You can save a lot of power in a design by gating clocks. For much of the time in a complex multi-function design, many (often most) of the clocks are toggling registers whose input values aren’t changing. Which means that those toggles are changing nothing functionally yet they are still burning power. Why not turn off those clock toggles at those registers when they’re not needed? That’s the reasoning behind clock gating.
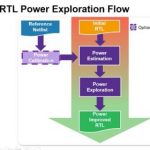
Nice principle, but figuring out how best to apply it to your design in realistic use-cases takes some work. First, modifying the design to add clock gating definitely isn’t practical at layout or even pre-layout gate-level. You’re going to need to add logic and wiring and that’s best done at RTL. But then you worry about accuracy: to know where best to gate, you need to be able to run power estimates. At the layout/gate-level these can be pretty accurate (typically within 5% of silicon). But at RTL there’s more uncertainty so accuracy is more like ±15% of accuracy at layout.
Is this uncertainty too big to make power optimization useful at this level? Not at all but you have to think carefully about your approach and the choices you make. An important point is that, in this kind of analysis, relativeaccuracy is typically much better than absolute accuracy. If estimation shows that gating opportunity X will save twice as much power as gating opportunity Y, you can be pretty sure those two options would rank the same way in final implementation, irrespective of absolute predicted power reduction. And – engineering 101 – you want to focus on bigger savings. The error bars are still big enough you don’t want to waste time on 1% deltas. That said, if you want to delve into tweaking you can improve absolute accuracy in RTL power estimation through correlation with previous similar and implemented designs.
Building on that base you now have two objectives – figuring out where gating has most impact and then figuring out how you should drive that gating. The first takes careful analysis, across the design and across use-case scenarios. Synopsys’ SpyGlass Power has been tuned for many years to help with this task. It starts with a hierarchical spreadsheet view of power, leakage and dynamic, so you can figure out where you want to focus. It’s all neatly color-coded so you can easily spot priority problems then drill down through those to find top offenders and so on down. The tool provides more than 150 metrics so you can slice and dice this however you want.
Some of the metrics called out in the webinar look at efficiency of clock gating. SpyGlass looks at this through several metrics. One, clock gating ratio, is purely structural – how many register clocks (within a block) are actually gated, when you trace back to the root clock for that block? This may be a somewhat crude estimate but it provides a baseline.
Clock gating efficiency is a more refined estimate, requiring activity (simulation) data. Looking at all registers in the block, how many clock toggles occur on those registers versus clock toggles at the root clock? By this metric if a clock on a register toggles a few times versus the root clock, it is efficiently gated. Of course maybe the clock on a particular register has to toggle a lot because data is frequently changing, but this metric still provides a pointer to root cause for dynamic power.
The next two metrics, ROADE™ and ROADF™, are more refined. ROADF considers the number of Q pin toggles versus the number of clock toggles on a register. This is obviously much closer to a measure of ideal efficiency. If Q doesn’t change, in principle the clock didn’t need to toggle. ROADE considers the same measure across all registers sharing a common clock enable, so is a metric by enable signal.
Put these metrics together and you can build a pretty decent sense of where clock gating can have the biggest impact on power. But of course what you are seeing in the dynamic power analysis is metrics for one use-case/scenario; efficiency metrics could change significantly in different use cases.
The next step is how to drive those clock enables, once you have decided which clocks you want to gate. This step was illuminated by a question that came up in the Q&A. Why wouldn’t I just use automatic clock gating where a tool figures out formally or in some other way where best to gate clocks, figures out how to build the enable and maybe even inserts the logic for me? The answer was interesting. There are such tools available and they indeed work but there aren’t getting heavy traction. In practice designers seem to be much more interested in making their own decisions around enabling logic, often factoring in considerations (e.g. boundary use-cases not represented in the scenarios you ran) which simply aren’t visible to a tool.
You can get a lot more detail from the recorded Webinar HERE.