
")
The growing demand for high-performance AI applications continues to drive innovation in CPU architecture design. As machine learning workloads, particularly convolutional neural networks (CNNs), become more computationally intensive, architects face the challenge of delivering performance improvements while maintaining efficiency and flexibility. Our upcoming webinar unveils a cutting-edge solution—a novel architecture that introduces advanced matrix extensions and custom quantization instructions tailored for RISC-V CPUs, setting a new benchmark for CNN acceleration.
Breaking New Ground with Scalable and Portable Design
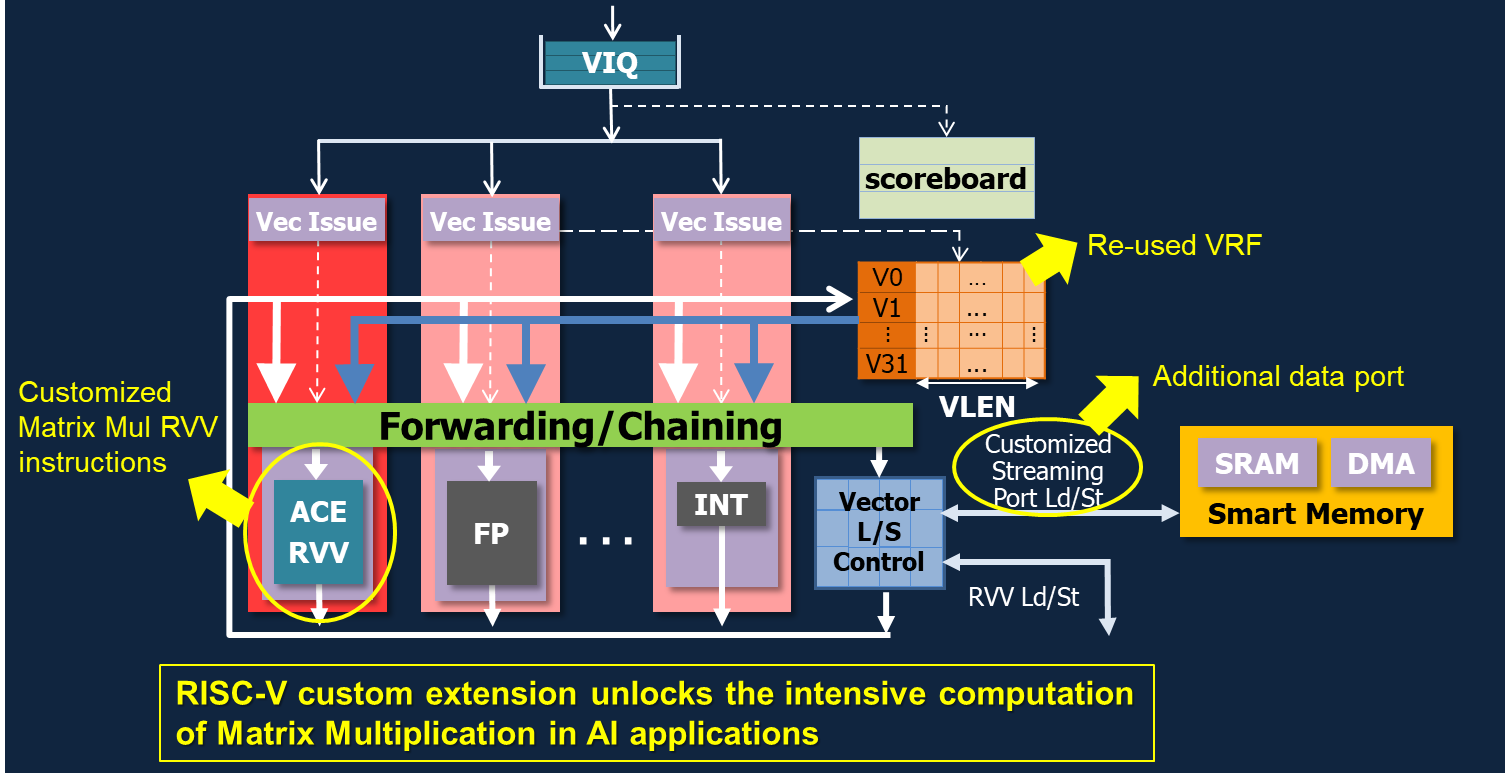
At the heart of this innovation lies the development of scalable, VLEN-agnostic matrix multiplication/accumulation instructions. These instructions are carefully designed to maintain consistent performance across varying vector lengths, ensuring portability across different hardware configurations. By targeting both computational capacity and memory efficiency, the architecture achieves significant improvements in compute intensity while reducing memory bandwidth demands.
This scalability makes it an ideal solution for hardware vendors and system architects looking to optimize their CNN workloads without being locked into specific hardware constraints. Whether you are working with smaller, embedded systems or high-performance data center environments, this design ensures robust and adaptable performance gains.
Advanced Memory Management and Efficiency Enhancements
To further elevate performance, the architecture introduces a 2D load/store unit (LSU) that optimizes matrix tiling. This innovation significantly reduces memory access overhead by efficiently handling matrix data during computations. Additionally, Zero-Overhead Boundary handling ensures minimal user configuration cycles, simplifying the process for developers while maximizing resource utilization.
These advancements collectively deliver smoother and faster CNN processing, enhancing both usability and computational efficiency. This improved memory management directly contributes to the architecture’s superior compute intensity metrics, which reach up to an impressive 9.6 for VLEN 512 configurations.
Accelerating CNNs with New Quantization Instructions
A key highlight of this architecture is the introduction of a custom quantization instruction, designed to further enhance CNN computational speed and efficiency. This instruction streamlines data processing in quantized neural networks, reducing latency and power consumption while maintaining accuracy. The result is a marked improvement in CNN performance, with acceleration demonstrated in both GeMM and CNN-specific workloads.
Preliminary results reveal that kernel loop MAC utilization exceeds 75%, a testament to the architecture’s capability to maximize processing power and efficiency. These metrics are bolstered by sophisticated software unrolling techniques, which optimize data flow and computation patterns to push performance even further.
Join Us to Explore the Future of RISC-V AI Performance
This breakthrough architecture showcases the vast potential of RISC-V CPUs in tackling today’s AI challenges. By integrating novel matrix extensions, custom instructions, and advanced memory management strategies, it delivers a future-ready platform for CNN acceleration.
Whether you’re a hardware designer, software developer, or AI engineer, this webinar offers invaluable insights into how you can leverage this new architecture to revolutionize your CNN applications. Don’t miss this opportunity to stay ahead of the curve in AI processing innovation.
Andes Technology Corporation
After 16 years effort starting from scratch, Andes Technology Corporation is now a leading embedded processor intellectual property supplier in the world. We devote ourselves in developing high-performance/low-power 32/64 bit processors and their associated SoC platforms to serve the rapidly growing embedded system applications worldwide.
Also Read:
Changing RISC-V Verification Requirements, Standardization, Infrastructure
The RISC-V and Open-Source Functional Verification Challenge
Share this post via:



Comments
There are no comments yet.
You must register or log in to view/post comments.