

The good news is that as a part of SemiWiki we get free media passes to all of the cool conferences. The bad news is that our inboxes get flooded with announcements. ARM TechCon is next week and my delete button is on overtime but it is interesting to see who is active in conferences and who is not. In this case Xilinx is very active and Altera… Read More
 CEO Interview with Dr. Maksym Plakhotnyuk of ATLANT 3DDr. Maksym Plakhotnyuk, is the CEO and Founder…Read More
CEO Interview with Dr. Maksym Plakhotnyuk of ATLANT 3DDr. Maksym Plakhotnyuk, is the CEO and Founder…Read More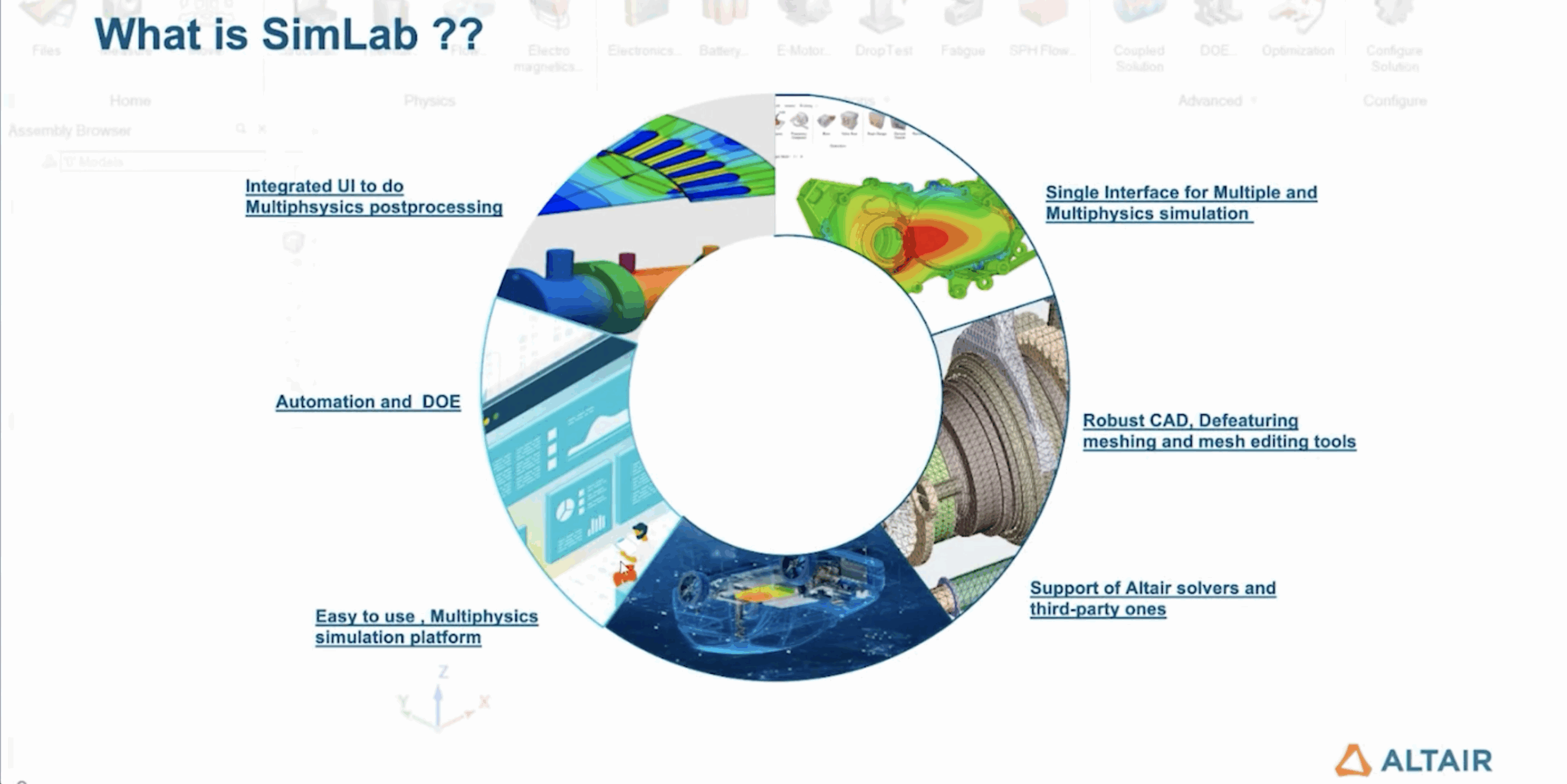 Altair SimLab: Tackling 3D IC Multiphysics Challenges for Scalable ECAD ModelingThe semiconductor industry is rapidly moving beyond traditional…Read More
Altair SimLab: Tackling 3D IC Multiphysics Challenges for Scalable ECAD ModelingThe semiconductor industry is rapidly moving beyond traditional…Read More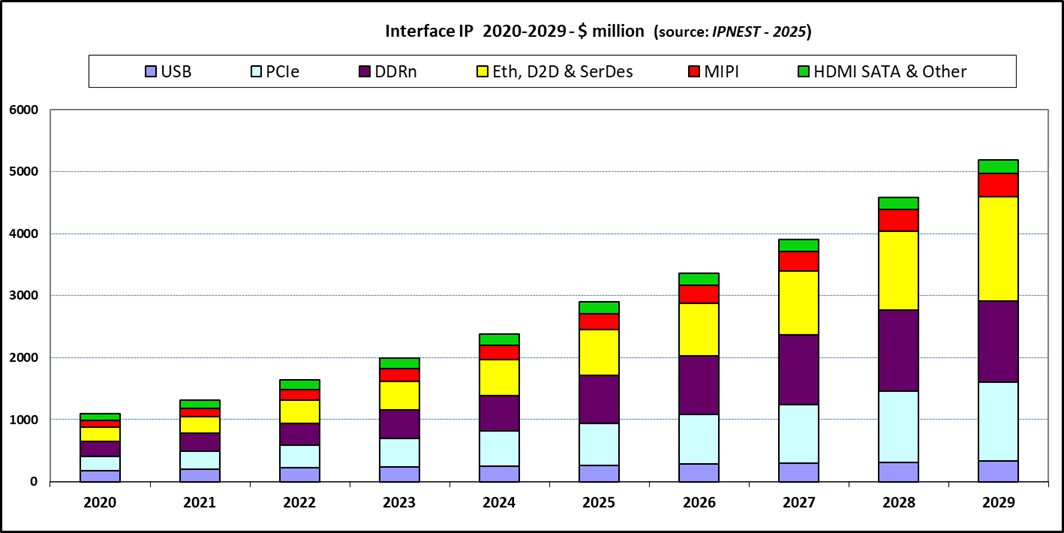 AI Booming is Fueling Interface IP 23.5% YoY GrowthAI explosion is clearly driving semi-industry since 2020.…Read More
AI Booming is Fueling Interface IP 23.5% YoY GrowthAI explosion is clearly driving semi-industry since 2020.…Read More
SiC and Si Power Devices
ICs for consumer electronics are often battery powered, which are considered low voltage designs. On the other end of the IC spectrum are high voltage devices used in many industrial applications like: automotive, aerospace, data centers, transportation and power generation. … Read More
Mentor at TSMC OIP, 16nm, and 10nm

On Tuesday, September 30, TSMC hosts another Open Innovation Platform Ecosystem forum at the San Jose Convention Center. Have you registered? This year includes 30 technical sessions from TSMC’s ecosystem partners, divided into three separate tracks. I’ll be hanging out in the EDA track, listening to various takes on 16nm FinFET… Read More
Synopsys Verification Continuum

Verification spans a number of different technologies, from virtual platforms, RTL simulation, formal techniques, emulation and FPGA prototyping. Going back a few years, most of these technologies came from separate companies and one effect of this was that moving the design from one verification environment to another required… Read More
Dominating FPGA clock domains and CDCs
Multiple clock domains in FPGAs have simplified some aspects of designs, allowing effective partitioning of logic. As FPGA architectures get more flexible in how clock domains, regions, or networks are available, the probability of signals crossing clock domains has gone way up.… Read More
Coverage Driven Verification for Analog?
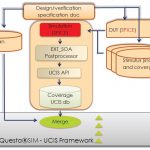
We know there is a big divide between analog and digital design methodologies, level of automation, validation and verification processes, yet they cannot stay without each other because any complete system on a chip (SoC) demands them to be together. And therefore, there are different methodologies on the floor to combine analog… Read More
Electro-Thermal Simulation of Power Transistors
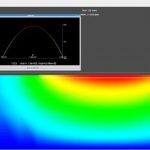
Power transistors are commonly used in applications like: hybrid vehicles, electric vehicles, automotive, home appliances, LED lighting, TVs, power and energy. In the old days an engineering team could build their device with power transistors, then after production run some thermal testing to see if they guessed the proper… Read More
TSMC Delivers First FinFET ARM Based SoC!
Right on cue, TSMC announces 16nm FinFET production silicon. I believe this is the original version of FinFET versus 16FF+ which is due out in 1H 2015. I will confirm this next week at the TSMC OIP event in San Jose, absolutely. Either way this is excellent news for the fabless semiconductor ecosystem and I look forward to the first … Read More
Atmel Expands Wireless Portfolio
Recently someone described the Internet of Things (IoT) as being the semiconductor classification that we used to call ‘other’. It’s a nice line but actually I think IoT really is something different from what we were already doing before. Although it is a market that cuts across medical, automotive, home-electronics,… Read More
Strategic Materials Conference
SEMI’s Strategic Materials Conference is coming up fast, on September 30th and October 1st next week at the Biltmore in Santa Clara. This year’s theme, Materials Matter—Enabling the Future of IC Fabrication and Packaging, will take a broad look at what is driving the demand for new materials, and how material suppliers … Read More
TSMC N3 Process Technology Wiki