We know there is a big divide between analog and digital design methodologies, level of automation, validation and verification processes, yet they cannot stay without each other because any complete system on a chip (SoC) demands them to be together. And therefore, there are different methodologies on the floor to combine analog and digital designs together and simulate and validate them together. In case of verification, digital design verification is highly automated based on assertions applied through readily available languages, however analog design verification is mostly done manually on an ad-hoc basis. Although a good level of effort has been done in the semiconductor design and verification community to automate validation of analog digital mixed-signal (AMS) designs through a single testbench which may utilize UVM methodology, a dedicated automation for verification planning of analog design is still essential to cover today’s increased design complexity, large variation in device characteristics and meeting specifications across all process corners to ascertain coverage and quality of verification.
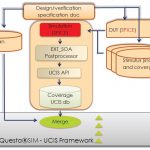
Mentor Graphicshas developed a novel methodology for analog design verification planning which uses Coverage Driven Verification (CDV) in the similar manner as is done in digital world. It utilizes a requirement tracking system that links the design specification to CDV and tracks the status of verification through several stages.
Each design specification is linked to one or more items in the test plan and vice-versa. All items in the test plan are linked to simulation results. Analog design simulation is primarily Spice based and uses multiple analyses such as transient, AC, RF and Monte Carlo at various PVT corners. The .EXTRACT and .SETSOA constructs of Spice with boundary conditions can be used to ascertain if a selection being tested passes or fails or is within the boundary limits, thus providing a way to decide on testbench setup and stimuli to test the cover points. The methodology uses UCIS(Accellera unified coverage interoperability standard) APIs and database to represent the coverage data in a standard way that can be accessible through different tools from different vendors. The verification status along with coverage data, dependencies and any change impact can be reported at various levels such as Executive Summary, Project Status or at the granularity of cover points, as required for different stakeholders.
Most of the analog design characteristics such as transient and frequency domain characteristics presented in an architecture or specification document can have their corresponding cover points captured in a test plan which can be in the form of an Excel spreadsheet. The requirement tracking and verification planning can be done with existing tools with some enhancements required to accommodate analog design characteristics. Mentor uses Reqtracer for requirement tracking, Eldo for Spice simulation and Questa for viewing, merging, analysis and reporting of the UCIS database.
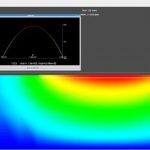
Mentor’s verification team used an OPAMP design for proof of concept of this verification methodology. In the above picture is the illustration of how cover points are implemented by using the EXTRACT and SETSOA constructs in Spice netlist. In this example, nine different tests covering PVT and parameters sweep along with transient, frequency domain, and quiescent analysis are setup in a regression environment. Simulation is done for each test and corner, results are post-processed using a custom script and the UCIS API is used to write the data into the UCIS database.
Above picture shows how specifications are extracted from a MAS (Microarchitecture or specification) document and linked to test plan and tests are linked to simulation results. There can be one-to-one, one-to-many or many-to-one relationships. This provides the actual status of verification against the defined objectives. Different views of reports representing the overall status of verification can be obtained from this. Upstream and downstream dependency graphs for each verification objective in the test plan can also be drawn for analysis.
Questa coverage viewer is used to view and analyze the merged simulation result from UCIS database against the goals set for each objective in the test plan. This analysis provides real-time information about the overall coverage along with failing tests (e.g. slew rate in this case) and any coverage holes for which cover points are not implemented (e.g. quiescent current specs in this case). The UCIS data can be analyzed in multiple ways as per individual needs by using command line interface. The bottom part of above example shows failing cover points in ‘red’ color along with their failure counts. By adding user attributes in UCIS, these can be linked to generate debug information. With the progress of the design, effort is put to remove the coverage holes, convert failing tests to pass and improve coverage for design closure. Trend analysis graph of coverage against goal can also be plotted to assess maturity of the design at certain intervals.
Questa SIM – UCIS Framework enables CDV methodology for analog designs (with a few enhancements to existing digital verification flows), thus unifying verification methodology for digital and analog designs. Read this whitepaperwritten by Atul Pandey, Guido Clemens and Marius Sida at Mentor Graphics for more details.