Last-level cache seemed to me like one of those, yeah I get it, but sort of obscure technical corners that only uber-geek cache specialists would care about. Then I stumbled on an AnandTech review on the iPhone 11 Pro and Max and started to understand that this contributes to more than just engineering satisfaction.
Caching
A brief refresh on caching. This is a method used in processors and in more general SoCs to minimize the need to go off-chip to read or write memory. Off-chip accesses are slow and burn a lot of power. If you already have the data around in on-chip memory – a cache – you should read or write that memory instead. This is a frequency-of-access play. You can’t get rid of the off-chip memory, but you can reduce the number of times you have to go there, speeding up net performance and reducing net power consumption.
It’s common to have a hierarchy of caches. These start with small caches really close to a CPU or IP for very fast access, then bigger caches a bit further away (but still on chip) to serve a bigger demand though not quite as fast.
The last level provides caching for the whole chip, bigger still, a little slower still and the last line of defense before you have to go to main memory.
In a modern SoC with CPUs and GPUs and AI accelerators and who knows what else, this cache has to serve a lot of different masters. Which is important because how effectively a cache does its job is very dependent on the application, extra tricky when the last level cache has to serve a bunch of different applications.
Pointer-chasing
There are a number of pointer-based programming data structures, especially popular in data analytics and machine learning kernels, which can particularly stress caching. These include linked-lists, trees and graphs. In all these cases to trace through a structure you have to chase through pointers to work through a list or a path through a tree or graph. Because this is pointer-based data there’s no guarantee it will all fall close together in memory, which makes it harder to get all of it into a cache limited to caching some fixed number of memory blocks. Chasing through those pointers is most likely to stress the ability of a cache to keep the relevant data local without needing to go out to main memory.
The iPhone 11 review (more exactly the Apple 13 Thunder SoC review)
So AnandTech ran a pretty detailed set of pointer-chasing tests on the A13 and compared these with results for the A12 Tempest (and variously some other phones in some graphs). In most of the charts they compare latency (speed of access) versus test depth (how many pointers are chased).
They show a latency versus test depth curve for A12 and A13 with identical or improved latencies in the first and second level caches but consistently better latency in the last level cache (which they call the system level cache – SLC). In the upper right of the graph, A13 is slower than A12 but that’s for off-chip memory accesses. SLC access are one level below and left of those.
AnandTech concludes that Apple is very effectively using that last level cache to get better overall system performance. And they note later that the A13 SLC maintains bandwidth versus test depth much better than in the A12. All adding up to better system performance across many applications. If it’s that important to Apple, I’d have to guess is should be just as important to everyone else.
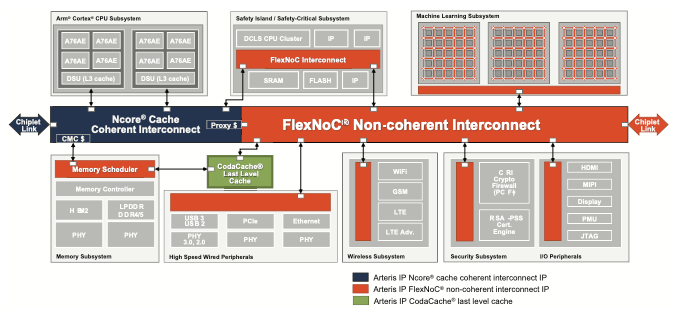
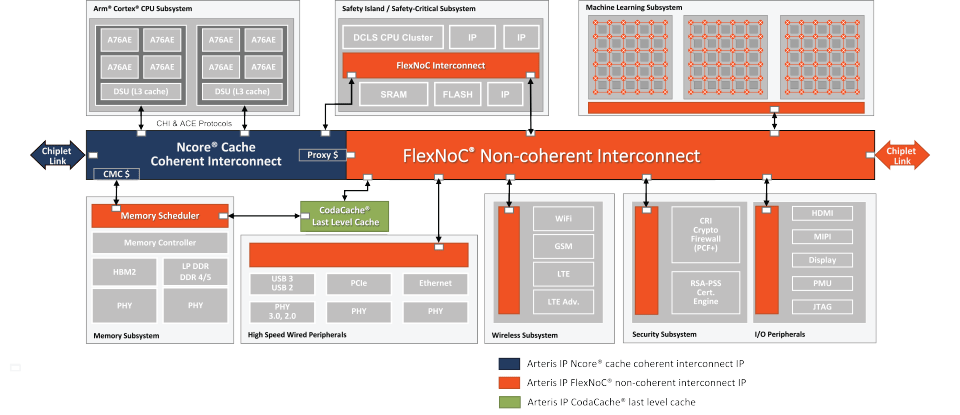
Arteris IP CodaCache
Caching and interconnect are very tightly tied together. When multiple IPs each have their own local caches, those must be kept coherent. When an attempt to find a piece of memory in a local cache fails (a cache miss), the request must be passed onto the next level and so on until if the last level cache can’t help, it has to go out to main memory. A big drag on latency and power in those cases.
Arteris has built a general-purpose highly-configurable last level cache, their CodaCache, for such applications. They’ve had this for a little while. What’s new about this implementation is that it now meets ISO 26262 functional safety compliance, in line with Arteris IP general directions in safety. You can learn more about CodaCache HERE.
Also Read:
Trends in AI and Safety for Cars
Autonomous Driving Still Terra Incognita
Evolving Landscape of Self-Driving Safety Standards
Share this post via:



Comments
One Reply to “That Last Level Cache is Pretty Important”
You must register or log in to view/post comments.