
I’m developing a taste for user-group meetings. In my (fairly) recently assumed role as a member of the media, I’m only allowed into the keynotes, but from what I have seen, vendors work hard to make these fresh and compelling each year through big-bang product updates and industry/academic leaders talking about their work in bleeding-edge system development. Cadence continued the theme this year with a packed 90 minutes of talks to an equally packed room at the Santa Clara Convention Center.

Lip Bu opened with “Enabling the Intelligent Connected World.” There’s a lot packed into that title. EDA/IP is enabling rather than creating that world, but the world wouldn’t be possible without what EDA and IP make possible. It’s intelligent because AI and machine learning are exploding, and it’s connected because focus has dramatically shifted from point-system compute to clouds, gateways and edges.
He sees massive potential for design and EDA, particularly around connected cars, the industrial IoT (IIoT) and cloud datacenters. As both the president and CEO of Cadence and head of Walden International (a VC company), he sees several important trends in these areas. The deep-learning revolution—moving from training machines to learn, to teaching them to infer (using that learning in the field)—is creating strong demand to differentiate through specialized engines (witness the Google Tensor Processing Unit). Roles between cloud, gateway and edge have shifted; where once we thought all the heavy-lifting would be done in the cloud, now we are realizing that latency has become critical, making it important that intelligence, data filtering, analytics and security be moved as close to the edge as much as possible.
All of this creates new design and EDA challenges from sensors all the way up to the cloud. At the edge, more compute for all those latency-critical functions demands more performance without compromising power or thermal integrity. In the cloud, even more compute and data management is required for innovative (massively reprogrammable, reconfigurable) designs packed into small spaces. Power and thermal integrity are exceptionally important here, as they are (even more so) in automotive applications where critical electronics is expected to function reliably for 15 or more years.
Lip-Bu recapped several areas where Cadence has been investing and continues to invest, but this is a long blog, so I’ll just mention a couple. One notable characteristic is Lip-Bu’s move away from M&A towards predominantly organic growth. There are arguments for both, but I can vouch for the organic style building exceptional loyalty, strength and depth in the team, which seems to be paying off for Cadence. Also, Lip-Bu said that 35% of revenue in Cadence goes to R&D—an eye-opener for me. I remember the benchmark being around 20% to keep investors happy. I now understand why Cadence can pump out so many new products.
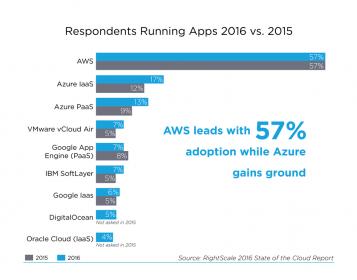
Next up was Kushagra Vaid, GM of Azure Hardware Infrastructure at Microsoft. Azure is a strong player in cloud; while Amazon dominates with AWS, notice the second and third bars above are for Azure – added together, Azure stands at nearly 50% of AWS usage. This is big business (AWS is the 6[SUP]th[/SUP] largest business in the US by one estimate), set to get much bigger. Kushagra noted that there are about a billion servers in datacenters across the world, representing billions of dollars in infrastructure investment, and this is before the IoT has really scaled up. Microsoft is a strong contender in this game and is serious about grabbing a bigger share through differentiated capabilities.

The challenge is that these clouds need to service an immense range of demands, from effectively bare-metal access (you do everything), to infrastructure as a service (IaaS), platform as a service (PaaS) and software as a service (SaaS). They must provide a huge range of services from web apps to container, datalakes, Hadoop, analytics, IoT services, cognitive services and on and on. He showed a dense slide (which unfortunately I can’t show here) listing a representative set, summing it up by saying that clouds had become the Noah’s Arks of service, hosting every imaginable species. Bit of a shock for those of us who thought clouds were mostly about virtualization. He also mentioned something that may make your head hurt—serverless compute (as if the cloud weren’t already virtual enough). This is a service to handle event-driven activity, especially for the IoT where a conventional pay-as-you-go service may not be cost-effective.
While news of the death of Moore’s law may be premature, designers of these systems don’t care. They must accelerate performance (TOPS, TOPS/W, TOPS/W/$, whatever metric is relevant) far beyond silicon and von Neumann possibilities. This is what drives what he called a Cambrian explosion in purpose-built accelerators tailored to workloads. Massive and distributed data requires that compute move closer to data, while deep learning requires specialized hardware, especially in inference where low power and low latency are critical. Advances in techniques for search, the ever-moving security objective, and compression to speed data transfers, all demand specialized hardware.
The Azure hardware team response is interesting; they have built a server platform, under the Olympus project, based on CPUs, GPUs and an FPGA (per server), and have donated the architecture to the Open Compute Project (OCP). I have mentioned before that this is no science experiment. Kushagra notes that this is now the world’s largest FPGA-based distributed compute fabric. He also mentioned that innovations like this will almost certainly appear first in the cloud because of the scale. In a sense, the cloud has become the new technology driver.
Kushagra closed with some comments on machine-learning opportunities in EDA, mentioning routing-friendly power-distribution networks, static timing optimization, congestion improvement in physical designs and support for improving diagnostic accuracy in chip test. He’s also a big fan of cloud-based EDA services, stressing that scalability in the cloud, without needing to worry about provisioning infrastructure, aids faster experimentation and greater agility in design options and faster time to delivery. Of course, there are still concerns about public clouds versus private clouds, but from what I hear, it’s becoming easier to have it both ways using restricted-access services with high security to handle peak demand (and see my note near the end on Pegasus in the cloud). All of this seems in line with cloud-based access directions Lip Bu mentioned.
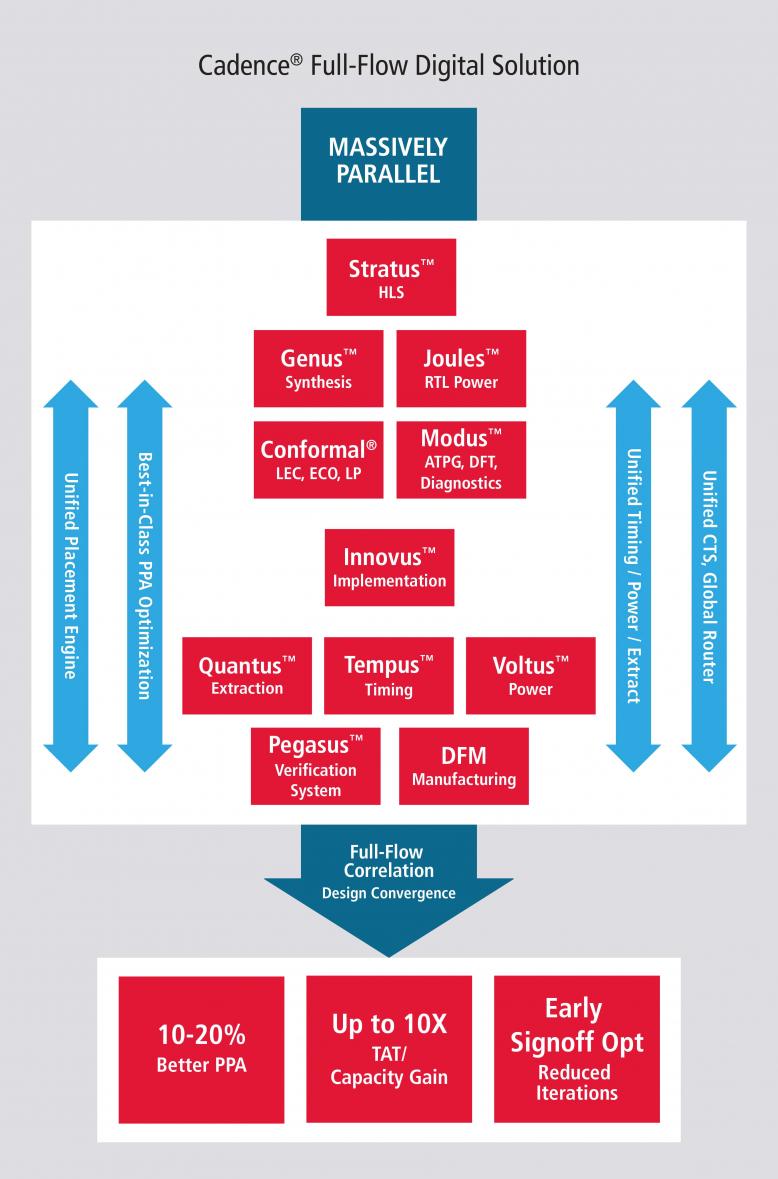
Last up was Anirudh, who was responsible for the big bang product news, and he, of course, delivered—this time for the digital implementation flow. First, he talked about massive parallelization and the flow between the Genus (synthesis), Innovus (implementation), Tempus (timing) and Voltus (power integrity) solutions. Cadence has already made good progress on big parallelization for most of the flow but implementation has been hard to scale beyond around 8 CPUs. Next month, a new digital and signoff software release will be rolled out, which can scale up to multiple machines, also delivering a 1.5-2X speedup on a single machine, in some cases with improved PPA (this “more speed though parallelization, also faster on a single CPU” thing seems to be an Anirudh specialty).
Continuing his theme of fast and smart, he talked about ramping up intelligence in implementation. Here they have already demonstrated an ability for machine learning to drive an improvement of PPA through a 12% reduction in total negative slack. This capability is not yet released but is indicative of work being done in this area. Anirudh mentioned floorplanning, placement, CTS and routing as other areas that can benefit from machine-learning-based optimization.
Finally, the really big bang was his introduction of the Pegasus Verification System, the new and massively parallel full-flow physical verification solution. Daniel Payne wrote a detailed blog on this topic, so I won’t repeat what he had to say. The main point is that this is a ground-up re-design for massive and scalable cloud-based parallelism. If you want to keep costs down and run on one machine, you can run on one machine. If you’re pushing to tape out and iterating through multiple signoff and ECO runs, you can scale to a thousand machines or more and complete runs in hours rather than days. On that cost point, he cited one example of a run that used to take 40 hours, which now runs on AWS in a few hours, for $200 per run (Pegasus not included). I think that datapoint alone may change some business views on the pros and cons of running in public clouds.
A lot of information here. Sorry about the long blog, but I think you’ll agree it’s all good stuff. I just didn’t know how to squeeze it into 800 words.
Share this post via:



Comments
0 Replies to “The CDNLive Keynotes”
You must register or log in to view/post comments.