As Moore’s law keeps going, semiconductor design density on a chip keeps increasing. The real concern today is that the shrinkage in technology node has rendered the small wire geometry and gate oxide thickness (although fine in all other perspectives) extremely vulnerable to ESD (Electrostatic Discharge) effects. More than 1/3[SUP]rd[/SUP] of chip failures happen due to ESD. An IC can be exposed to ESD either from transfer of charge from external sources such as human interaction (tested by HBM, i.e. Human Body Model) and machine handling (tested by MM, i.e. Machine Model) or from internal built up of charge leaving through the package (tested by CDM, i.e. Charged Device Model). While I/O interface is most vulnerable to ESD, entire internal circuit of IC in under risk. Major damages such as gate oxide breakdown can lead to immediate failure whereas wires and vias can wear out over time.
It’s important and essential to protect the circuitry inside an IC from dielectric breakdown. Typically clamp circuits are placed at the I/O and P/G pads which can handle large transient current, provide efficient discharge path to ESD current and prevent any pin voltage from exceeding the oxide breakdown voltage.
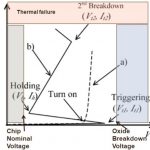
In the I-V characteristic of a typical ESD protection circuit, the dotted line curve represents the response of a turn-on device and the solid line curve represents the snap-back characteristic of a NMOS ESD device. It’s important to note that with technology migration the oxide breakdown voltage continues to move towards left while the thermal failure limit continues to move down, thus imposing severe constraint on the protection (clamp) circuit to operate in that compressed region.
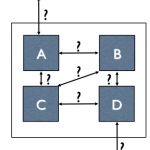
With increasing design size and complexity at lower nodes, design of ESD protection circuit is becoming increasingly complex requiring planning and verification at full chip level for all P/G nets along with ESD clamp cells and the package. The pin-to-pin paths that do not meet the defined limits should be highlighted and connectivity or routing issues must be identified with accurate resistance or impedance calculations. Current density in wires from any ESD event must be accurately estimated to ensure that the wires will not fail from such high levels of current flow.
Apache’sPathFinder provides a robust comprehensive planning and verification for ESD at full chip level which ensures that connectivity between any two pins meets design guidelines. It performs connectivity analysis for HBM, MM and CDM discharge events and predicts the current density in all wires and vias. By leveraging Apache’s RedHawk (for digital designs) and Totem (for analog designs) tools, PathFinder provides unprecedented capacity and performance for simulating large SoCs and custom designs.
During HBM or MM check, PathFinder estimates the effective resistance between any two pins in the circuit by traversing the network through one or more clamp cells placed between these pins. This is done very accurately by taking into account the clamps which pass the loop resistance threshold between two pins and can effectively provide discharge pathway; parallel R is considered between the two pins.
In case of CDM check, PathFinder calculates the resistance of the path between any device to VSS or VDD to device and also loop resistance between device VDD pin to clamp cell VDD pin, clamp cell VSS pin to device VSS pin and the resistance of clamp cell itself.
Current Density Checks are very important to save wires and vias from electro migration. PathFinder identifies clamp cells between pin pairs that are effective in conducting current and then calculates the current through the wires and vias connected to these pins or pads by injecting the current into the pads as per ESD standard definition. In then highlights the wires and vias that fail the current density limits prescribed by the technology process.
[Textual and Graphical reporting of issues – VDD route from a logic cell to a clamp cell fails defined resistance limit]
PathFinder reports the analysis results in text as well as graphical form. It highlights weak areas and resistance bottlenecks in the design and helps designers in fixing those without leaving PathFinder environment. An interactive ‘what-if’ analysis can be carried out before committing to layout. There is a whitepaperon Apache website which provides great level of details about ESD and the solution for full-chip ESD integrity analysis, verification and fixes. After reading this paper, I could gain more insight into ESD phenomenon which I did not have earlier. Interesting read!!
More Articles by Pawan Fangaria…..
lang: en_US