The use of safety-centric logic design techniques for automotive applications is now widely appreciated, but did you know that similar methods are gaining traction in the design of enterprise-level SSD controllers? In the never-ending optimization of datacenters, a lot attention is being paid to smart storage, offloading storage-related computation from servers to those storage systems. Together with rapid growth in SSD-based storage at the expense of HD-based storage (at least in some applications), this inevitably creates lots of new and exciting challenges. One consequence is that the controllers for SSD systems are now becoming some of the biggest and baddest in the SoC complexity hierarchy.
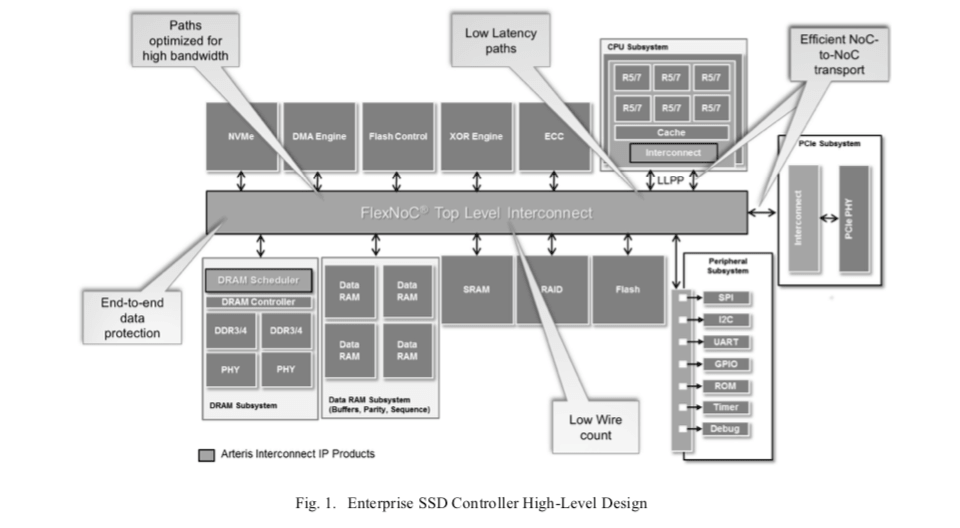
Why are these devices so complex? Certainly they have to offer huge bandwidth at very low latency (performance is a big plus for SSD) in architectures where a mother-chip controller may be managing multiple daughter controllers each managing a bank of SSDs. Datacenters have high cooling costs so expect low power (a big appeal for SSDs). And they also expect high reliability for enterprise applications; no-one would want to use a datacenter that loses or corrupts data. That last point is where the connection to safety-related design techniques comes up.
Then there’s lots of house-keeping, finding and isolation bad locations, sampling to predict and proactively swap out locations likely to fail, also needing to put aside un-erased blocks to be erased during quiet periods (since erasing is a slow process). All of this is known as garbage collection. On top of these functions, the controller can manage encryption, compression and lots of other offloadable features that don’t need to be managed by the server, for example SQL operations. At least that’s one viewpoint; there seem to be differing opinions on the pros and cons of offloading, see the link above.
But there’s no debate on the need for reliability. JEDEC defines a metric called Unrecoverable Bit Error Ratio (UBER) which is the number of data errors divided by the number of bits read. Consumer-class SSDs allow for slightly less reliability, where occasional re-reads may not be too intrusive. But enterprises expect ultra-high reliability and a higher UBER, so more must be done in controllers to ensure this reliability. A lot of this is in proprietary hardware and software design to manage system aspects of reliability but some must also be basic functional reliability, demanding support in design methodologies and tools.
The need for reliability comes from the same concerns that we see in vehicles – cosmic ray events, EMI events and similar problems. These devices are all built in advanced processes and are just as vulnerable to these classes of problems as automotive devices. Which in turn means you want parity-checking, ECC for memories, duplication (or even triplication) and lockstep operation, all the design tricks you use to mitigate potential functional safety problems for ISO 26262.
Curiously, when Arteris IP first built the Resilience Package for their FlexNoC interconnect IP, their first customers were enterprise SSD builders, originally small guys, now consolidated into companies like WD, Seagate, Samsung, Toshiba and Intel. Over time, Arteris IP started to get more uptake among companies building for automotive applications thanks to growing adoption of the ISO 26262 standard. But SSD continues to be a driver; they’re now starting to see adoption in China for this kind of application.
In a lot of cases in an SoC design, safety mechanisms must be managed by the integrator, but in the interconnect, it is reasonable to expect that the IP generator should handle these reliability functions for you. This is what the FlexNoC Resilience package does. It also provides a safety controller to manage faults and a BIST module to continually monitor test data protection hardware during quiet periods. The Resilience package also natively supports the ECC and parity protection schemes used by the Cortex-R5 and R7 cores, unsurprisingly since these are the cores most commonly used in SSD controllers.
I should add that this support isn’t the only reason SSD controller designers use the Arteris IP interconnect solutions. Remember that these devices are some of the biggest, baddest SoCs around? That means the SoC-level connectivity at minimum has to be through NoC interconnect. Traditional crossbar fabrics would be simply too expensive in performance and area; only the NoC approach can guarantee the QoS demanded by these systems. Even large subsystems will depend on NoC fabrics for the same reason.
Kurt Shuler (VP Marketing at Arteris IP) tells me these approaches are now trickling down to consumer-grade SSD. I may only be a consumer, but I don’t like waiting for slow disk operations either. Can’t come too soon for me. You can learn more about this topic HERE.
Share this post via:



Comments
There are no comments yet.
You must register or log in to view/post comments.