A few months ago, I wrote about the announcement of a new digital full flow from Cadence. In that piece, I focused on the machine learning (ML) aspects of the new tool. I had covered a discussion with Cadence’s Paul Cunningham a week before that explored ML in Cadence products, so it was timely to dive into a real-world example of the strategy Paul described. Since then, I also covered a position paper from Cadence on Intelligent System Design, which provides more details on advanced technology and ML for EDA.
The new digital full flow from Cadence is called iSpatial. Beyond ML, it also features unified placement and physical optimization engines that Cadence describes as an industry first. That’s a lot of integrated functionality. Questions that come to mind include:
How does the use model for a new tool like this compare to the prior generation?
How is the workflow different, and what are the benefits of doing things a new way?
I had the opportunity recently to explore these questions with Vivek Mishra, corporate VP, product engineering and Kam Kittrell, senior product management group director in the Digital & Signoff Group at Cadence. I was treated to a detailed tour of the use model for iSpatial and some actual results.
Vivek started our discussion by explaining that a key benefit of a flow like this is superior forward visibility (for the front-end synthesis team). We explored this statement further.
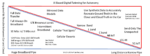
The front-end design team needs to know the power, performance and area of a given design iteration. This information drives optimization, and before iSpatial, the front-end team needed to wait for a completed design iteration from the back-end team to know these results. That could take many days.
Instead, with the iSpatial flow, the front-end design team gets meaningful and actionable information very quickly on things like overall performance, size and power as well as details on items such as routing congestion, critical path delays and clock insertion delays. The information is also presented in a format that is familiar to the front-end design team, avoiding the need to get an interpretation of the data from the back-end team. This contributes to efficiency as well as quality of results.
So, the integrated iSpatial flow minimizes turnaround time and maximizes efficiency for design iterations. But there’s more—the flow can reduce the overall number of design iterations as well. This is one application of ML. In this case, the tool will “learn” from prior design iterations and apply that knowledge in the form of suggestions for the next design iteration. Vivek provided some examples, things like modified pin placement to avoid DRC errors or a different choice of cell library elements that will improve performance. These suggestions are provided in the form of scripts that can be run to implement the various suggestions. This technology can actually help reduce design iterations by avoiding errors, which is headline news from a schedule perspective. Cadence calls these learning and optimization techniques “ML outside”.
There’s another ML use model which applies the technology to the core algorithms to optimize the results achieved. Cadence calls this “ML inside”. I explored some examples of these techniques with Vivek as well. Delay calculation was one we discussed. This is a very iterative and time-consuming process, requiring simulation. ML can optimize this process to increase both the speed of results as well as accuracy. Synthesis mapping is another example, where the best choice for a given implementation can be “learned” to avoid additional iterations.
Kam provided some more color on “ML inside” techniques at Cadence. Consider that many EDA algorithms are iterative in nature and the starting point for those iterations can impact the time to a converged result, or even if there is convergence at all. Finding the right starting point is something of a pattern-matching problem, and ML is quite good at those kinds of tasks.
As a final point, I asked about actual results on real customer designs. Kam reminded me that some detailed statistics were shared in the original press release, an unusual level of detail for a press release actually. MediaTek reported, “… we were able to automatically and quickly train a model of our CPU core, which resulted in an improved maximum frequency along with an 80% reduction in total negative slack. This enabled 2X shorter turnaround time for final signoff design closure.”
Samsung Electronics reported, “(iSpatial) enabled us to achieve 3X faster design turnaround time by quickly iterating on RTL, constraints and floorplan while improving total power by 6%. Furthermore, Cadence’s unique ML capabilities allowed us to train a model of our design on Samsung Foundry’s 4nm EUV node, which helped us further achieve a 5% performance improvement and 5% leakage power savings.”
Kam further mentioned that on several advanced customer designs, a double-digit total negative slack (TNS) improvement, often 50 percent or more, was achieved. On these same designs, power was improved by 1 to 3.5 percent. If you consider that a design team could spend months looking for a three percent power improvement, these numbers are quite impressive. Kam also explained that design groups using older technology nodes are also seeing benefits from the new flow in terms of reduced design iterations and a more finely tuned methodology.
At this point, I felt like I had seen the future (of chip design). You can learn more about the Cadence suite of digital design and signoff products here.