

 Pipelining exploits parallelism of sub-processes with intent to achieve a performance gain that otherwise is not possible. A design technique initially embraced at the CPU micro-architectural level, it is achieved by overlapping the execution of previously segregated processor instructions –commonly referred as stages or segments. Pipelining for timing fixes has become mainstream option in design implementation space, especially when designers had exhausted other timing closure means at the physical design step (such as optimizing wire utilization or resource sharing in the logic cone).
Pipelining exploits parallelism of sub-processes with intent to achieve a performance gain that otherwise is not possible. A design technique initially embraced at the CPU micro-architectural level, it is achieved by overlapping the execution of previously segregated processor instructions –commonly referred as stages or segments. Pipelining for timing fixes has become mainstream option in design implementation space, especially when designers had exhausted other timing closure means at the physical design step (such as optimizing wire utilization or resource sharing in the logic cone).
Anatomy of pipelining
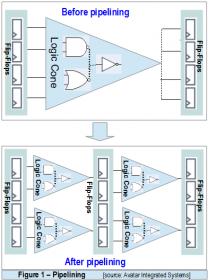 Pipeline involves the use of flip-flop and repeater insertion –although some designers tend to focus on flip-flop insertion part, as it is assumed that the implementation tools are to perform repeater insertion by default (such as during synthesis stage or placement/route optimization).
Pipeline involves the use of flip-flop and repeater insertion –although some designers tend to focus on flip-flop insertion part, as it is assumed that the implementation tools are to perform repeater insertion by default (such as during synthesis stage or placement/route optimization).
Ideal pipelining should consist of equal stage latency across the pipeline with no resource sharing between any two stages. The design clock cycle is determined by the time required for the slowest pipe stage. Pipelining does not reduce the time for individual instruction execution. Instead, it increases instruction throughput or bandwidth, which can be characterized by how frequent an instruction exits the pipeline.
Pipelining can be applied on either the datapath or control signals and requires potential hazards monitoring. Ideally speaking, pipelining should be done closer to the micro-architectural step as adding flip-flops further down the design realization translates to perturbing many design entities and iterating through the long implementation flow.
SoC Design and Pipelining Challenges
With the recent emerging applications such as AI accelerators, IoT, automotive and 5G, two top challenges encountered by the SoC design teams are scalability and heterogeneity. The former demands an increased latency in the design, while the later requires a seamless integration of interfaces and models.
In the context of timing closure, there are two entry points for injecting pipelining to manage latency. The first is done post static timing analysis (STA). By identifying large negative slack margin among logic stages, designers could provide concrete data points to the architecture team (or RTL owner) for pipelining. This reactive step may be costly if excessively done as implied iteration to the RTL-change translates to resetting the design build.
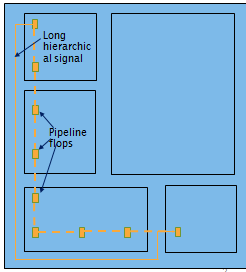
On the other hand, pipelining can be also performed early on the RTL codes, during micro-architectural inception. While doing it at this stage provides ample flexibility, code architect tends to be conservative due to lack of an accurate delay estimation and being critically aware of increased flop usage impact to the overall design PPA. Hence, some designers have adopted a semi-manual method. It involves rule-of-thumb formulas combined with some SPICE simulations and spreadsheet tracking to arrive at pipeline budgeting plus an involved placement constraints to manage its implementation. This approach is tedious, iterative and prone to over-design as it may include guard-banding to cover backend optimization inefficiencies such as detours due to placement congestion or wire resource shortages.
Avatars and automatic pipelining
At DAC 2018 designer/IP track poster session, Avatar and eSilicon showcased the outcome of their collaboration in achieving successful pipelining through the use of automatic stage-flop insertion performed by Avatar’s Apogee. Avatar Apogee is a complete floor-planning tool that enables fast analysis of design hierarchy and early floorplanning exploration. It shares common placement, routing, and timing engines with Aprisa, the block level, complete placement and route tool (please refer to my earlier blog for other discussion on these tools). Based on its customer feedback, Avatar has introduced in its 18.1 release an automatic pipeline flip-flop insertion feature. This feature automatically adds stage flops on feedthrough nets during floorplanning stage using Avatar’s Apogee new command insert_stage_flop.
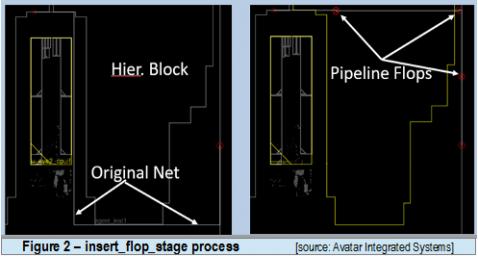
Delving further into the feature, first the long top level nets are routed by Virtual Flat Global Router by taking into account any existing congestions, blockages and macros inside the hierarchical partitions. Next, feedthroughs are assigned to the appropriate partitions and stage flops are added based on user specification that includes distance or flop count.
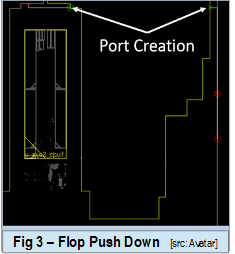
Similar to the mainstream method of pushing buffer into the hierarchy, after its addition the pipeline flops will be pushed into its hierarchical partition with the push_cell command. Subsequently, the module level netlist are automatically updated with the new hierarchical cell instance and the corresponding port gets created at this level as illustrated in Figure 3.
Results and Comparison
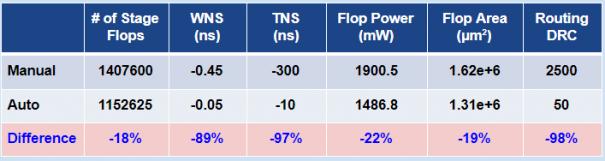
Using a large Mobile SoC design as a test case and Apogee’s automatic approach, the design was implemented and routed. The tabulated results show that there were 18% fewer stage flops needed and a 22% saving in flip-flop power with minimal DRC and timing violation (significant reduction in both TNS and WNS slacks).
The total process takes about 2 hours to auto-insert as compared to 3 weeks of manual efforts and multiple iterations to reach to the final flop count. On top of that, timing and routability were challenging with the manual approach. With Apogee, timing and congestion aware automatic placement ensure both routability and timing convergence of the design.
In summary, designers can use Apogee’s new automatic stage flop insertion feature to reduce iterations and also get better stage flop count leading to lower sequential power. The flow also supports netlist update and reports that simplifies downstream formal verification process. According to Avatar Integrated Systems, it plans to expand the capability to auto insert or delete pipeline flops at the block-level placement optimization step in Aprisa –to further improve QoR at block level.
For more details on Avatar’s Apogee please check HERE and Aprisa HERE.
Share this post via:



Musk’s Orbital Compute Vision: TERAFAB and the End of the Terrestrial Data Center