The first consumer products with 20nm processing are arriving in 2014 like the 2 billion transistor A8 chip in the iPhone 6, however at the 14nm node there are new designs underway to continue the trend of Moore’s Law. To get a better feel for the challenges of designing with 14nm FinFET technology I watched a 23 minute video presentation by Dr. K.K. Lin of Samsung over at the Cadence site. I prefer listening to real EDA tool users instead of vendor presentations, because I get to learn their methodology and the benefits compared to previous approaches.
Related: What Apple Talked about on 9/9/2014
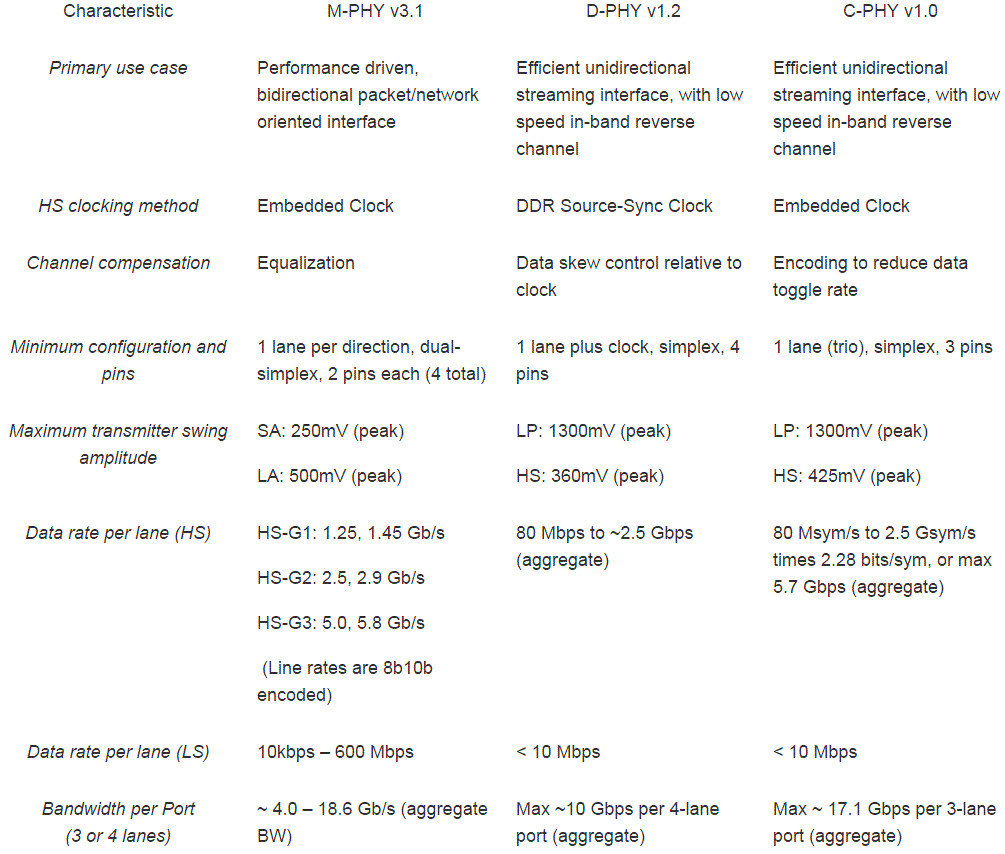
Samsung decided to create two versions of 14nm FinFET: 14LPE (early version) and 14LPP (lower power). You can start prototypes now and expect production by end of 2014. Other foundries have re-used much of their 20nm planar technology into 14nm FinFET, resulting in little size reduction whereas Samsung has an aggressive 78nm poly pitch that enables about 10% smaller areas. Performance improves up to 20% and power is reduced by 35% when going from 20nm planar to 14nm FinFET with Samsung. Cadence users have complete PDKs (Process Design Kits) available now.
Related: A Deeper Insight into Quantus QRC Extraction Solution
The Virtuoso tools from Cadence enable 14nm design using the IC12 tech file with features like:
- Virtuoso Space-based Router (SBR)
- Analog Placer (AP)
- Layout Dependent Effect (LDE)
- Double Patterning Technology (DPT)
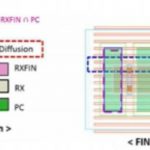
Pcells provide layout automation of FinFET transistors by adding FIN dummy above and below the device, plus quantized fingers:
Layout cell instances can be abutted to avoid any of the complex violations found in 14nm. DPT started at the 20nm node and continues at 14nm, so with Virtuoso you can interactively view any of the DPT issues like: coloring loop detection, color shorts and DPT DRC errors.
For custom IC designs you can perform interactive routing with a Virtuosofeature called pin to trunk (P2T), and designers at Samsung have measured turn-around time improvements between 14% and 63% on: source/drain routing, gate routing and general routing. The new Virtuoso space-based router (VSR) used on 14nm can improve routing productivity by up to 75%.
Related: What’s New with Circuit Simulation for Cadence at DAC
The impact of LDE issues is reduced in Virtuoso by an architecture that enables quick iterations between layout and simulation, even before the design is LVS clean. Using three automation features (Analog Placement, P2T and VSR) provided a 24% schedule reduction compared to older, more manual methods.
Related: Designing an SoC with 16nm FinFET
View the entire 23 minute video here at the Cadence site, and there’s no registration required.