


Tom Feist of Xilinx presented here at the GlobalPress Electronics Summit about their strategy to take design abstraction up another level. In the SoC world, we are still pretty much stuck at the RTL level and have moved to higher abstractions by using an IP strategy. But at least all IC designers are RTL-literate.

Xilinx, in the Vivado suite, also has an IP strategy supported by tools that help pull everything together and make sure that you can’t make stupid mistakes by mis-connecting the wrong inputs and outputs. But they also have another problem: increasingly, the people that they want to target to use FPGAs don’t know RTL. They are working at the C level or the C++ level. Or they are using Mathworks. Or labview. Or openCL, a standard for parallel programming (and GPU programming).
The grand vision is to enable these people to go directly from whatever environment they are in, directly to the bitstream that programs the FPGA and the software that runs on the processor embedded in the FPGA. Of course, under the hood, there will be RTL generated and then the normal synthesis and P&R will be run. But this will be hidden from the user in much the same way that a C programmer doesn’t need to understand x86 assembly code or even ever see it.
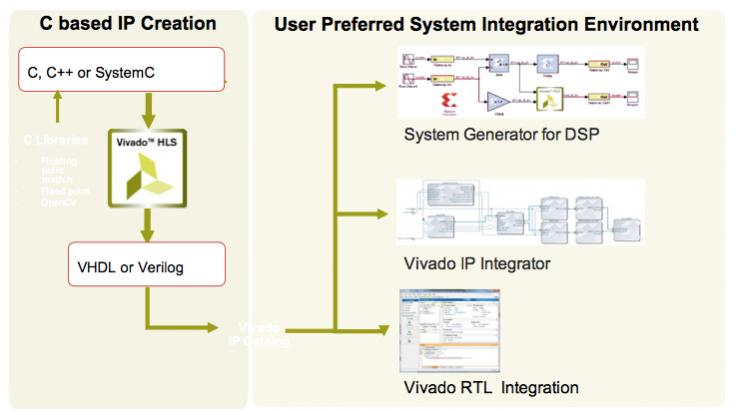
From C, C++ and SystemC the route is using Vivado HLS (which is the next generation of the AutoESL technology that Xilinx acquired a couple of years ago). Mathworks already has the capability to generate C and Verilog. Labview (from National Instruments) are working to embed Xilinx’s Vivado under the hood so that designers can go straight from their labview environment to FPGA without ever leaving the environment. The idea is to push design up to the system level and regard RTL as a sort of “intermediate code” that most users will never see.
In addition, they are adding libraries starting with OpenCV (computer vision) and some other video libraries. This is a library of algorithms for (surprise) computer vision. But they will be available both as callable software procedures or as FPGA subsystems. Depending on the performance required the algorithms will run either as software or as designs optimized into the FPGA fabric for much higher performance. I’m not sure if the plan is to pre-create these or whether the C-code is simply run through HLS on the fly.
It is a bold strategy to push design up to the system level. C-based HLS has a reputation for being a bit tricky to use, not all C just runs cleanly through and produces a good implementation. But Xilinx have 350 customers using it and another 1000 evaluating it, so that’s a pretty sizable installed base. I’m not sure if 350 customers means 350 different companies or 350 copies installed.

Ivo Bolens, CTO of Xilinx, will also cover some of the same ground at the EDPS in Monterey on Thursday morning. You can read my preview of his keynote here.
EDPS Thursday and Friday, April 18th and 19th. The full program is here. Registration is hereand use the promo code SemiWiki-EDPS-JFR to save $50. Call the hotel directly for room reservations.





Musk’s Orbital Compute Vision: TERAFAB and the End of the Terrestrial Data Center