The Cadence Tensilica DNA100 DSP IP core is not a one-size-fits-all device. But it’s highly modular in order to support AI processing at the edge, delivering from 0.5 TMAC for on-device IoT up to 10s or 100 TMACs to support autonomous vehicle (ADAS). If you remember the first talks about IoT and Cloud, a couple of years ago, the IoT device was supposed to collect data at the edge and send it to the cloud through wireless network or internet where the data was processed. And the way back to send the processing result to the edge.
But this model appeared to be a waste of energy (sending data back and forth through networks has high power consumption cost) and a lack of privacy (especially for consumer application). But the worse was probably the impact on latency: can we safely rely on autonomous car if ADAS data processing is dependant to a cloud access. On top of adding unacceptable latency, the data travel through network is clearly dependant of the existence of such network (what about rural areas?).
Hopefully, the industry came back to a reasonable solution, data processing at the edge device! Supporting processing at the edge is not challenges-free: the SoC located at the edge must be as low-cost as possible, it must be performance-efficient to keep power consumption low. Even if a standard GPU could do the job, a SoC integrating DSP IP is the best solution to meet these constraints…
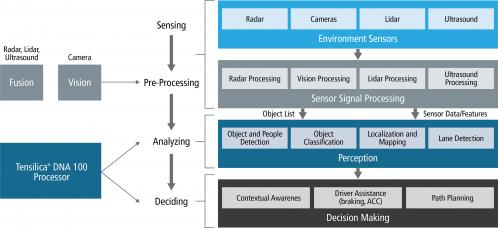
Cadence is launching Tensilica DNA 100 to support on-device AI processing in multiple applications. In fact, AI processing is penetrating in many market segments, in multiple applications. In mobile, the consumer expects to experience face detection and people recognition, at video capture rates. On-device AI will support object detection, people recognition, gesture recognition and eye tracking in AR/VR headsets. Surveillance cameras will need on-device AI for family or stranger recognition and anomaly detection. In automotive, for ADAS and AV, on-device AI will be used to recognize pedestrians, cars, signs, lanes, driver alertness, etc.
But these various markets have different performance requirements for on-device AI inferencing! For IoT, 0.5 TMAC is expected to be enough, when for mobile, the performance range is in the 0.5 to 2TMACs. AR/VR, with 1 to 4TMACs range is slightly higher, when for smart surveillance the need is in the 2 to 10 TMACs. Autonomous vehicle is clearly the most demanding application, as on-device AI inferencing requires from several 10s to 100 TMACs. The solution is to build a DSP core, the DNA 100 processor, which can be implemented as an array of cores, from 1 to a number as high as authorized by the area and power target…
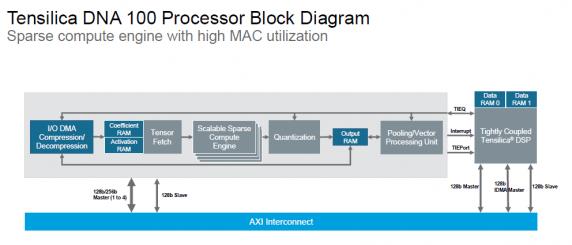
If you look at the DNA 100 block diagram (above picture), you see that the core provides:
Bandwidth reduction, thanks to weight and activation compression,
Compute reduction as the MAC process non-zero operations only,
Efficient convolution through high MAC occupancy rate,
Pooling, Sigmoid, tanh and Eltwise add or sub for non-convolution layers.
Moreover, as the DNA 100 is programmable, it makes the SoC future proof and also extensible, by adding custom layers.
Cadence claims the Tensilica DNA 100 processor performance to be up to 4.7 time better than the competition (CEVA DSP?) thanks to sparse compute and high MAC utilization. The benchmark has been made on ResNet50, the processor running at 1GHz and processing 2550 frames per second. Tensilica DNA 100 processor and competition are both 4TMAC physical array configuration, and DNA 100 processor numbers are with network pruning, assuming 35% sparse weights and 60% sparse activation.
A figure is becoming more and more important, as the industry realize that performance can’t be the only criteria: power efficiency. Cadence is claiming to be 2.3 X better than the competition, in term of TMACs per Watt, for a DNA 100 processor with network pruning and 4TMAC configuration in 16nm (Tensilica DNA 100 delivers 3.4 TMAC per Watt, when the competition only reach 1.5 TMAC/W.
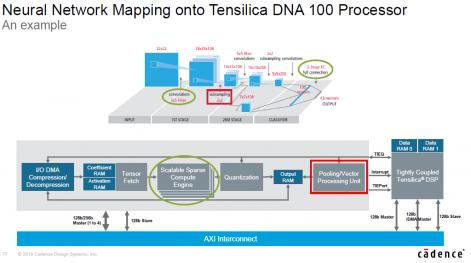
The above figure describe neural network mapping onto DNA 100 processor. This direct us to look at software support, Cadence proposing Tensilica Neural Network Compiler and supporting Android Neural Network App. Dated September 13 2018, this annoucement from Facebook about GLOW: a community-driven approach to AI infrastructure: “Today we are annoucing the next steps in Facebook’s efforts to build a hardware ecosystem for machine learning through partner support of the Glow compiler. We’re pleased to announce that Cadence, Esperanto, Intel, Marvell, and Qualcom Technologies inc. have commited to supporting Glow in future silicon products”
According with Cadence, “Integrating Facebook’s Glow, an open-source machine learning compiler based on LLVM (Low Level Virtual Machine), to enable a modular, robust and easily extensible approach”.
Modular, robust and extensible, the DNA 100 processor is well positioned to support AI on-device inference, from IoT to autonomous car…
The following link to get more information about the DNA 100 DSPs
ByEric Esteve fromIPnest
Share this post via:



Comments
There are no comments yet.
You must register or log in to view/post comments.