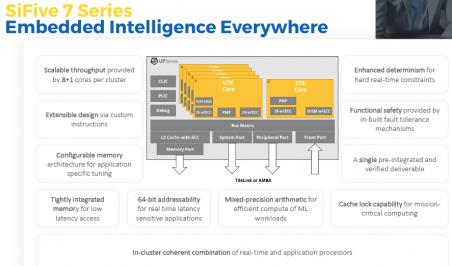
At the recent Linley Fall Processor Conference in Santa Clara, Jack Kang, SiFive’s VP of Product Marketing introduced SiFive’s Core IP 7 Series.Designed to power devices requiring Embedded IntelligenceandIntelligence Everywhere,the cores allow scalability, efficient performance and customization. The Core IP 7 Series is suited for use in consumer devices (AR/VR gaming, wearables), storage and networking (5G, SSD, SAN, NAS) and AI/ML/edge (sensor hubs, gateways, IoT, autonomous machines).
The 7 Series product family includes the E7, S7, and the U7 product series. The E7 Core IP Series comprises the 32-bit E76 and E76-MC and provides hard real-time capabilities. The SiFive Core IP S7 Series brings high-performance 64-bit architectures to the embedded markets with the S76 and S76-MC. The SiFive Core IP U7 Series is a Linux-capable applications processor with a highly configurable memory architecture for domain-specific customization. The 64-bit U74 and U74-MC, like all SiFive U cores, fully support Linux, while the E76, E76-MC, S76, S76-MC support bare metal environments and real-time operating systems.
The broad portfolio of cores enabled by the 7 Series feature low power consumption, 64-bit addressability, tight accelerator coupling, and custom instruction allowance. These features are new to the market and provide the highest performance commercial RISC-V processor IP available today. The SiFive Core IP 7 Series raises the bar with hardware-based, real-time capabilities and unprecedented scalability.
The 7 Series enables the sharing of common features with in-cluster heterogenous compute and allows users to combine E7 and S7 cores with U7 cores in a single coherent operation, thereby greatly easing the software team’s development effort
More specifically the Core IP 7 Series offers:
[table] border=”1″ cellspacing=”0″ cellpadding=”0″
|-
| style=”width: 173px” | Efficient Performance
| style=”width: 204px” | Scalability
| style=”width: 245px” | Feature Set
|-
| style=”width: 173px” | ~60% improvement in CoreMarks/MHz*
| style=”width: 204px” | 8+1 coherent CPUs in
a cluster
| style=”width: 245px” | In-cluster heterogeneous compute for Application + Real-time processors
|-
| style=”width: 173px” | ~40% improvement in DMIPS/MHz*
| style=”width: 204px” | 512 coherent on-chip CPUs via TileLink
| style=”width: 245px” | 64-bit architectures across the portfolio
|-
| style=”width: 173px” | ~10% improvement in Fmax*
| style=”width: 204px” | 2048 multi-socket coherent CPUs via ChipLink
| style=”width: 245px” | Innovative L1 Memory microarchitecture
|-
*Compared to SiFive Core IP 5 series
In storage applications, the 64-bit real-time addressability will be a key feature for big data applications to exploit. In addition, the capability for specific custom instructions will greatly supplement storage, machine learning (ML) and cryptography use cases.
Tightly integrated memories (TIM) and cache lock capabilities will benefit critical real-time workloads in 5G and networking. Configurable memory maps and coherent accelerator ports allow designers to tightly couple storage with specific accelerators. It is also possible to have coherent in-cluster combinations of application processors and real-time processors. Safety applications will be enhanced by ECC capability across the SRAMs as well as significant guarantees around deterministic performance.
AR/VR/sensor fusion applications can combine multiple SiFive Core IP series. For example, the 2, 3, 5 and 7 series can all be flexibly integrated into a single design with tight power constraints. Mixed precision arithmetic accelerates machine learning compute.
Within the 7 Series portfolio, standard cores are offered where existing configurations with known power, performance and area (PPA) may be preferred by customers. Customers will have the option of using the standard cores as silicon verified design start points with the ability to customize the 7 Series core to meet application-specific requirements.
The U7 Series contains
- Heterogenous in-cluster combinations of application processor and real-time processor supported
- Configurable Level 2 cache with cache lock capability and Tightly Integrated Memory (TIM) available
- Functional safety, security and real-time features such as:
o SECDED ECC on all L1 and L2 memories
o PMP and MMU for memory protection
o Programmatically clear and/or disable dynamic branch prediction for deterministic execution and enhanced security
E7, S7, U7 Core Series Architectural Features
- Dual Issue, in-order 8-stage Harvard pipeline
- A very flexible memory system
- Multi-core capable with coherency and optional L2 (E7, S7)
- Deterministic fast interrupt responses
- Higher throughput and efficiency
The E7/S7 Level 1 memory system allows access to large SRAMS that are on the system side and allows other masters on the SoC to access the memory through the main core complex with fast I/O ports ideal for hanging accelerators.
SiFive can aggregate value by giving a single deliverable to customers with all the various desired hardware design options packaged, integrated, and enabled with software development.
During a panel at the Linley Fall Processor Conference, Kang stressed the configurability of the cores, which all have the ability to change branch prediction sizes as well as L1 and L2 memory configurations. The cores can include or exclude single or double-precision floating-point-units and have the ability to add custom extensions. The ability to combine cores in a heterogeneous cluster is a unique differentiator from other core architectures that are not coherent. Kang clarified that, even though internal development is in Chisel, all deliverables to customers are in human-readable Verilog.
I got a chance to have a side chat with Jack Kang, and he clarified that heterogenous operation refers to a mix of SiFive cores from different core series connected together to form a coherent core complex.
Kang added that, even though no single architecture rules them all, customers need general purpose programmability and control. In new AI and ML application domains, vector extensions can be added to provide functionality.
I then asked what constitutes the next success metric in achieving critical mass or adoption. Kang said that the market has started seeing commercial products with RISC-V chips this year. The next phase is then seeing those products being announced, launched, and shipped in volume. The situation today is that companies are hesitant of being first to adopt RISC-V in their industry while simultaneously worrying about being left behind. This has forced many companies to review their RISC-V strategies. Kang’s view is that companies will be late to RISC-V if they do not come in now. Next year, RISC-V products will be out. And since products are trailing indicators, it is a sure sign to move to RISC-V now. Kang sees that companies are not merely replacing designs but are seeking advanced features and choosing RISC-V (and SiFive specifically) because it allows them to tackle unsolved problems.
Kang went on to say that a good architecture serves as table stakes but that there must also be an ecosystem to back it up. RISC-V has an ecosystem that is being globally co-developed by all RISC-V member companies (including the likes of Google and Samsung), not just SiFive (founded in 2015 by the inventors of the RISC-V ISA). The rate of growth of the software ecosystem is high, with Debian and Fedora being ported to RISC-V as evidence of momentum. The ecosystem and tools are rapidly maturing.
I asked Kang if he had a special message to convey. He stated that with the 7 Series, SiFive brings new features, such as in-cluster heterogenous core complexes, that are needed to enable embedded intelligence. The takeaway is that “RISC-V is just not a replacement architecture. It is innovation and customization with new features enabling embedded intelligence and we are starting to see it really take off.”
Other factoids:
– With SCIE (SiFive Custom Instruction Extension) customers can add custom, Verilog-based, instructions which execute in a single cycle or multi-cycle. Some customers can create their own extensions and keep them secret.
– SCIE uses intrinsics for custom instruction generation which decouples custom instructions from specific compiler versions and allows for use with standard GCC and LLVM toolchains.
– SiFive’s RISC-V Core IP will always support the latest RISC-V standard extensions.