runaway.
Shiva concluded the presentation by outlining future projects by his team to consider thermal-aware electromigration analysis, and the mechanical warpage of package and PCB due to thermal gradients.
You can view the entire Micron presentation on-demand at Ansys IDEAS Digital Forum under the Electrothermal Analysis track. Registration is free.
Also Read
Ansys CEO Ajei Gopal’s Keynote on 3D-IC at Samsung SAFE Forum
Ansys to Present Multiphysics Cloud Enablement with Microsoft Azure at DAC