You are currently viewing SemiWiki as a guest which gives you limited access to the site. To view blog comments and experience other SemiWiki features you must be a registered member. Registration is fast, simple, and absolutely free so please, join our community today!
The growing demand for high-performance AI applications continues to drive innovation in CPU architecture design. As machine learning workloads, particularly convolutional neural networks (CNNs), become more computationally intensive, architects face the challenge of delivering performance improvements while maintaining efficiency and flexibility. Our upcoming webinar unveils a cutting-edge solution—a novel architecture that introduces advanced matrix extensions and custom quantization instructions tailored for RISC-V CPUs, setting a new benchmark for CNN acceleration.
Breaking New Ground with Scalable and Portable Design
At the heart of this innovation lies the development of scalable, VLEN-agnostic matrix multiplication/accumulation instructions. These instructions are carefully designed to maintain consistent performance across varying vector lengths, ensuring portability across different hardware configurations. By targeting both computational capacity and memory efficiency, the architecture achieves significant improvements in compute intensity while reducing memory bandwidth demands.
This scalability makes it an ideal solution for hardware vendors and system architects looking to optimize their CNN workloads without being locked into specific hardware constraints. Whether you are working with smaller, embedded systems or high-performance data center environments, this design ensures robust and adaptable performance gains.
Advanced Memory Management and Efficiency Enhancements
To further elevate performance, the architecture introduces a 2D load/store unit (LSU) that optimizes matrix tiling. This innovation significantly reduces memory access overhead by efficiently handling matrix data during computations. Additionally, Zero-Overhead Boundary handling ensures minimal user configuration cycles, simplifying the process for developers while maximizing resource utilization.
These advancements collectively deliver smoother and faster CNN processing, enhancing both usability and computational efficiency. This improved memory management directly contributes to the architecture’s superior compute intensity metrics, which reach up to an impressive 9.6 for VLEN 512 configurations.
Accelerating CNNs with New Quantization Instructions
A key highlight of this architecture is the introduction of a custom quantization instruction, designed to further enhance CNN computational speed and efficiency. This instruction streamlines data processing in quantized neural networks, reducing latency and power consumption while maintaining accuracy. The result is a marked improvement in CNN performance, with acceleration demonstrated in both GeMM and CNN-specific workloads.
Preliminary results reveal that kernel loop MAC utilization exceeds 75%, a testament to the architecture’s capability to maximize processing power and efficiency. These metrics are bolstered by sophisticated software unrolling techniques, which optimize data flow and computation patterns to push performance even further.
Join Us to Explore the Future of RISC-V AI Performance
This breakthrough architecture showcases the vast potential of RISC-V CPUs in tackling today’s AI challenges. By integrating novel matrix extensions, custom instructions, and advanced memory management strategies, it delivers a future-ready platform for CNN acceleration.
Whether you’re a hardware designer, software developer, or AI engineer, this webinar offers invaluable insights into how you can leverage this new architecture to revolutionize your CNN applications. Don’t miss this opportunity to stay ahead of the curve in AI processing innovation.
After 16 years effort starting from scratch, Andes Technology Corporation is now a leading embedded processor intellectual property supplier in the world. We devote ourselves in developing high-performance/low-power 32/64 bit processors and their associated SoC platforms to serve the rapidly growing embedded system applications worldwide.
As RISC-V gains traction in the global semiconductor industry, developers are exploring fully open-source approaches to processor design. XiangShan, a high-performance RISC-V CPU project, combined with the Mulan Permissive License v2 (Mulan PSL v2), represents a community-driven, transparent alternative to proprietary chip development models. Unlike traditional IP licensing models, where companies purchase pre-configured processor cores, XiangShan allows full access to RTL (register-transfer level) source code, enabling deep hardware customization. With the support of MinJie, an agile open-source development platform, and UnityChip, an open-source verification framework, XiangShan provides a flexible and scalable development path for startups, research institutions, and semiconductor companies looking to build custom RISC-V chips.
This article explores the design process of developing a RISC-V chip using XiangShan, highlighting the advantages, challenges, and impact of an open-source development approach.
Key Design Elements of the Chip
The latest generation of XiangShan, known as Kunminghu (Gen3), is designed to deliver high-performance computing capabilities, making it a viable alternative to commercial RISC-V processors. It features out-of-order execution with a high-performance pipeline, support for RISC-V vector extension for AI and HPC acceleration, and scalability for different process nodes, including 7nm, 12nm, and 28nm fabrication.
To streamline the design and development process, XiangShan utilizes MinJie, an open-source development platform that integrates Chisel-based RTL development, simulation and performance profiling tools, and agile methodologies, reducing iteration time for hardware design. One of the biggest challenges in open-source hardware is ensuring reliability and security. UnityChip provides functional verification to detect architectural bugs early, security verification to test speculative execution vulnerabilities (such as Spectre-like attacks), and crowdsourced debugging tools, enabling contributions from universities and independent researchers. Together, these elements form a comprehensive, open-source RISC-V development ecosystem, fostering innovation while maintaining full transparency.
Chisel (Constructing Hardware in a Scala Embedded Language) is a high-level hardware description language (HDL) that simplifies register-transfer level (RTL) design by enabling more modular, reusable, and parameterized hardware development compared to traditional HDLs like Verilog and VHDL.
In Chisel-based RTL development, designers use Scala-based programming constructs to define digital circuits, allowing for faster prototyping, better code reusability, and easier debugging. It integrates with simulation and performance profiling tools, which help validate design correctness, optimize computational efficiency, and analyze power consumption. These tools enable pre-silicon verification, ensuring that a processor meets performance targets before fabrication.
For RISC-V processor development, Chisel-based tools streamline core design, integration of vector extension, and instruction scheduling, making them particularly useful for projects like XiangShan, which require high customization and an agile development cycle.
Development Process and Challenges
The development of a custom RISC-V chip using XiangShan and Mulan PSL v2 follows a structured but highly customizable approach. Developers begin by selecting and customizing the processor core. They start with Kunminghu (Gen3), choosing features such as vector extension and cache configurations. Since the RTL is fully open-source, modifications can be made at a deep architectural level. Unlike proprietary IP cores, developers have complete control over performance tuning, instruction scheduling, and power efficiency.
Once the processor core is selected, RTL design and simulation take place using MinJie, which provides a modular, Chisel-based design flow that enables rapid prototyping. The high-level hardware description language allows flexible modifications while maintaining efficiency. Developers conduct pre-silicon simulations, optimizing logic before physical design.
Verification and testing are performed using UnityChip, which integrates multiple verification methodologies to ensure robust functionality. Security analysis is conducted to prevent speculative execution attacks and cache vulnerabilities. The verification framework also enables collaborative debugging, allowing research institutions and independent developers to contribute to improving the design.
The final step in the process is fabrication. XiangShan cores are designed to be scalable across multiple process nodes, including 7nm, 12nm, and 28nm. Developers can choose local or international fabs such as TSMC, SMIC, or GlobalFoundries based on cost and geopolitical considerations. The Mulan PSL v2 license ensures that there are no commercial restrictions, making it easier to integrate into commercial silicon products.
Table. XiangShan Versus Proprietary Commercial RISC-V IP
Aspect
XiangShan (Mulan PSL v2)
Proprietary RISC-V IP (Commercial Vendors)
Licensing
Fully open-source
Requires paid IP license
Customization
Full RTL access, high flexibility
Limited customization, pre-configured cores
Development Tools
MinJie (open-source agile development)
Proprietary toolchains
Verification
UnityChip (community-driven verification)
Vendor-provided, closed testing
Security Testing
Open security analysis
Limited transparency
Manufacturing Freedom
Fabrication at any foundry
Some IPs are restricted to certain fabs
Cost
Free (no licensing fees)
License fees required
The Open-Source Advantage: Why Choose XiangShan?
XiangShan provides a unique advantage over proprietary RISC-V IP by offering full RTL access and high flexibility, unlike commercial vendors that limit customization through pre-configured cores. Development tools such as MinJie enable agile, open-source development, while proprietary solutions rely on vendor-specific toolchains. Verification is performed through UnityChip, a community-driven framework that encourages open security analysis, whereas commercial IP vendors provide proprietary closed testing. Another key advantage is that XiangShan allows fabrication at any foundry, whereas some proprietary IP solutions may have restrictions on manufacturing partners. With no licensing fees, XiangShan provides a cost-effective alternative, making it ideal for academic research, AI startups, and semiconductor companies looking to fully control their chip design.
Conclusion: The Future of Open-Source RISC-V Chips
Conclusion: The Future of Open-Source RISC-V Chips
The combination of XiangShan, Mulan PSL v2, MinJie, and UnityChip provides a complete, open-source alternative to proprietary RISC-V development. This approach is highly customizable, giving developers full control over their chip’s architecture and performance. It is also cost-effective, eliminating licensing fees and enabling broader adoption in academic and startup environments. Additionally, it is scalable and secure, integrating advanced verification tools to ensure reliability and security.
With continuous community contributions and growing industry adoption, XiangShan is positioned as a leading open-source RISC-V project, pushing the boundaries of open innovation in semiconductor design.
Anna Fontanelli, CEO of MZ Technologies, is a silicon executive with more than 35 years of expertise in managing complex R&D organizations/programs to give birth to innovative EDA technologies. Strong communication skills and proven ability to lead distributed, cross functional teams in international environments. Wide experience in managing multi-million dollars technology partnerships with customers, suppliers, and the EU, including gathering requirements, reviewing specifications, coordinating development efforts, across multiple countries. Anna Fontanelli is the author of several papers (15 including a Best Paper Award) and 2 patents.
What was the most exciting high point of 2024 for your company?
Without doubt, the high point of the year is that we passed a major start-up milestone and acquired our first revenue-generating customer. I can’t tell you who, for competitive reasons, but it is a very well-known global technology leader
What was the biggest challenge your company faced in 2024?
Responding to the challenges posed by the complexity of chiplet-package co-design. It’s like every intellectual challenge: It seems the more you learn, the less you know. Overcoming some of the thermal and mechanical stress aspects of chiplet/package co-design, for instance can prove quite daunting.
How is your company’s work addressing this biggest challenge?
We recently introduced GenioEvoTM. GenioEvo is the first integrated chiplet/package EDA tool to address, in the pre-layout stage the two major issues of 3D-IC design that I talked about earlier: thermal and mechanical stress. It’s the second generation of GENIO™, which was the EDA’s first successful integrated chiplet/package co-design tool.
GenioEvo is a cross-fabric platform for system design providing chiplet/die, silicon interposer, package, and surrounding PCB co-design features that achieve area, power, and performance targets. The tool is technology agnostic and seamlessly integrates through standard formats with all the existing commercial implementation platforms or to custom EDA flows through dedicated plug-ins. It fits into any existing design flow and operates at the architecture level, pathfinding the optimal system choices to implement a 2.5D or 3D multi-die design.
What do you think the biggest growth area for 2025 will be, and why?
I think this is the year that chip stacking and 3D-IC will be taking off. We recently attended a couple of technical and industry events and the interest in 3D-IC enabling technology was more robust and noisier than at any time in the past.
How is your company’s work addressing this growth?
GenioEvo is just the first in a line of innovations that we’ll be rolling out this year. By the end of the year, we will have introduced additional thermal and interconnect features.
What conferences did you attend in 2024 and how was the traffic?
We attended both Chiplet Summit, DAC, and DATE. Chiplet Summit is definitely a growing show, given the status of advanced technology.
Will you attend conferences in 2025? Same or more?
We’ll be exhibiting at both Chiplet Summit and DAC this year.
Additional questions or final comments?
Without a doubt, AI will continue to drive advanced technology innovation. Heterogeneous IC systems are the future. Cost/effective designing and manufacturing these new systems; well, that’s the big challenge.
The semiconductor industry is facing a paradigm shift. Traditional scaling, once driven by Moore’s Law, is slowing down. For years, moving to smaller process nodes led to lower transistor costs and better performance. However, scaling from node to node now offers fewer benefits as wafer costs rise much more than the historical 10% with each new node. This, combined with the physical limits of silicon, makes traditional scaling increasingly unviable. This reality is driving the need for new approaches, with chiplet-based architectures emerging as a solution.
The chiplet-based approach offers significant advantages, including modularity for faster and cost-effective design, customization for meeting specific performance and power needs, improved yield by reducing complexity, optimized power and performance through tailored IP integration, and scalability that allows for seamless upgrades without full-chip redesigns.
Boyd Phelps, Senior VP and GM, Silicon Solutions Group, Cadence, gave a keynote presentation at the Chiplet Summit 2025 conference. His talk addressed how the industry is embracing the chiplet journey, the driving factors for rapid adoption, and how Cadence is bringing value to its customer base.
The Rise of Packaging Technology
Packaging technology is now at the forefront of semiconductor innovation. Foundries are investing 10% or more of their R&D capital in advanced packaging techniques. With innovations in 3D packaging, chiplet designs are now becoming viable. These designs offer more flexibility, allowing chiplets from different vendors to be seamlessly integrated into a system, creating a new level of abstraction in chip design.
Next-generation packaging technologies, such as fine-pitch hybrid bonding interconnects (HBI) and through-silicon vias (TSVs), enable further chiplet disaggregation. These technologies allow for ultra-fine interconnects of 3µm, 6µm, and 9µm between stacked dies, eliminating the need for soldered connections. This innovation not only enhances power efficiency and signal integrity but also reduces overall system complexity.
The Demand for Custom Silicon
The demand for custom silicon is being driven by the growing needs of data centers, where fixed power budgets must be balanced with ever-increasing performance demands. Chiplets provide a power-efficient solution for custom silicon, allowing specific functionalities to be tailored for different workloads. This is crucial as industries like automotive, aerospace and defense, and consumer electronics also experience rapid disruption and transformations.
Streamlining Chiplet Design with Pre-Designed Frameworks
At Cadence, the shift to chiplet-based designs is aided by pre-designed chiplet frameworks that allow engineers to quickly select and integrate the right chiplets for various applications. These frameworks reduce design time, enabling faster time-to-market for custom silicon solutions. This modular approach offers greater flexibility compared to traditional monolithic designs.
Automating Custom Silicon Design
The complexity of chiplet-based design requires automation tools. Cadence’s SoC Cockpit concept represents the future of design automation, providing a seamless framework for managing chiplet-based designs. By integrating system-level planning, verification, and optimization, the SoC Cockpit enables efficient chiplet integration, reducing design complexity and accelerating time-to-market.
By using correct-by-construction tools, the design process is made more efficient, ensuring that the final system meets all performance and safety requirements without the need for manual verification.
Seamless Integration in a Chiplet Ecosystem
Going forward, all intellectual property (IP) will be developed with the chiplet framework in mind. The goal is to ensure seamless integration of chiplets from different vendors into a cohesive system that meets the performance, power, and cost requirements of a wide range of applications. This shift will require new design methodologies, tools, and standards that make it easier to develop and integrate chiplets, enabling a more agile and efficient design process.
Summary
The future of semiconductor design lies in the seamless integration of chiplets. As wafer costs rise and node-to-node scaling slows, chiplet-based architectures offer a flexible, scalable, and cost-effective solution. By automating design processes and adopting chiplet frameworks, semiconductor companies can meet the growing demands of industries like data centers, automotive, and consumer electronics, ushering in a new era of innovation in semiconductor solutions.
More information on Cadence’s silicon solutions for accelerating next-generation chiplets and SoCs can be found here. To learn about Cadence’s full suite of tools, methodologies and IP to support your chiplet journey, visit this page.
Justin Susumu Endo, Mixel’s Director of Marketing & Sales, oversees marketing strategy and customer engagement from Mixel’s headquarters in San Jose, California. He holds a bachelor’s degree with a double major in economics and French from the University of California, Los Angeles, and an MBA from The University of Melbourne – Melbourne Business School.
Tell us a little bit about yourself and your company.
Founded over 25 years ago, Mixel is a leading provider of mixed-signal interface IP. We offer a wide portfolio of high-performance mixed-signal connectivity solutions. Mixel’s IP portfolio includes PHYs and SerDes, such as MIPI PHYs (MIPI D-PHY, MIPI C-PHY, and MIPI M-PHY), LVDS, and Multi-standard SerDes I lead Mixel’s marketing and sales strategy and implementation.
What was the most exciting high point of 2024 for your company?
2024 was an eventful year, filled with multiple tape outs and our customers’ first-time silicon successes. The highlight was the establishment of our new engineering office in Da Nag, Vietnam. They are a talented group of people and are a great fit for the Mixel. We also had a big win with one of the Magnificent Seven, and started work in the most advanced node going to production in 2025.
What was the biggest challenge your company faced in 2024?
There have been lingering challenges in our industry with uncertainty around investment due to external, macroeconomic factors which directly affected many of our customers and their decision-making processes. This, in turn, resulted in some of our customers pushing project starts out during the first half of 2024. In the second half of 2024 we saw noticeable improvement and increased bookings.
How is your company’s work addressing this biggest challenge?
We consistently make decisions based on long-term strategic planning, considering our vision of where we believe growth opportunities are, that are aligned with the direction of our substantial number of strategic customers and partners.
What do you think the biggest growth area for 2025 will be, and why?
We expect that in 2025, we will continue to see major growth in automotive and Virtual Reality/Augmented Reality applications. In automotive, there are many opportunities as the number of interconnects increase proportionally with the number of increasing sensors, cameras, and displays increase in cars. In VR/AR, we see increasing adoption of MIPI interfaces for sensors and displays due to the strengths of MIPI PHYs including low form-factor, low power consumption, low EMI, and high bandwidth. We expect that 2025 will be the year where we will see increasing revenue from IPs beyond MIPI for Mixel. This is very exciting for us, since this is an important goal, we have been targeting for a while now.
How is your company’s work addressing this growth?
We have grown our engineering teams in the US, Egypt, and opened the new office in Vietnam to address our customers growing demand for mixed-signal interface IP and expand our global presence.
What conferences did you attend in 2024 and how was the traffic?
We attend all the MIPI face-to-face meetings as an active contributor to the MIPI Alliance. We took part in MIPI’s demo day at Taipei’s meeting last year, which was open to contributors, adopters, and non-MIPI members. In addition, we sponsor many of the largest foundries’ events such as TSMC Technology Symposium & TSMC OIP Ecosystem Forum, GlobalFoundries Technology Summit, Samsung Foundry Forum & SAFE Forum, and Tower Semiconductor Technical Global Symposium. At these events, we highlight our customers who have integrated our IP into their product. Our most recent demos include Teledyne e2v’s Topaz CMOS image sensor for industrial IoT applications and Hercules Microelectronics HME-H3 low-power FPGA which has been integrated into dual display smartphones such as the foldable Blackview Hero 10. Traffic overall to events in 2024 is better than 2023.
Will you attend conferences in 2025? Same or more?
We will be exhibiting at the same events as last year and will look to add others, particularly those outside the US.
Keysight, with deep roots tracing back to Hewlett-Packard, has long been at the forefront of innovation in electronic design and testing. It manufactures electronics test and measurement equipment and software. The company also owns its own foundry and makes custom chips and packages for its instrumentation business. Many may not be aware that it has a long history in electronic design automation (EDA) too and provides advanced solutions for high-speed digital design.
Over the past decade, the shift from monolithic System-on-Chip (SoC) architectures to chiplet-based designs has introduced new challenges and opportunities. Keysight is actively addressing three critical aspects of this transformation: designing for chiplet interoperability, testing for chiplet interoperability, and managing data and IT in a chiplet ecosystem. Nilesh Kamdar, General Manager of Keysight’s EDA division gave a talk at the recent Chiplet Summit 2025.
Designing for Chiplet Interoperability
As the semiconductor industry moves towards a disaggregated model, similar to the early days of the computer industry transitioning away from vertical integration, chiplet-based architectures offer a way to mitigate risk and accelerate time to market. Not every function needs to scale down to the next process node, allowing for a multi-vendor, multi-process ecosystem. Specialization and standardization have helped in scaling chiplet adoption.
Keysight has been actively involved in partnerships to enhance interoperability. One notable example is its work with IP vendor, Alphawave Semi on the Universal Chiplet Interconnect Express (UCIe) standard. By aligning with customer requirements, the company has developed strategies for signal integrity analysis, pre-layout and post-layout modeling, and managing the forwarded clock alongside data transfer.
Another key performance indicator (KPI) that Keysight has focused on in its simulation options for UCIe is the Voltage Transfer Function (VTF). VTF provides valuable insights into crosstalk performance, a critical factor in ensuring reliable chiplet communication. By accurately modeling VTF, engineers can analyze signal integrity and assess potential interference between interconnected chiplets. This makes VTF a key metric for optimizing interoperability and minimizing design risks in complex multi-vendor environments.
Simulating interoperability is key, and Keysight’s expertise in PHY layer analysis plays a crucial role in ensuring seamless communication among various chiplets in a design.
Testing for Chiplet Interoperability
Traditional plugfest testing—where multiple vendors bring devices to verify compatibility, such as in PCIe or USB environments—does not directly translate to the chiplet ecosystem. Instead, Keysight is exploring new strategies to validate chiplet interoperability effectively.
One method involves analyzing passive structures such as Through-Silicon Vias (TSVs), packages, and transmission lines using microprobes and network analyzers for testing which generate S-parameter files as an output . When it comes to active structures, transmitter (Tx) performance can be evaluated using high-end oscilloscopes, while receiver (Rx) validation can leverage a golden reference signal generated by a Bit Error Rate Tester (BERT) to measure response.
Additionally, many chiplets now incorporate on-chip Built-In Self-Test (BIST) mechanisms. While useful, these embedded tests can sometimes be overly optimistic or fail to account for non-linearities. Keysight enhances BIST effectiveness by providing independent, high-precision measurements through oscilloscopes and other test instruments, ensuring accurate calibration and validation.
Data and IT Management in the Chiplet Ecosystem
With chiplet designs introducing greater complexity, managing data across different components and vendors becomes increasingly challenging. Keysight addresses this issue through its enterprise-grade Engineering Lifecycle Management (ELM) tools. These solutions help customers efficiently handle chiplet-related data, ensuring smooth integration and lifecycle tracking. By providing comprehensive data structuring, version control, and real-time collaboration features, these tools enable engineers to maintain design consistency across multi-vendor environments. ELM solutions also enhance traceability, allowing teams to quickly diagnose and resolve design conflicts or interoperability issues. Additionally, Keysight’s approach ensures compliance with evolving industry standards, facilitating smoother adoption of chiplet-based architectures in diverse applications.
Summary
By combining its expertise in test and measurement with advanced data management solutions, Keysight is well-positioned to support the next generation of chiplet-based designs. Its contributions to interoperability, rigorous testing methodologies, and robust IT management solutions are shaping the future of the chiplet revolution, helping the industry transition smoothly from monolithic SoCs to a more flexible and scalable ecosystem.
Ollie is a commercially astute senior leader with over 20 years of experience in strategy, business development and sales across the technology and engineering sectors, with a strong track record in scaling businesses and driving growth. He has held commercial leadership roles in FTSE 100, private equity-backed, and startup companies, working extensively across Europe, North America, and Asia.
Tell us a little bit about yourself and your company.
Sondrel was founded in 2002 after identifying a gap in the market for an international company specialising in customer-specific digital IC design. Sondrel’s services range from turnkey ASIC “architecture through silicon supply” to team augmentation for customers needing less than full service. We are one of only a few companies capable of designing and supplying the higher-spec chips built on the most advanced semiconductor technologies.
Being headquartered in the UK, we are perfectly positioned to service companies around the globe via our global design centres and network offices. This also means that we can work for American customers without any geopolitical trade restrictions.
We offer an end-to-end, turnkey solution including the whole chip creation journey helping with the hard decisions required to create a complex ASIC. Many of our customers are systems house, in markets such as HPC, automotive, networking or vision systems but we also support fabless chip providers seeking to get new products to market. Our highly experienced teams of engineers draw on hundreds of successful projects to ensure that we bring added value to enhance a customer’s project because we know how to achieve the very best performance, power and area for a design.
What was the most exciting high point of 2024 for your company?
We have refocused the company on our key differentiator which is meeting our customer design needs with exemplary care and attention at every stage of a chip project, from architectural specification through design to final shipping silicon. It is a complete, comprehensive, custom chip creation service that we only offer to a select number of companies who want a partnership that they can rely on. After all, modern chip projects cost millions so customers need to have complete trust that their partner will deliver a quality product to agreed timescales and budgets.
We have the skills to handle each project as our team of engineers have thousands of years of cumulative design skills from hundreds of successful projects at leading edge nodes right down to 3nm so customers can be confident that their project will be in safe hands.
And we are small enough to be able to focus and really care about each customer and the success of their project. This sets us apart from our competition.
What was the biggest challenge your company faced in 2024?
Delisting from the Stock Market. The Board realised that the company would be more agile and better placed to respond quicker to changing market trends if it was not listed at this stage in our growth.
How is your company’s work addressing this biggest challenge?
We had a terrific team in place that ensured that this was effected smoothly. We are now a private company with one large investor and numerous smaller investors. We are focused in growing our business one customer at a time, partnering to deliver on their success.
What do you think the biggest growth area for 2025 will be, and why?
Advanced semiconductor designs. Electronics is the driving enabling force for innovation across so many areas: High Performance Computing in the datacenter, Artificial Intelligence at the edge, Advanced Driver Assistance Systems for cars, communications connecting the datacenter and edge. Their common theme is ever more complex chip designs with billions of transistors and advanced manufacturing process nodes. Our focus is delivering quality results to our customers, whatever their end-markets or applications
How is your company’s work addressing this growth?
Our specialty has always been chips at the leading edge of design technology and laying out millions and then billions of transistors as process technologies became smaller and smaller so we are perfectly positioned to provide the ultra-complex custom chips that customers need to create next generation products.
What conferences did you attend in 2024 and how was the traffic?
Sondrel was at multiple conferences across North America and EMEA in 2024, including multiple RISC-V conferences globally, AI and Edge events and partner events from TSMC, ARM, Samsung, Global Foundry and Tower-Jazz. It’s exciting to see so many new semiconductor designs underway.
Will you attend conferences in 2025? Same or more?
Our primary focus is serving our customers but we will also be participating with selected industry events. Overall, we are planning to attend more conferences in 2025 but our focus is on quality of events, not quantity. We do see face to face interactions as a great way to engage with potential customers as they can rapidly see how passionate we are about what we do and that we really care about customers.
How do customers engage with your company?
We have a technical sales team who are backed up with highly experienced engineers who invest the time at the start of a project to define it in much greater depth, I believe, than any of our rivals. We often begin with an Architectural Specification stage to ensure that both parties are aligned on the entire scope of the project and so that we can reduce unexpected hiccups. This stage also provides the roadmap for the whole project to ensure a holistic approach is maintained at all times to keep the project on schedule, in budget and meeting performance objectives.
Additional questions or final comments?
We aren’t interested in coming in with low-ball bids which rely on ECOs that up the cost to customers. Our focus is getting a full alignment with each customer upfront to help ensure we deliver exactly what they need. Think of it as “measure twice, cut once.” We think this is a key benefit to each of our customers.
At IEDM held in December 2024, TSMC presented: “2nm Platform Technology featuring Energy-efficient Nanosheet Transistors and Interconnects co-optimized with 3DIC for AI, HPC and Mobile SoC Applications,” the authors are:
Geoffrey Yeap, S.S. Lin, H.L. Shang, H.C. Lin, Y.C. Peng, M. Wang, PW Wang, CP Lin, KF Yu, WY Lee, HK Chen, DW Lin, BR Yang, CC Yeh, CT Chan, JM Kuo, C-M Liu, TH Chiu, MC Wen, T.L. Lee, CY Chang, R. Chen, P-H Huang, C.S. Hou, YK Lin, FK Yang, J. Wang, S. Fung, Ryan Chen, C.H. Lee, TL Lee, W. Chang, DY Lee, CY Ting, T. Chang, HC Huang, HJ Lin, C. Tseng, CW Chang, KB Huang, YC Lu, C-H Chen, C.O. Chui, KW Chen, MH Tsai, CC Chen, N. Wu, HT Chiang, XM Chen, SH Sun, JT Tzeng, K. Wang, YC Peng, HJ Liao, T. Chen, YK Cheng, J. Chang, K. Hsieh, A. Cheng, G. Liu, A. Chen, HT Lin, KC Chiang, CW Tsai, H. Wang, W. Sheu, J. Yeh, YM Chen, CK Lin, J. Wu, M. Cao, LS Juang, F. Lai, Y. Ku, S.M. Jang, L.C. Lu- with Jeffrey Yeap presenting the work.
This paper continued TSMC’s trend over the last several years of presenting marketing papers at IEDM instead of technical papers. In fact, this paper took the trend even further, there are no pitches in the paper, no SRAM cell size, and that graphs are all relative performance graphs without real units. Although the paper doesn’t present the kind of technical details that would typically be included in an IEDM paper, it does paint a picture of a process ready for 2025 production and the session was packed.
In this review we will take the few substantive details that are in the paper as well as our own analysis and present how the process compares to competing 2nm class processes.
In terms of the overreaching Power, Performance, and Area (PPA), the paper states that the process delivers a 30% power improvement or 15% performance gain and >1.15x density versus the previous 3nm node. Note: the 3nm paper reference suggests this is in comparison to N3E, not N3.
Power
At the 14nm (Samsung)/16nm (TSMC) node Samsung and TSMC both produced the Apple A9 processors. Measurements by Tom’s hardware found the Samsung version had slightly better power performance compared to TSMC. We believe the A9 was designed for Samsung first so that may simply reflect a design that is more optimized for Samsung that was ported to TSMC, nevertheless, the power was very close between the two. Going forward from 14nm/16nm, to 10nm, 7nm, 5nm, 3nm, and now 2nm Samsung and TSMC have both provided relative power improvement for each node versus the previous node.
We have been able to compare the Samsung and TSMC at 3 different nodes since the 14/16nm comparison and our extrapolations have been consistent with those values.
At 10nm TSMC provided a larger power reduction than Samsung and maintained that lead until 3nm where Samsung Gate All Around (GAA) provided a large enough improvement to mostly close the gap to TSMC’s 3nm FinFET process in power (GAA versus FinFET is expected to provide a greater power improvement).
TSMC 2nm announced power improvement of 30% versus 3nm is greater than Samsung’s 25% improvement and TSMC once again maintains a lead.
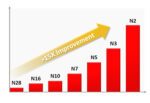
During the presentation of the paper, graphs were shown of power efficiency and performance per watt versus node. The power efficiency graph was in one version of the paper although it is not in the “final” version of the paper published in the proceeding. Thankfully we captured the power efficiency graph because it is very interesting to analyze, see figure 1.
Figure 1. TSMC Power Efficiency.
We took the graph image, pulled it into Excel and created an Excel graph overlaying it with the 28nm bar normalized to 1 and then entering values for the other bars until they matched the graph. If we then build a set of bars starting at 28nm = 1 scaled up based on the TSMC announced node to node power improvements we get a total improvement of less than 9x. Nodes from N28 to N10 match well but from N7 on the bars on the graph show more improvement per node than TSMC has announced. Just the N3 to N2 bars on the graph show a 55% improvements versus the announced 30% improvement.
It isn’t clear what may be driving this difference, but it is a big disconnect. This may be why the graph was removed from the final paper.
Performance
Similar to the power analysis above, at Samsung 14nm/TSMC 16nm the Apple A9 processor had identical performance on the 2 processes. Normalizing both processes to 1 and applying the announced node to node performance improvements from both companies it is possible to compare performance per node. It has also been possible to use an Intel 10SF versus AMD processors on TSMC 7nm process, to add Intel to the analysis and forward calculate based on Intel performance by node announcements.
We have been able to check our extrapolations at 3 nodes for Samsung and TSMC since the 16/14nm nodes as well as Intel at 2 nodes and those checks have confirmed our extrapolations are tracking correctly.
Based on this analysis it is our belief that Intel 18A has the highest performance for a 2nm class process with TSMC in second place and Samsung in third place.
Our performance index values are in the full article available with free registration on the TechInsights platform here.
Area
The third part of PPA is area. We analyze two “area” related factors, one is high density logic cell transistor density and the second is SRAM cell size. TechInsights has done detailed reverse engineering work on TSMC N3E process and we have all the pitches necessary to calculate our standard high density logic cell transistor density. Similarly, we have analyzed Samsung SF3E and SF3. Both TSMC in this paper and Samsung in public statements have provided density improvement values for 2nm. In the case of Intel we have used our own estimated pitches to do a density comparison. For high density logic cells TSMC is well ahead of Samsung and Intel on density, Intel is second, and Samsung is third.
The high density logic cell transistor density is in the full article available with free registration on the TechInsights platform here.
As previously mentioned, the TSMC paper does not include SRAM cell sizes, however there is a graph of SRAM density versus node, see figure 3.
Figure 3. SRAM Array Density Versus Node.
The problem with this is an SRAM array includes not only the SRAM cell but also overhead, for example 7nm has 25.0 Mb/mm2, the SRAM cell size at 7nm was 0.0270um2. If you multiply 25.0Mb by the SRAM cell size, you get 0.675mm2. The difference between 1.000 and 0.675mm2 is the overhead and it isn’t constant from node to node, see table 1.
Yield
Yield is a hot topic these days with lot of reports about Samsung struggling with yield at 3nm and losing customers due to low yield, there have also been some recent reports that Intel’s 18A yield is 10%.
In the paper TSMC reports that a 256Mb SRAM array has >80% average yield and >90% peak yield. These yields at this point in development indicate excellent defect densities. There are other yield components beside those tested in an SRAM array, but these are impressive results.
With respect to Intel’s 10% yield report, we have had two separate credible sources that tell us that simply isn’t true, that yields are much better than that. The other things about a report of 10% yield is how big/what is the die and at what point in development was that yield seen if it is even true. Our belief based on our sources is the 10% reported yield is either wrong or old data.
Wafer price
Another number that has been widely circulated is that TSMC is going to charge $30,000 per wafer for 2nm.
TechInsights produces the world’s leading cost and price models for semiconductors. Prior to 3nm entering production we were projecting <$20,000 per wafer and a few customers contacted us insisting 3nm prices would be $20,000 to $25,000 per wafer. Once 3nm entered production we were able to run our proprietary forensics on TSMC’s financials and determine we were correct, and the volume price was <$20,000/wafer by thousands of dollars.
To go from a price of <$20,000/wafer for 3nm wafers to $30,000/wafer for 2nm wafers is a >1.5x price increase for a 1.15x density improvement, that is a dramatic increase in transistor cost and it raises the question of who would pay that, our price estimates are <$30,000/wafer. There have also been reports that Apple who is typically TSMC’s lead customer for each node may be forgoing initial 2nm use due to price although we have also heard push back on that.
Another element to this discussion is what volumes the pricing is for TSMC’s high volume wafer price is a lot lower than their low volume wafer price, so volume needs to be considered in any discussion. In general, we believe $30,000 is higher than the average to high volume pricing will be.
If TSMC prices 2nm wafers at $30,000/wafer they will create a lot of pressure for customers to switch to Intel and Samsung for 2nm class wafer supplies.
Backside Power Delivery
The TSMC paper does not address backside power delivery but competing 2nm processes will be implementing backside power delivery.
Intel 18A will have backside power delivery – with a 2025 ramp Intel will be the first to implement this technology. In 2026 Samsung SF2P process is due to also implement backside power delivery. Finally, TSMC is not expected to implement backside power delivery on their 2nm process variants at all and will wait until 2027 (recent reports are that this is being pulled in to 2026) to implement it on their A16 process. The A16 backside power delivery is expected to be a direct backside connection that can provide smaller track heights than Intel’s and likely Samsung’s implementation.
Since Intel is the most performance focused of the three companies it makes sense, they are implementing backside power delivery first.
Another interesting thing we are hearing about backside power delivery is that foundry HPC customers want it but mobile customers don’t due to cost.
For multiple nodes we may see nodes with and without backside power delivery and given the effect it has on metal 0 the design rules would likely be different. In addition to this for the highest performance we expect molybdenum to be introduced first for vias and later from critical interconnect. This could lead to nodes splitting between backside power delivery and molybdenum metallization for HPC and no backside power and copper metallization for mobile.
Other
One final interesting item in the paper is the comment about “flat passivation”. Many processes have a top aluminum metal layer and passivation follows the metal contours, if something like hybrid bonding is desired the wafer surface must be flat. Flat passivation is presumably a planarized top layer to enable bonding.
Conclusion
TSMC has disclosed a 2nm process likely to be the densest available 2nm class process. It also appears to be the most power efficient at least when compared to Samsung. In terms of performance, we believe Intel 18A is the leader. The early yield reports appear promising, but the reports of $30,000/wafer pricing do not in our opinion represent acceptable value for the process and may present an opportunity for Intel and Samsung to capture market share . TSMC 2nm should be in production in the second half of this year.
Dan is joined by Evan Price, Product Manager for embedded processors at CAST. Evan has had a diverse and successful 15-year career developing, then leading as project manager and director, with a variety of semiconductor-based products. Evan joined CAST in 2024 and provides technical support as well as handling product marketing and strategy for the company’s embedded processors line.
Dan explores the RISC-V market with Evan. The size and focus of the current market are discussed, along with projections of growth and how RISC-V processors will move from a supporting role to a lead processor role over time. The power of the RISC-V ecosystem and the unique ability to extend the instruction set are reviewed. Evan also describes the particular strengths that CAST can offer designers who want to use the RISC-V architecture based on the 30-year history of CAST’s outstanding customer support.
The views, thoughts, and opinions expressed in these podcasts belong solely to the speaker, and not to the speaker’s employer, organization, committee or any other group or individual.
Mouna Elkhatib is the CEO, CTO, and Co-Founder of AONDevices, Inc., a leading provider of super-low-power Edge AI solutions. A visionary entrepreneur and innovative leader, Mouna has successfully grown AONDevices into a recognized leader in the Edge AI space. With over 20 years of experience in semiconductor technology, she has a successful track record in both engineering and leadership. She is an industry expert in voice and audio processing, specializing in system architecture, DSP, ML, and chip design.
Tell us about your company.
AONDevices, Inc. is a leader in super-low-power, high-accuracy Edge AI solutions, redefining always-on, battery-operated devices. With cutting-edge chip architecture, lightweight neural networks, and the AONx360 platform featuring extensive data augmentation, AONDevices delivers exceptional AI performance at super-low power.
Designed for OEMs, AONDevices’ scalable solutions enable advanced features like wake word detection, voice commands, acoustic event recognition, gestures, motion tracking, and environmental context awareness. From personal devices and smart home systems to automotive technology, AONDevices empowers the creation of intelligent, energy-efficient, and privacy-focused products.
What problems are you solving?
AONDevices addresses key challenges in Edge AI with innovative solutions tailored for energy efficiency, development simplicity, and cost-effectiveness. Our super low-power technology, consuming less than 260µW, powers advanced AI features for battery-operated devices like wearables and headsets without compromising battery life. By enabling high-accuracy, low-latency solutions such as gesture recognition, acoustic scene detection, motion tracking, and sensor fusion, our technology excels even in noisy or dynamic environments. The AONx360 platform simplifies the creation, optimization, and deployment of ML models, ensuring a faster time-to-market while reducing development complexity. With on-device AI, we ensure compliance with regulations like GDPR, supporting features such as voice command recognition, speaker identification, and environmental context detection. Additionally, our validated silicon and adaptable platform provide a cost-effective path for developing multiple products using the same hardware, making AONDevices a comprehensive solution for Edge AI challenges.
What application areas are your strongest?
AONDevices delivers super low-power, high-accuracy Edge AI solutions across a range of applications, enhancing functionality and user experience. For remote controls, our technology enables wake word detection, voice commands, speaker identification, acoustic event detection and multi-sensor fusion, providing intuitive, hands-free TV and device control. In headsets, AONDevices supports voice commands, acoustic event recognition, targeted and generic noise suppression, and real-time environmental awareness, ensuring clear calls and device capture. Wearables benefit from motion tracking, gesture recognition, wake word detection, and environmental context awareness, all integrated with noise suppression for smarter, energy-efficient performance. In smart home applications, AONDevices powers features like acoustic event detection (e.g., glass breaking), voice commands, and adaptive system control, while in automotive settings, it enhances in-cabin experiences with wake word detection, gesture recognition, speaker identification, and noise suppression for improved communication and safety.
What keeps your customers up at night?
Customers in the Edge AI market face several challenges, from balancing performance and efficiency to navigating complex integration requirements and regulatory pressures. They require accurate, always-on features like acoustic event detection, motion tracking, and voice command detection, all while maintaining battery life. Integration complexity, particularly in hardware and software compatibility, demands streamlined tools like the AONx360 platform for rapid deployment. Additionally, the dependency on high-quality datasets, often costly to obtain, is addressed through AONDevices’ data augmentation techniques, simplifying model creation. In a rapidly evolving market, customers rely on AONDevices for proven, ROI-focused solutions that mitigate the uncertainty of disruptive advancements. Moreover, our on-device AI ensures compliance with data privacy regulations like GDPR while securing local processing. AONDevices delivers low-power, high-accuracy AI solutions with simplified integration and robust support to overcome these challenges.
What does the competitive landscape look like, and how do you differentiate?
AONDevices distinguishes itself in the competitive Edge AI market by delivering comprehensive, innovative solutions that empower OEMs to create efficient, high-performing products. Our end-to-end approach integrates ML chips, models, and software, validated for seamless deployment. With market-leading power efficiency consuming as little as 260µW, our technology is ideal for battery-operated devices. We achieve high accuracy, exceeding 90% hit rates at 0dB SNR with a single microphone in real-world conditions. Our cost-effective platform supports multiple products using the same adaptable hardware, significantly reducing external algorithm costs. Data efficiency is enhanced through data augmentation, ensuring high accuracy even with limited datasets. By leveraging multi-sensor fusion, we enable advanced features such as gesture recognition and environmental context awareness, combining motion, acoustic, and environmental data. Our AONx360 platform further accelerates ML model creation and deployment, ensuring quick time-to-market. AONDevices provides the tools and technology for OEMs to innovate and adapt with confidence.
What new features/technology are you working on?
AONDevices is revolutionizing Edge AI with cutting-edge innovations designed to empower OEMs with super low-power, high-performance, and adaptive AI solutions. Our super low-power ML multi-sensor fusion integrates motion tracking, gesture recognition, and environmental context detection, enabling hands-free control and real-time context awareness in devices like smart glasses and fitness trackers. The next-generation AON2100 architecture combines optimized ML accelerators and RISC-V processors to enhance multi-sensor fusion, voice processing, and real-time decision-making. With AONx360 PRO, we expand model generation tools to offer minimal or no-data model creation, accelerating AI deployment. Additionally, our software IP for micro neural networks allows OEMs to seamlessly integrate ultra-compact and efficient AI models into devices like earbuds, smart rings, and wearables, offering unparalleled hardware and software flexibility. These advancements position AONDevices at the forefront of Edge AI, delivering unmatched efficiency and adaptability.
How do customers normally engage with your company?
Customers engage with AONDevices through a range of offerings designed to accelerate product innovation and deployment. Our chip integration solutions enable ultra-low-power ML features, such as wake word recognition, gesture detection, and motion tracking, in personal devices and wearables using the AON11xx chips. For tier-1 customers, we provide SW/HW strategic licensing, offering ML algorithms and IP for applications like true wireless stereo (TWS) headsets. Our ML model training services deliver customized model development through NRE fees, addressing solutions like denoisers, sensor fusion, and context detection. The AONx360 platform, offered as a subscription-based Software as a Service (SaaS), streamlines ML model creation, optimization, and deployment. Finally, our global support and distribution network ensures smooth integration and post-deployment optimization worldwide. By combining hardware, software tools, and tailored services, AONDevices provides a comprehensive ecosystem to meet customer needs and drive innovation.