Threads
XF\Mvc\Entity\ArrayCollection Object
(
[entities:protected] => Array
(
[24989] => ThemeHouse\XPress\XF\Entity\Thread Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 57
[rootClass:protected] => XF\Entity\Thread
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[thread_id] => 24989
[node_id] => 2
[title] => South Korea’s K-shaped economy where chip giants give out $1 million bonuses to staff
[reply_count] => 5
[view_count] => 1178
[user_id] => 20231
[username] => Barnsley
[post_date] => 1777001445
[sticky] => 0
[discussion_state] => visible
[discussion_open] => 1
[discussion_type] => discussion
[first_post_id] => 99412
[first_post_reaction_score] => 0
[first_post_reactions] => []
[last_post_date] => 1777323278
[last_post_id] => 99485
[last_post_user_id] => 35301
[last_post_username] => Xebec
[prefix_id] => 0
[tags] => []
[custom_fields] => []
[vote_score] => 0
[vote_count] => 0
[featured] => 0
[type_data] => []
[index_state] => default
)
[_relations:protected] => Array
(
[User] => ThemeHouse\XLink\XF\Entity\User Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 54
[rootClass:protected] => XF\Entity\User
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[user_id] => 20231
[username] => Barnsley
[username_date] => 0
[username_date_visible] => 0
[email] => apickering72@gmail.com
[custom_title] =>
[language_id] => 1
[style_id] => 0
[style_variation] =>
[timezone] => Asia/Irkutsk
[visible] => 1
[activity_visible] => 1
[user_group_id] => 2
[secondary_group_ids] =>
[display_style_group_id] => 2
[permission_combination_id] => 8
[message_count] => 1444
[question_solution_count] => 0
[conversations_unread] => 0
[register_date] => 1429440429
[last_activity] => 1777292876
[last_summary_email_date] => 1653315673
[trophy_points] => 113
[alerts_unviewed] => 4
[alerts_unread] => 4
[avatar_date] => 0
[avatar_width] => 0
[avatar_height] => 0
[avatar_highdpi] => 0
[avatar_optimized] => 0
[gravatar] =>
[user_state] => valid
[security_lock] =>
[is_moderator] => 0
[is_admin] => 0
[is_banned] => 0
[reaction_score] => 758
[warning_points] => 0
[is_staff] => 0
[secret_key] => iAnkz9GTDfivRmH1BOp6OTrgESJR57G8
[privacy_policy_accepted] => 0
[terms_accepted] => 0
[vote_score] => 0
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[Forum] => XF\Entity\Forum Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 56
[rootClass:protected] => XF\Entity\Forum
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[discussion_count] => 8563
[message_count] => 62673
[last_post_id] => 99485
[last_post_date] => 1777323278
[last_post_user_id] => 35301
[last_post_username] => Xebec
[last_thread_id] => 24989
[last_thread_title] => South Korea’s K-shaped economy where chip giants give out $1 million bonuses to staff
[last_thread_prefix_id] => 0
[moderate_threads] => 0
[moderate_replies] => 0
[allow_posting] => 1
[count_messages] => 1
[auto_feature] => 0
[find_new] => 1
[allow_index] => allow
[index_criteria] =>
[field_cache] => []
[prefix_cache] => []
[prompt_cache] => []
[default_prefix_id] => 0
[default_sort_order] => last_post_date
[default_sort_direction] => desc
[list_date_limit_days] => 0
[require_prefix] => 0
[allowed_watch_notifications] => all
[min_tags] => 0
[forum_type_id] => discussion
[type_config] => {"allowed_thread_types":["poll"]}
)
[_relations:protected] => Array
(
[Node] => XF\Entity\Node Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 55
[rootClass:protected] => XF\Entity\Node
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[title] => SemiWiki Main Forum ( Ask the Experts! )
[description] => Post your questions to the experts here!
[node_name] =>
[node_type_id] => Forum
[parent_node_id] => 1
[display_order] => 1
[display_in_list] => 1
[lft] => 2
[rgt] => 3
[depth] => 1
[style_id] => 0
[effective_style_id] => 0
[breadcrumb_data] => {"1":{"node_id":1,"title":"Main Category","depth":0,"lft":1,"node_name":null,"node_type_id":"Category","display_in_list":true}}
[navigation_id] =>
[effective_navigation_id] =>
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[25003] => ThemeHouse\XPress\XF\Entity\Thread Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 61
[rootClass:protected] => XF\Entity\Thread
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[thread_id] => 25003
[node_id] => 2
[title] => The Inference Optimization Battle
[reply_count] => 0
[view_count] => 113
[user_id] => 1305
[username] => KevinK
[post_date] => 1777311317
[sticky] => 0
[discussion_state] => visible
[discussion_open] => 1
[discussion_type] => discussion
[first_post_id] => 99484
[first_post_reaction_score] => 1
[first_post_reactions] => {"1":1}
[last_post_date] => 1777311317
[last_post_id] => 99484
[last_post_user_id] => 1305
[last_post_username] => KevinK
[prefix_id] => 0
[tags] => []
[custom_fields] => []
[vote_score] => 0
[vote_count] => 0
[featured] => 0
[type_data] => []
[index_state] => default
)
[_relations:protected] => Array
(
[User] => ThemeHouse\XLink\XF\Entity\User Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 58
[rootClass:protected] => XF\Entity\User
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[user_id] => 1305
[username] => KevinK
[username_date] => 0
[username_date_visible] => 0
[email] => kevin@kranen.com
[custom_title] =>
[language_id] => 1
[style_id] => 0
[style_variation] =>
[timezone] => America/Los_Angeles
[visible] => 1
[activity_visible] => 1
[user_group_id] => 2
[secondary_group_ids] =>
[display_style_group_id] => 2
[permission_combination_id] => 8
[message_count] => 767
[question_solution_count] => 0
[conversations_unread] => 0
[register_date] => 1307041560
[last_activity] => 1777319282
[last_summary_email_date] => 1657203603
[trophy_points] => 93
[alerts_unviewed] => 2
[alerts_unread] => 2
[avatar_date] => 0
[avatar_width] => 0
[avatar_height] => 0
[avatar_highdpi] => 0
[avatar_optimized] => 0
[gravatar] =>
[user_state] => valid
[security_lock] =>
[is_moderator] => 0
[is_admin] => 0
[is_banned] => 0
[reaction_score] => 882
[warning_points] => 0
[is_staff] => 0
[secret_key] => d8MK99Btn0vCdz0LAv6U6Lcg678TyqUf
[privacy_policy_accepted] => 0
[terms_accepted] => 0
[vote_score] => 0
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[Forum] => XF\Entity\Forum Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 56
[rootClass:protected] => XF\Entity\Forum
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[discussion_count] => 8563
[message_count] => 62673
[last_post_id] => 99485
[last_post_date] => 1777323278
[last_post_user_id] => 35301
[last_post_username] => Xebec
[last_thread_id] => 24989
[last_thread_title] => South Korea’s K-shaped economy where chip giants give out $1 million bonuses to staff
[last_thread_prefix_id] => 0
[moderate_threads] => 0
[moderate_replies] => 0
[allow_posting] => 1
[count_messages] => 1
[auto_feature] => 0
[find_new] => 1
[allow_index] => allow
[index_criteria] =>
[field_cache] => []
[prefix_cache] => []
[prompt_cache] => []
[default_prefix_id] => 0
[default_sort_order] => last_post_date
[default_sort_direction] => desc
[list_date_limit_days] => 0
[require_prefix] => 0
[allowed_watch_notifications] => all
[min_tags] => 0
[forum_type_id] => discussion
[type_config] => {"allowed_thread_types":["poll"]}
)
[_relations:protected] => Array
(
[Node] => XF\Entity\Node Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 55
[rootClass:protected] => XF\Entity\Node
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[title] => SemiWiki Main Forum ( Ask the Experts! )
[description] => Post your questions to the experts here!
[node_name] =>
[node_type_id] => Forum
[parent_node_id] => 1
[display_order] => 1
[display_in_list] => 1
[lft] => 2
[rgt] => 3
[depth] => 1
[style_id] => 0
[effective_style_id] => 0
[breadcrumb_data] => {"1":{"node_id":1,"title":"Main Category","depth":0,"lft":1,"node_name":null,"node_type_id":"Category","display_in_list":true}}
[navigation_id] =>
[effective_navigation_id] =>
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[25002] => ThemeHouse\XPress\XF\Entity\Thread Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 65
[rootClass:protected] => XF\Entity\Thread
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[thread_id] => 25002
[node_id] => 2
[title] => Siemens will close most of its 53-acre Oregon campus, shut its childcare center
[reply_count] => 0
[view_count] => 114
[user_id] => 5
[username] => Daniel Nenni
[post_date] => 1777310072
[sticky] => 0
[discussion_state] => visible
[discussion_open] => 1
[discussion_type] => discussion
[first_post_id] => 99483
[first_post_reaction_score] => 0
[first_post_reactions] => []
[last_post_date] => 1777310072
[last_post_id] => 99483
[last_post_user_id] => 5
[last_post_username] => Daniel Nenni
[prefix_id] => 0
[tags] => []
[custom_fields] => []
[vote_score] => 0
[vote_count] => 0
[featured] => 0
[type_data] => []
[index_state] => default
)
[_relations:protected] => Array
(
[User] => ThemeHouse\XLink\XF\Entity\User Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 62
[rootClass:protected] => XF\Entity\User
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[user_id] => 5
[username] => Daniel Nenni
[username_date] => 0
[username_date_visible] => 0
[email] => dnenni@semiwiki.com
[custom_title] => Founder
[language_id] => 1
[style_id] => 0
[style_variation] =>
[timezone] => America/Los_Angeles
[visible] => 1
[activity_visible] => 1
[user_group_id] => 3
[secondary_group_ids] => 4,5,132
[display_style_group_id] => 3
[permission_combination_id] => 88
[message_count] => 15512
[question_solution_count] => 0
[conversations_unread] => 0
[register_date] => 1280720820
[last_activity] => 1777310075
[last_summary_email_date] => 1605968657
[trophy_points] => 113
[alerts_unviewed] => 77
[alerts_unread] => 77
[avatar_date] => 1663211649
[avatar_width] => 110
[avatar_height] => 107
[avatar_highdpi] => 0
[avatar_optimized] => 0
[gravatar] =>
[user_state] => valid
[security_lock] =>
[is_moderator] => 1
[is_admin] => 1
[is_banned] => 0
[reaction_score] => 9399
[warning_points] => 0
[is_staff] => 1
[secret_key] => 0HwyUVVHCwJotUUVEpvqAclfYJdGNPpw
[privacy_policy_accepted] => 0
[terms_accepted] => 0
[vote_score] => 0
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[Forum] => XF\Entity\Forum Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 56
[rootClass:protected] => XF\Entity\Forum
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[discussion_count] => 8563
[message_count] => 62673
[last_post_id] => 99485
[last_post_date] => 1777323278
[last_post_user_id] => 35301
[last_post_username] => Xebec
[last_thread_id] => 24989
[last_thread_title] => South Korea’s K-shaped economy where chip giants give out $1 million bonuses to staff
[last_thread_prefix_id] => 0
[moderate_threads] => 0
[moderate_replies] => 0
[allow_posting] => 1
[count_messages] => 1
[auto_feature] => 0
[find_new] => 1
[allow_index] => allow
[index_criteria] =>
[field_cache] => []
[prefix_cache] => []
[prompt_cache] => []
[default_prefix_id] => 0
[default_sort_order] => last_post_date
[default_sort_direction] => desc
[list_date_limit_days] => 0
[require_prefix] => 0
[allowed_watch_notifications] => all
[min_tags] => 0
[forum_type_id] => discussion
[type_config] => {"allowed_thread_types":["poll"]}
)
[_relations:protected] => Array
(
[Node] => XF\Entity\Node Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 55
[rootClass:protected] => XF\Entity\Node
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[title] => SemiWiki Main Forum ( Ask the Experts! )
[description] => Post your questions to the experts here!
[node_name] =>
[node_type_id] => Forum
[parent_node_id] => 1
[display_order] => 1
[display_in_list] => 1
[lft] => 2
[rgt] => 3
[depth] => 1
[style_id] => 0
[effective_style_id] => 0
[breadcrumb_data] => {"1":{"node_id":1,"title":"Main Category","depth":0,"lft":1,"node_name":null,"node_type_id":"Category","display_in_list":true}}
[navigation_id] =>
[effective_navigation_id] =>
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[22919] => ThemeHouse\XPress\XF\Entity\Thread Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 69
[rootClass:protected] => XF\Entity\Thread
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[thread_id] => 22919
[node_id] => 2
[title] => AMD Acquires Silicon Photonics Startup Enosemi In AI Systems Push
[reply_count] => 3
[view_count] => 2332
[user_id] => 5
[username] => Daniel Nenni
[post_date] => 1748475323
[sticky] => 0
[discussion_state] => visible
[discussion_open] => 1
[discussion_type] => discussion
[first_post_id] => 86779
[first_post_reaction_score] => 0
[first_post_reactions] => []
[last_post_date] => 1777310054
[last_post_id] => 99482
[last_post_user_id] => 396
[last_post_username] => swka
[prefix_id] => 0
[tags] => []
[custom_fields] => []
[vote_score] => 0
[vote_count] => 0
[featured] => 0
[type_data] => []
[index_state] => default
)
[_relations:protected] => Array
(
[User] => ThemeHouse\XLink\XF\Entity\User Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 62
[rootClass:protected] => XF\Entity\User
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[user_id] => 5
[username] => Daniel Nenni
[username_date] => 0
[username_date_visible] => 0
[email] => dnenni@semiwiki.com
[custom_title] => Founder
[language_id] => 1
[style_id] => 0
[style_variation] =>
[timezone] => America/Los_Angeles
[visible] => 1
[activity_visible] => 1
[user_group_id] => 3
[secondary_group_ids] => 4,5,132
[display_style_group_id] => 3
[permission_combination_id] => 88
[message_count] => 15512
[question_solution_count] => 0
[conversations_unread] => 0
[register_date] => 1280720820
[last_activity] => 1777310075
[last_summary_email_date] => 1605968657
[trophy_points] => 113
[alerts_unviewed] => 77
[alerts_unread] => 77
[avatar_date] => 1663211649
[avatar_width] => 110
[avatar_height] => 107
[avatar_highdpi] => 0
[avatar_optimized] => 0
[gravatar] =>
[user_state] => valid
[security_lock] =>
[is_moderator] => 1
[is_admin] => 1
[is_banned] => 0
[reaction_score] => 9399
[warning_points] => 0
[is_staff] => 1
[secret_key] => 0HwyUVVHCwJotUUVEpvqAclfYJdGNPpw
[privacy_policy_accepted] => 0
[terms_accepted] => 0
[vote_score] => 0
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[Forum] => XF\Entity\Forum Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 56
[rootClass:protected] => XF\Entity\Forum
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[discussion_count] => 8563
[message_count] => 62673
[last_post_id] => 99485
[last_post_date] => 1777323278
[last_post_user_id] => 35301
[last_post_username] => Xebec
[last_thread_id] => 24989
[last_thread_title] => South Korea’s K-shaped economy where chip giants give out $1 million bonuses to staff
[last_thread_prefix_id] => 0
[moderate_threads] => 0
[moderate_replies] => 0
[allow_posting] => 1
[count_messages] => 1
[auto_feature] => 0
[find_new] => 1
[allow_index] => allow
[index_criteria] =>
[field_cache] => []
[prefix_cache] => []
[prompt_cache] => []
[default_prefix_id] => 0
[default_sort_order] => last_post_date
[default_sort_direction] => desc
[list_date_limit_days] => 0
[require_prefix] => 0
[allowed_watch_notifications] => all
[min_tags] => 0
[forum_type_id] => discussion
[type_config] => {"allowed_thread_types":["poll"]}
)
[_relations:protected] => Array
(
[Node] => XF\Entity\Node Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 55
[rootClass:protected] => XF\Entity\Node
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[title] => SemiWiki Main Forum ( Ask the Experts! )
[description] => Post your questions to the experts here!
[node_name] =>
[node_type_id] => Forum
[parent_node_id] => 1
[display_order] => 1
[display_in_list] => 1
[lft] => 2
[rgt] => 3
[depth] => 1
[style_id] => 0
[effective_style_id] => 0
[breadcrumb_data] => {"1":{"node_id":1,"title":"Main Category","depth":0,"lft":1,"node_name":null,"node_type_id":"Category","display_in_list":true}}
[navigation_id] =>
[effective_navigation_id] =>
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[25001] => ThemeHouse\XPress\XF\Entity\Thread Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 73
[rootClass:protected] => XF\Entity\Thread
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[thread_id] => 25001
[node_id] => 2
[title] => TSMC's refusal of ASML's expensive High-NA EUV equipment, explained
[reply_count] => 2
[view_count] => 429
[user_id] => 19450
[username] => user nl
[post_date] => 1777276086
[sticky] => 0
[discussion_state] => visible
[discussion_open] => 1
[discussion_type] => discussion
[first_post_id] => 99473
[first_post_reaction_score] => 1
[first_post_reactions] => {"1":1}
[last_post_date] => 1777300281
[last_post_id] => 99480
[last_post_user_id] => 19450
[last_post_username] => user nl
[prefix_id] => 0
[tags] => []
[custom_fields] => []
[vote_score] => 0
[vote_count] => 0
[featured] => 0
[type_data] => []
[index_state] => default
)
[_relations:protected] => Array
(
[User] => ThemeHouse\XLink\XF\Entity\User Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 70
[rootClass:protected] => XF\Entity\User
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[user_id] => 19450
[username] => user nl
[username_date] => 0
[username_date_visible] => 0
[email] => mauricehmjanssen@gmail.com
[custom_title] =>
[language_id] => 1
[style_id] => 1
[style_variation] =>
[timezone] => Europe/Amsterdam
[visible] => 1
[activity_visible] => 1
[user_group_id] => 2
[secondary_group_ids] =>
[display_style_group_id] => 2
[permission_combination_id] => 8
[message_count] => 562
[question_solution_count] => 0
[conversations_unread] => 0
[register_date] => 1424291496
[last_activity] => 1777314274
[last_summary_email_date] =>
[trophy_points] => 63
[alerts_unviewed] => 0
[alerts_unread] => 0
[avatar_date] => 1726169369
[avatar_width] => 384
[avatar_height] => 384
[avatar_highdpi] => 1
[avatar_optimized] => 0
[gravatar] =>
[user_state] => valid
[security_lock] =>
[is_moderator] => 0
[is_admin] => 0
[is_banned] => 0
[reaction_score] => 408
[warning_points] => 0
[is_staff] => 0
[secret_key] => V-1lb5_AW69yhzqA5ok9b64U0fMjJiqf
[privacy_policy_accepted] => 0
[terms_accepted] => 0
[vote_score] => 0
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[Forum] => XF\Entity\Forum Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 56
[rootClass:protected] => XF\Entity\Forum
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[discussion_count] => 8563
[message_count] => 62673
[last_post_id] => 99485
[last_post_date] => 1777323278
[last_post_user_id] => 35301
[last_post_username] => Xebec
[last_thread_id] => 24989
[last_thread_title] => South Korea’s K-shaped economy where chip giants give out $1 million bonuses to staff
[last_thread_prefix_id] => 0
[moderate_threads] => 0
[moderate_replies] => 0
[allow_posting] => 1
[count_messages] => 1
[auto_feature] => 0
[find_new] => 1
[allow_index] => allow
[index_criteria] =>
[field_cache] => []
[prefix_cache] => []
[prompt_cache] => []
[default_prefix_id] => 0
[default_sort_order] => last_post_date
[default_sort_direction] => desc
[list_date_limit_days] => 0
[require_prefix] => 0
[allowed_watch_notifications] => all
[min_tags] => 0
[forum_type_id] => discussion
[type_config] => {"allowed_thread_types":["poll"]}
)
[_relations:protected] => Array
(
[Node] => XF\Entity\Node Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 55
[rootClass:protected] => XF\Entity\Node
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[title] => SemiWiki Main Forum ( Ask the Experts! )
[description] => Post your questions to the experts here!
[node_name] =>
[node_type_id] => Forum
[parent_node_id] => 1
[display_order] => 1
[display_in_list] => 1
[lft] => 2
[rgt] => 3
[depth] => 1
[style_id] => 0
[effective_style_id] => 0
[breadcrumb_data] => {"1":{"node_id":1,"title":"Main Category","depth":0,"lft":1,"node_name":null,"node_type_id":"Category","display_in_list":true}}
[navigation_id] =>
[effective_navigation_id] =>
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[24959] => ThemeHouse\XPress\XF\Entity\Thread Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 77
[rootClass:protected] => XF\Entity\Thread
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[thread_id] => 24959
[node_id] => 2
[title] => TSMC chief calls Tesla and Intel competitors at earnings call
[reply_count] => 1
[view_count] => 889
[user_id] => 5
[username] => Daniel Nenni
[post_date] => 1776637191
[sticky] => 0
[discussion_state] => visible
[discussion_open] => 1
[discussion_type] => discussion
[first_post_id] => 99290
[first_post_reaction_score] => 1
[first_post_reactions] => {"1":1}
[last_post_date] => 1777297606
[last_post_id] => 99478
[last_post_user_id] => 45199
[last_post_username] => staf
[prefix_id] => 0
[tags] => []
[custom_fields] => []
[vote_score] => 0
[vote_count] => 0
[featured] => 0
[type_data] => []
[index_state] => default
)
[_relations:protected] => Array
(
[User] => ThemeHouse\XLink\XF\Entity\User Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 62
[rootClass:protected] => XF\Entity\User
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[user_id] => 5
[username] => Daniel Nenni
[username_date] => 0
[username_date_visible] => 0
[email] => dnenni@semiwiki.com
[custom_title] => Founder
[language_id] => 1
[style_id] => 0
[style_variation] =>
[timezone] => America/Los_Angeles
[visible] => 1
[activity_visible] => 1
[user_group_id] => 3
[secondary_group_ids] => 4,5,132
[display_style_group_id] => 3
[permission_combination_id] => 88
[message_count] => 15512
[question_solution_count] => 0
[conversations_unread] => 0
[register_date] => 1280720820
[last_activity] => 1777310075
[last_summary_email_date] => 1605968657
[trophy_points] => 113
[alerts_unviewed] => 77
[alerts_unread] => 77
[avatar_date] => 1663211649
[avatar_width] => 110
[avatar_height] => 107
[avatar_highdpi] => 0
[avatar_optimized] => 0
[gravatar] =>
[user_state] => valid
[security_lock] =>
[is_moderator] => 1
[is_admin] => 1
[is_banned] => 0
[reaction_score] => 9399
[warning_points] => 0
[is_staff] => 1
[secret_key] => 0HwyUVVHCwJotUUVEpvqAclfYJdGNPpw
[privacy_policy_accepted] => 0
[terms_accepted] => 0
[vote_score] => 0
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[Forum] => XF\Entity\Forum Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 56
[rootClass:protected] => XF\Entity\Forum
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[discussion_count] => 8563
[message_count] => 62673
[last_post_id] => 99485
[last_post_date] => 1777323278
[last_post_user_id] => 35301
[last_post_username] => Xebec
[last_thread_id] => 24989
[last_thread_title] => South Korea’s K-shaped economy where chip giants give out $1 million bonuses to staff
[last_thread_prefix_id] => 0
[moderate_threads] => 0
[moderate_replies] => 0
[allow_posting] => 1
[count_messages] => 1
[auto_feature] => 0
[find_new] => 1
[allow_index] => allow
[index_criteria] =>
[field_cache] => []
[prefix_cache] => []
[prompt_cache] => []
[default_prefix_id] => 0
[default_sort_order] => last_post_date
[default_sort_direction] => desc
[list_date_limit_days] => 0
[require_prefix] => 0
[allowed_watch_notifications] => all
[min_tags] => 0
[forum_type_id] => discussion
[type_config] => {"allowed_thread_types":["poll"]}
)
[_relations:protected] => Array
(
[Node] => XF\Entity\Node Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 55
[rootClass:protected] => XF\Entity\Node
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[title] => SemiWiki Main Forum ( Ask the Experts! )
[description] => Post your questions to the experts here!
[node_name] =>
[node_type_id] => Forum
[parent_node_id] => 1
[display_order] => 1
[display_in_list] => 1
[lft] => 2
[rgt] => 3
[depth] => 1
[style_id] => 0
[effective_style_id] => 0
[breadcrumb_data] => {"1":{"node_id":1,"title":"Main Category","depth":0,"lft":1,"node_name":null,"node_type_id":"Category","display_in_list":true}}
[navigation_id] =>
[effective_navigation_id] =>
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[24998] => ThemeHouse\XPress\XF\Entity\Thread Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 81
[rootClass:protected] => XF\Entity\Thread
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[thread_id] => 24998
[node_id] => 2
[title] => NEO Semiconductor's 3D X-DRAM for AI processors has passed proof-of-concept validation — company secures funding to develop next-gen HBM alternative
[reply_count] => 5
[view_count] => 819
[user_id] => 5185
[username] => Fred Chen
[post_date] => 1777105258
[sticky] => 0
[discussion_state] => visible
[discussion_open] => 1
[discussion_type] => discussion
[first_post_id] => 99450
[first_post_reaction_score] => 1
[first_post_reactions] => {"1":1}
[last_post_date] => 1777297544
[last_post_id] => 99477
[last_post_user_id] => 5185
[last_post_username] => Fred Chen
[prefix_id] => 0
[tags] => []
[custom_fields] => []
[vote_score] => 0
[vote_count] => 0
[featured] => 0
[type_data] => []
[index_state] => default
)
[_relations:protected] => Array
(
[User] => ThemeHouse\XLink\XF\Entity\User Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 78
[rootClass:protected] => XF\Entity\User
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[user_id] => 5185
[username] => Fred Chen
[username_date] => 0
[username_date_visible] => 0
[email] => chen.t.fred@gmail.com
[custom_title] =>
[language_id] => 1
[style_id] => 0
[style_variation] =>
[timezone] => America/Los_Angeles
[visible] => 1
[activity_visible] => 1
[user_group_id] => 4
[secondary_group_ids] =>
[display_style_group_id] => 4
[permission_combination_id] => 92
[message_count] => 2614
[question_solution_count] => 0
[conversations_unread] => 0
[register_date] => 1333032401
[last_activity] => 1777312665
[last_summary_email_date] => 1605940563
[trophy_points] => 113
[alerts_unviewed] => 1
[alerts_unread] => 3
[avatar_date] => 0
[avatar_width] => 0
[avatar_height] => 0
[avatar_highdpi] => 0
[avatar_optimized] => 0
[gravatar] =>
[user_state] => valid
[security_lock] =>
[is_moderator] => 0
[is_admin] => 0
[is_banned] => 0
[reaction_score] => 1905
[warning_points] => 0
[is_staff] => 0
[secret_key] => 5m-bZq0HRSi9VA-96QONHJeevdQas5S8
[privacy_policy_accepted] => 0
[terms_accepted] => 0
[vote_score] => 0
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[Forum] => XF\Entity\Forum Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 56
[rootClass:protected] => XF\Entity\Forum
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[discussion_count] => 8563
[message_count] => 62673
[last_post_id] => 99485
[last_post_date] => 1777323278
[last_post_user_id] => 35301
[last_post_username] => Xebec
[last_thread_id] => 24989
[last_thread_title] => South Korea’s K-shaped economy where chip giants give out $1 million bonuses to staff
[last_thread_prefix_id] => 0
[moderate_threads] => 0
[moderate_replies] => 0
[allow_posting] => 1
[count_messages] => 1
[auto_feature] => 0
[find_new] => 1
[allow_index] => allow
[index_criteria] =>
[field_cache] => []
[prefix_cache] => []
[prompt_cache] => []
[default_prefix_id] => 0
[default_sort_order] => last_post_date
[default_sort_direction] => desc
[list_date_limit_days] => 0
[require_prefix] => 0
[allowed_watch_notifications] => all
[min_tags] => 0
[forum_type_id] => discussion
[type_config] => {"allowed_thread_types":["poll"]}
)
[_relations:protected] => Array
(
[Node] => XF\Entity\Node Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 55
[rootClass:protected] => XF\Entity\Node
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[title] => SemiWiki Main Forum ( Ask the Experts! )
[description] => Post your questions to the experts here!
[node_name] =>
[node_type_id] => Forum
[parent_node_id] => 1
[display_order] => 1
[display_in_list] => 1
[lft] => 2
[rgt] => 3
[depth] => 1
[style_id] => 0
[effective_style_id] => 0
[breadcrumb_data] => {"1":{"node_id":1,"title":"Main Category","depth":0,"lft":1,"node_name":null,"node_type_id":"Category","display_in_list":true}}
[navigation_id] =>
[effective_navigation_id] =>
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[25000] => ThemeHouse\XPress\XF\Entity\Thread Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 85
[rootClass:protected] => XF\Entity\Thread
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[thread_id] => 25000
[node_id] => 2
[title] => Beyond the Talent Gap: Solving the "Convergence Bottleneck" in AI Hardware By Dr. Moh Kolbehdari
[reply_count] => 0
[view_count] => 177
[user_id] => 444140
[username] => moh.kolb
[post_date] => 1777248374
[sticky] => 0
[discussion_state] => visible
[discussion_open] => 1
[discussion_type] => discussion
[first_post_id] => 99471
[first_post_reaction_score] => 0
[first_post_reactions] => []
[last_post_date] => 1777248374
[last_post_id] => 99471
[last_post_user_id] => 444140
[last_post_username] => moh.kolb
[prefix_id] => 0
[tags] => []
[custom_fields] => []
[vote_score] => 0
[vote_count] => 0
[featured] => 0
[type_data] => []
[index_state] => default
)
[_relations:protected] => Array
(
[User] => ThemeHouse\XLink\XF\Entity\User Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 82
[rootClass:protected] => XF\Entity\User
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[user_id] => 444140
[username] => moh.kolb
[username_date] => 0
[username_date_visible] => 0
[email] => moh@kolbehdari.com
[custom_title] =>
[language_id] => 1
[style_id] => 0
[style_variation] =>
[timezone] => America/Phoenix
[visible] => 1
[activity_visible] => 1
[user_group_id] => 2
[secondary_group_ids] =>
[display_style_group_id] => 2
[permission_combination_id] => 8
[message_count] => 14
[question_solution_count] => 0
[conversations_unread] => 0
[register_date] => 1775069311
[last_activity] => 1777248375
[last_summary_email_date] => 1775069311
[trophy_points] => 3
[alerts_unviewed] => 0
[alerts_unread] => 0
[avatar_date] => 0
[avatar_width] => 0
[avatar_height] => 0
[avatar_highdpi] => 0
[avatar_optimized] => 0
[gravatar] =>
[user_state] => valid
[security_lock] =>
[is_moderator] => 0
[is_admin] => 0
[is_banned] => 0
[reaction_score] => 1
[warning_points] => 0
[is_staff] => 0
[secret_key] => EG539H6nqaiPLLZ4UXYEvAY-Py_6iJOA
[privacy_policy_accepted] => 1775069311
[terms_accepted] => 1775069311
[vote_score] => 0
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[Forum] => XF\Entity\Forum Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 56
[rootClass:protected] => XF\Entity\Forum
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[discussion_count] => 8563
[message_count] => 62673
[last_post_id] => 99485
[last_post_date] => 1777323278
[last_post_user_id] => 35301
[last_post_username] => Xebec
[last_thread_id] => 24989
[last_thread_title] => South Korea’s K-shaped economy where chip giants give out $1 million bonuses to staff
[last_thread_prefix_id] => 0
[moderate_threads] => 0
[moderate_replies] => 0
[allow_posting] => 1
[count_messages] => 1
[auto_feature] => 0
[find_new] => 1
[allow_index] => allow
[index_criteria] =>
[field_cache] => []
[prefix_cache] => []
[prompt_cache] => []
[default_prefix_id] => 0
[default_sort_order] => last_post_date
[default_sort_direction] => desc
[list_date_limit_days] => 0
[require_prefix] => 0
[allowed_watch_notifications] => all
[min_tags] => 0
[forum_type_id] => discussion
[type_config] => {"allowed_thread_types":["poll"]}
)
[_relations:protected] => Array
(
[Node] => XF\Entity\Node Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 55
[rootClass:protected] => XF\Entity\Node
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[title] => SemiWiki Main Forum ( Ask the Experts! )
[description] => Post your questions to the experts here!
[node_name] =>
[node_type_id] => Forum
[parent_node_id] => 1
[display_order] => 1
[display_in_list] => 1
[lft] => 2
[rgt] => 3
[depth] => 1
[style_id] => 0
[effective_style_id] => 0
[breadcrumb_data] => {"1":{"node_id":1,"title":"Main Category","depth":0,"lft":1,"node_name":null,"node_type_id":"Category","display_in_list":true}}
[navigation_id] =>
[effective_navigation_id] =>
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[24980] => ThemeHouse\XPress\XF\Entity\Thread Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 89
[rootClass:protected] => XF\Entity\Thread
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[thread_id] => 24980
[node_id] => 2
[title] => Exclusive: Intel Tells Staff It Will Disclose Scope Of Work With Elon Musk In ‘Coming Weeks’
[reply_count] => 23
[view_count] => 3270
[user_id] => 5185
[username] => Fred Chen
[post_date] => 1776842744
[sticky] => 0
[discussion_state] => visible
[discussion_open] => 1
[discussion_type] => discussion
[first_post_id] => 99361
[first_post_reaction_score] => 2
[first_post_reactions] => {"1":2}
[last_post_date] => 1777222681
[last_post_id] => 99468
[last_post_user_id] => 19450
[last_post_username] => user nl
[prefix_id] => 0
[tags] => []
[custom_fields] => []
[vote_score] => 0
[vote_count] => 0
[featured] => 0
[type_data] => []
[index_state] => default
)
[_relations:protected] => Array
(
[User] => ThemeHouse\XLink\XF\Entity\User Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 78
[rootClass:protected] => XF\Entity\User
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[user_id] => 5185
[username] => Fred Chen
[username_date] => 0
[username_date_visible] => 0
[email] => chen.t.fred@gmail.com
[custom_title] =>
[language_id] => 1
[style_id] => 0
[style_variation] =>
[timezone] => America/Los_Angeles
[visible] => 1
[activity_visible] => 1
[user_group_id] => 4
[secondary_group_ids] =>
[display_style_group_id] => 4
[permission_combination_id] => 92
[message_count] => 2614
[question_solution_count] => 0
[conversations_unread] => 0
[register_date] => 1333032401
[last_activity] => 1777312665
[last_summary_email_date] => 1605940563
[trophy_points] => 113
[alerts_unviewed] => 1
[alerts_unread] => 3
[avatar_date] => 0
[avatar_width] => 0
[avatar_height] => 0
[avatar_highdpi] => 0
[avatar_optimized] => 0
[gravatar] =>
[user_state] => valid
[security_lock] =>
[is_moderator] => 0
[is_admin] => 0
[is_banned] => 0
[reaction_score] => 1905
[warning_points] => 0
[is_staff] => 0
[secret_key] => 5m-bZq0HRSi9VA-96QONHJeevdQas5S8
[privacy_policy_accepted] => 0
[terms_accepted] => 0
[vote_score] => 0
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[Forum] => XF\Entity\Forum Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 56
[rootClass:protected] => XF\Entity\Forum
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[discussion_count] => 8563
[message_count] => 62673
[last_post_id] => 99485
[last_post_date] => 1777323278
[last_post_user_id] => 35301
[last_post_username] => Xebec
[last_thread_id] => 24989
[last_thread_title] => South Korea’s K-shaped economy where chip giants give out $1 million bonuses to staff
[last_thread_prefix_id] => 0
[moderate_threads] => 0
[moderate_replies] => 0
[allow_posting] => 1
[count_messages] => 1
[auto_feature] => 0
[find_new] => 1
[allow_index] => allow
[index_criteria] =>
[field_cache] => []
[prefix_cache] => []
[prompt_cache] => []
[default_prefix_id] => 0
[default_sort_order] => last_post_date
[default_sort_direction] => desc
[list_date_limit_days] => 0
[require_prefix] => 0
[allowed_watch_notifications] => all
[min_tags] => 0
[forum_type_id] => discussion
[type_config] => {"allowed_thread_types":["poll"]}
)
[_relations:protected] => Array
(
[Node] => XF\Entity\Node Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 55
[rootClass:protected] => XF\Entity\Node
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[title] => SemiWiki Main Forum ( Ask the Experts! )
[description] => Post your questions to the experts here!
[node_name] =>
[node_type_id] => Forum
[parent_node_id] => 1
[display_order] => 1
[display_in_list] => 1
[lft] => 2
[rgt] => 3
[depth] => 1
[style_id] => 0
[effective_style_id] => 0
[breadcrumb_data] => {"1":{"node_id":1,"title":"Main Category","depth":0,"lft":1,"node_name":null,"node_type_id":"Category","display_in_list":true}}
[navigation_id] =>
[effective_navigation_id] =>
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[24939] => ThemeHouse\XPress\XF\Entity\Thread Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 93
[rootClass:protected] => XF\Entity\Thread
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[thread_id] => 24939
[node_id] => 2
[title] => ASML lifts 2026 forecast as surging AI chip demand boosts new orders
[reply_count] => 12
[view_count] => 3574
[user_id] => 5
[username] => Daniel Nenni
[post_date] => 1776267270
[sticky] => 0
[discussion_state] => visible
[discussion_open] => 1
[discussion_type] => discussion
[first_post_id] => 99193
[first_post_reaction_score] => 1
[first_post_reactions] => {"1":1}
[last_post_date] => 1777185991
[last_post_id] => 99463
[last_post_user_id] => 19450
[last_post_username] => user nl
[prefix_id] => 0
[tags] => []
[custom_fields] => []
[vote_score] => 0
[vote_count] => 0
[featured] => 0
[type_data] => []
[index_state] => default
)
[_relations:protected] => Array
(
[User] => ThemeHouse\XLink\XF\Entity\User Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 62
[rootClass:protected] => XF\Entity\User
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[user_id] => 5
[username] => Daniel Nenni
[username_date] => 0
[username_date_visible] => 0
[email] => dnenni@semiwiki.com
[custom_title] => Founder
[language_id] => 1
[style_id] => 0
[style_variation] =>
[timezone] => America/Los_Angeles
[visible] => 1
[activity_visible] => 1
[user_group_id] => 3
[secondary_group_ids] => 4,5,132
[display_style_group_id] => 3
[permission_combination_id] => 88
[message_count] => 15512
[question_solution_count] => 0
[conversations_unread] => 0
[register_date] => 1280720820
[last_activity] => 1777310075
[last_summary_email_date] => 1605968657
[trophy_points] => 113
[alerts_unviewed] => 77
[alerts_unread] => 77
[avatar_date] => 1663211649
[avatar_width] => 110
[avatar_height] => 107
[avatar_highdpi] => 0
[avatar_optimized] => 0
[gravatar] =>
[user_state] => valid
[security_lock] =>
[is_moderator] => 1
[is_admin] => 1
[is_banned] => 0
[reaction_score] => 9399
[warning_points] => 0
[is_staff] => 1
[secret_key] => 0HwyUVVHCwJotUUVEpvqAclfYJdGNPpw
[privacy_policy_accepted] => 0
[terms_accepted] => 0
[vote_score] => 0
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[Forum] => XF\Entity\Forum Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 56
[rootClass:protected] => XF\Entity\Forum
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[discussion_count] => 8563
[message_count] => 62673
[last_post_id] => 99485
[last_post_date] => 1777323278
[last_post_user_id] => 35301
[last_post_username] => Xebec
[last_thread_id] => 24989
[last_thread_title] => South Korea’s K-shaped economy where chip giants give out $1 million bonuses to staff
[last_thread_prefix_id] => 0
[moderate_threads] => 0
[moderate_replies] => 0
[allow_posting] => 1
[count_messages] => 1
[auto_feature] => 0
[find_new] => 1
[allow_index] => allow
[index_criteria] =>
[field_cache] => []
[prefix_cache] => []
[prompt_cache] => []
[default_prefix_id] => 0
[default_sort_order] => last_post_date
[default_sort_direction] => desc
[list_date_limit_days] => 0
[require_prefix] => 0
[allowed_watch_notifications] => all
[min_tags] => 0
[forum_type_id] => discussion
[type_config] => {"allowed_thread_types":["poll"]}
)
[_relations:protected] => Array
(
[Node] => XF\Entity\Node Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 55
[rootClass:protected] => XF\Entity\Node
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[title] => SemiWiki Main Forum ( Ask the Experts! )
[description] => Post your questions to the experts here!
[node_name] =>
[node_type_id] => Forum
[parent_node_id] => 1
[display_order] => 1
[display_in_list] => 1
[lft] => 2
[rgt] => 3
[depth] => 1
[style_id] => 0
[effective_style_id] => 0
[breadcrumb_data] => {"1":{"node_id":1,"title":"Main Category","depth":0,"lft":1,"node_name":null,"node_type_id":"Category","display_in_list":true}}
[navigation_id] =>
[effective_navigation_id] =>
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[24995] => ThemeHouse\XPress\XF\Entity\Thread Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 97
[rootClass:protected] => XF\Entity\Thread
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[thread_id] => 24995
[node_id] => 2
[title] => US Chipmakers Hit Record Highs as Intel Turbocharges AI Rally
[reply_count] => 9
[view_count] => 1874
[user_id] => 5
[username] => Daniel Nenni
[post_date] => 1777052203
[sticky] => 0
[discussion_state] => visible
[discussion_open] => 1
[discussion_type] => discussion
[first_post_id] => 99429
[first_post_reaction_score] => 0
[first_post_reactions] => []
[last_post_date] => 1777177888
[last_post_id] => 99461
[last_post_user_id] => 334215
[last_post_username] => kevin01
[prefix_id] => 0
[tags] => []
[custom_fields] => []
[vote_score] => 0
[vote_count] => 0
[featured] => 0
[type_data] => []
[index_state] => default
)
[_relations:protected] => Array
(
[User] => ThemeHouse\XLink\XF\Entity\User Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 62
[rootClass:protected] => XF\Entity\User
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[user_id] => 5
[username] => Daniel Nenni
[username_date] => 0
[username_date_visible] => 0
[email] => dnenni@semiwiki.com
[custom_title] => Founder
[language_id] => 1
[style_id] => 0
[style_variation] =>
[timezone] => America/Los_Angeles
[visible] => 1
[activity_visible] => 1
[user_group_id] => 3
[secondary_group_ids] => 4,5,132
[display_style_group_id] => 3
[permission_combination_id] => 88
[message_count] => 15512
[question_solution_count] => 0
[conversations_unread] => 0
[register_date] => 1280720820
[last_activity] => 1777310075
[last_summary_email_date] => 1605968657
[trophy_points] => 113
[alerts_unviewed] => 77
[alerts_unread] => 77
[avatar_date] => 1663211649
[avatar_width] => 110
[avatar_height] => 107
[avatar_highdpi] => 0
[avatar_optimized] => 0
[gravatar] =>
[user_state] => valid
[security_lock] =>
[is_moderator] => 1
[is_admin] => 1
[is_banned] => 0
[reaction_score] => 9399
[warning_points] => 0
[is_staff] => 1
[secret_key] => 0HwyUVVHCwJotUUVEpvqAclfYJdGNPpw
[privacy_policy_accepted] => 0
[terms_accepted] => 0
[vote_score] => 0
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[Forum] => XF\Entity\Forum Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 56
[rootClass:protected] => XF\Entity\Forum
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[discussion_count] => 8563
[message_count] => 62673
[last_post_id] => 99485
[last_post_date] => 1777323278
[last_post_user_id] => 35301
[last_post_username] => Xebec
[last_thread_id] => 24989
[last_thread_title] => South Korea’s K-shaped economy where chip giants give out $1 million bonuses to staff
[last_thread_prefix_id] => 0
[moderate_threads] => 0
[moderate_replies] => 0
[allow_posting] => 1
[count_messages] => 1
[auto_feature] => 0
[find_new] => 1
[allow_index] => allow
[index_criteria] =>
[field_cache] => []
[prefix_cache] => []
[prompt_cache] => []
[default_prefix_id] => 0
[default_sort_order] => last_post_date
[default_sort_direction] => desc
[list_date_limit_days] => 0
[require_prefix] => 0
[allowed_watch_notifications] => all
[min_tags] => 0
[forum_type_id] => discussion
[type_config] => {"allowed_thread_types":["poll"]}
)
[_relations:protected] => Array
(
[Node] => XF\Entity\Node Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 55
[rootClass:protected] => XF\Entity\Node
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[title] => SemiWiki Main Forum ( Ask the Experts! )
[description] => Post your questions to the experts here!
[node_name] =>
[node_type_id] => Forum
[parent_node_id] => 1
[display_order] => 1
[display_in_list] => 1
[lft] => 2
[rgt] => 3
[depth] => 1
[style_id] => 0
[effective_style_id] => 0
[breadcrumb_data] => {"1":{"node_id":1,"title":"Main Category","depth":0,"lft":1,"node_name":null,"node_type_id":"Category","display_in_list":true}}
[navigation_id] =>
[effective_navigation_id] =>
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[24999] => ThemeHouse\XPress\XF\Entity\Thread Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 101
[rootClass:protected] => XF\Entity\Thread
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[thread_id] => 24999
[node_id] => 2
[title] => DeepSeek unveils new AI model tailored for Huawei chips as China pushes for tech autonomy
[reply_count] => 0
[view_count] => 875
[user_id] => 5
[username] => Daniel Nenni
[post_date] => 1777134842
[sticky] => 0
[discussion_state] => visible
[discussion_open] => 1
[discussion_type] => discussion
[first_post_id] => 99456
[first_post_reaction_score] => 0
[first_post_reactions] => []
[last_post_date] => 1777134842
[last_post_id] => 99456
[last_post_user_id] => 5
[last_post_username] => Daniel Nenni
[prefix_id] => 0
[tags] => []
[custom_fields] => []
[vote_score] => 0
[vote_count] => 0
[featured] => 0
[type_data] => []
[index_state] => default
)
[_relations:protected] => Array
(
[User] => ThemeHouse\XLink\XF\Entity\User Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 62
[rootClass:protected] => XF\Entity\User
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[user_id] => 5
[username] => Daniel Nenni
[username_date] => 0
[username_date_visible] => 0
[email] => dnenni@semiwiki.com
[custom_title] => Founder
[language_id] => 1
[style_id] => 0
[style_variation] =>
[timezone] => America/Los_Angeles
[visible] => 1
[activity_visible] => 1
[user_group_id] => 3
[secondary_group_ids] => 4,5,132
[display_style_group_id] => 3
[permission_combination_id] => 88
[message_count] => 15512
[question_solution_count] => 0
[conversations_unread] => 0
[register_date] => 1280720820
[last_activity] => 1777310075
[last_summary_email_date] => 1605968657
[trophy_points] => 113
[alerts_unviewed] => 77
[alerts_unread] => 77
[avatar_date] => 1663211649
[avatar_width] => 110
[avatar_height] => 107
[avatar_highdpi] => 0
[avatar_optimized] => 0
[gravatar] =>
[user_state] => valid
[security_lock] =>
[is_moderator] => 1
[is_admin] => 1
[is_banned] => 0
[reaction_score] => 9399
[warning_points] => 0
[is_staff] => 1
[secret_key] => 0HwyUVVHCwJotUUVEpvqAclfYJdGNPpw
[privacy_policy_accepted] => 0
[terms_accepted] => 0
[vote_score] => 0
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[Forum] => XF\Entity\Forum Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 56
[rootClass:protected] => XF\Entity\Forum
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[discussion_count] => 8563
[message_count] => 62673
[last_post_id] => 99485
[last_post_date] => 1777323278
[last_post_user_id] => 35301
[last_post_username] => Xebec
[last_thread_id] => 24989
[last_thread_title] => South Korea’s K-shaped economy where chip giants give out $1 million bonuses to staff
[last_thread_prefix_id] => 0
[moderate_threads] => 0
[moderate_replies] => 0
[allow_posting] => 1
[count_messages] => 1
[auto_feature] => 0
[find_new] => 1
[allow_index] => allow
[index_criteria] =>
[field_cache] => []
[prefix_cache] => []
[prompt_cache] => []
[default_prefix_id] => 0
[default_sort_order] => last_post_date
[default_sort_direction] => desc
[list_date_limit_days] => 0
[require_prefix] => 0
[allowed_watch_notifications] => all
[min_tags] => 0
[forum_type_id] => discussion
[type_config] => {"allowed_thread_types":["poll"]}
)
[_relations:protected] => Array
(
[Node] => XF\Entity\Node Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 55
[rootClass:protected] => XF\Entity\Node
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[title] => SemiWiki Main Forum ( Ask the Experts! )
[description] => Post your questions to the experts here!
[node_name] =>
[node_type_id] => Forum
[parent_node_id] => 1
[display_order] => 1
[display_in_list] => 1
[lft] => 2
[rgt] => 3
[depth] => 1
[style_id] => 0
[effective_style_id] => 0
[breadcrumb_data] => {"1":{"node_id":1,"title":"Main Category","depth":0,"lft":1,"node_name":null,"node_type_id":"Category","display_in_list":true}}
[navigation_id] =>
[effective_navigation_id] =>
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[24981] => ThemeHouse\XPress\XF\Entity\Thread Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 105
[rootClass:protected] => XF\Entity\Thread
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[thread_id] => 24981
[node_id] => 2
[title] => TSMC 2026 Technology Symposium Santa Clara 22 April 2026
[reply_count] => 9
[view_count] => 2749
[user_id] => 19450
[username] => user nl
[post_date] => 1776886309
[sticky] => 0
[discussion_state] => visible
[discussion_open] => 1
[discussion_type] => discussion
[first_post_id] => 99369
[first_post_reaction_score] => 1
[first_post_reactions] => {"1":1}
[last_post_date] => 1777132136
[last_post_id] => 99455
[last_post_user_id] => 395487
[last_post_username] => LLL0955
[prefix_id] => 0
[tags] => []
[custom_fields] => []
[vote_score] => 0
[vote_count] => 0
[featured] => 0
[type_data] => []
[index_state] => default
)
[_relations:protected] => Array
(
[User] => ThemeHouse\XLink\XF\Entity\User Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 70
[rootClass:protected] => XF\Entity\User
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[user_id] => 19450
[username] => user nl
[username_date] => 0
[username_date_visible] => 0
[email] => mauricehmjanssen@gmail.com
[custom_title] =>
[language_id] => 1
[style_id] => 1
[style_variation] =>
[timezone] => Europe/Amsterdam
[visible] => 1
[activity_visible] => 1
[user_group_id] => 2
[secondary_group_ids] =>
[display_style_group_id] => 2
[permission_combination_id] => 8
[message_count] => 562
[question_solution_count] => 0
[conversations_unread] => 0
[register_date] => 1424291496
[last_activity] => 1777314274
[last_summary_email_date] =>
[trophy_points] => 63
[alerts_unviewed] => 0
[alerts_unread] => 0
[avatar_date] => 1726169369
[avatar_width] => 384
[avatar_height] => 384
[avatar_highdpi] => 1
[avatar_optimized] => 0
[gravatar] =>
[user_state] => valid
[security_lock] =>
[is_moderator] => 0
[is_admin] => 0
[is_banned] => 0
[reaction_score] => 408
[warning_points] => 0
[is_staff] => 0
[secret_key] => V-1lb5_AW69yhzqA5ok9b64U0fMjJiqf
[privacy_policy_accepted] => 0
[terms_accepted] => 0
[vote_score] => 0
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[Forum] => XF\Entity\Forum Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 56
[rootClass:protected] => XF\Entity\Forum
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[discussion_count] => 8563
[message_count] => 62673
[last_post_id] => 99485
[last_post_date] => 1777323278
[last_post_user_id] => 35301
[last_post_username] => Xebec
[last_thread_id] => 24989
[last_thread_title] => South Korea’s K-shaped economy where chip giants give out $1 million bonuses to staff
[last_thread_prefix_id] => 0
[moderate_threads] => 0
[moderate_replies] => 0
[allow_posting] => 1
[count_messages] => 1
[auto_feature] => 0
[find_new] => 1
[allow_index] => allow
[index_criteria] =>
[field_cache] => []
[prefix_cache] => []
[prompt_cache] => []
[default_prefix_id] => 0
[default_sort_order] => last_post_date
[default_sort_direction] => desc
[list_date_limit_days] => 0
[require_prefix] => 0
[allowed_watch_notifications] => all
[min_tags] => 0
[forum_type_id] => discussion
[type_config] => {"allowed_thread_types":["poll"]}
)
[_relations:protected] => Array
(
[Node] => XF\Entity\Node Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 55
[rootClass:protected] => XF\Entity\Node
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[title] => SemiWiki Main Forum ( Ask the Experts! )
[description] => Post your questions to the experts here!
[node_name] =>
[node_type_id] => Forum
[parent_node_id] => 1
[display_order] => 1
[display_in_list] => 1
[lft] => 2
[rgt] => 3
[depth] => 1
[style_id] => 0
[effective_style_id] => 0
[breadcrumb_data] => {"1":{"node_id":1,"title":"Main Category","depth":0,"lft":1,"node_name":null,"node_type_id":"Category","display_in_list":true}}
[navigation_id] =>
[effective_navigation_id] =>
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[24982] => ThemeHouse\XPress\XF\Entity\Thread Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 109
[rootClass:protected] => XF\Entity\Thread
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[thread_id] => 24982
[node_id] => 2
[title] => Tesla Earnings Call - Intel 14A, Research (Tera)Fab details, Supplier Leverage?
[reply_count] => 24
[view_count] => 3366
[user_id] => 35301
[username] => Xebec
[post_date] => 1776897772
[sticky] => 0
[discussion_state] => visible
[discussion_open] => 1
[discussion_type] => discussion
[first_post_id] => 99374
[first_post_reaction_score] => 6
[first_post_reactions] => {"1":6}
[last_post_date] => 1777118342
[last_post_id] => 99453
[last_post_user_id] => 90182
[last_post_username] => siliconbruh999
[prefix_id] => 0
[tags] => []
[custom_fields] => []
[vote_score] => 0
[vote_count] => 0
[featured] => 0
[type_data] => []
[index_state] => default
)
[_relations:protected] => Array
(
[User] => ThemeHouse\XLink\XF\Entity\User Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 106
[rootClass:protected] => XF\Entity\User
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[user_id] => 35301
[username] => Xebec
[username_date] => 0
[username_date_visible] => 0
[email] => john.heritage@gmail.com
[custom_title] =>
[language_id] => 1
[style_id] => 0
[style_variation] =>
[timezone] => America/New_York
[visible] => 1
[activity_visible] => 1
[user_group_id] => 2
[secondary_group_ids] =>
[display_style_group_id] => 2
[permission_combination_id] => 8
[message_count] => 1695
[question_solution_count] => 0
[conversations_unread] => 0
[register_date] => 1598710106
[last_activity] => 1777323278
[last_summary_email_date] => 1631629203
[trophy_points] => 113
[alerts_unviewed] => 1
[alerts_unread] => 2
[avatar_date] => 1760746858
[avatar_width] => 480
[avatar_height] => 384
[avatar_highdpi] => 1
[avatar_optimized] => 0
[gravatar] =>
[user_state] => valid
[security_lock] =>
[is_moderator] => 0
[is_admin] => 0
[is_banned] => 0
[reaction_score] => 2073
[warning_points] => 0
[is_staff] => 0
[secret_key] => Y7XyJgQMBi7ZiDtuAyqNGDrBQQsi8JB4
[privacy_policy_accepted] => 1598710106
[terms_accepted] => 1598710106
[vote_score] => 0
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[Forum] => XF\Entity\Forum Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 56
[rootClass:protected] => XF\Entity\Forum
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[discussion_count] => 8563
[message_count] => 62673
[last_post_id] => 99485
[last_post_date] => 1777323278
[last_post_user_id] => 35301
[last_post_username] => Xebec
[last_thread_id] => 24989
[last_thread_title] => South Korea’s K-shaped economy where chip giants give out $1 million bonuses to staff
[last_thread_prefix_id] => 0
[moderate_threads] => 0
[moderate_replies] => 0
[allow_posting] => 1
[count_messages] => 1
[auto_feature] => 0
[find_new] => 1
[allow_index] => allow
[index_criteria] =>
[field_cache] => []
[prefix_cache] => []
[prompt_cache] => []
[default_prefix_id] => 0
[default_sort_order] => last_post_date
[default_sort_direction] => desc
[list_date_limit_days] => 0
[require_prefix] => 0
[allowed_watch_notifications] => all
[min_tags] => 0
[forum_type_id] => discussion
[type_config] => {"allowed_thread_types":["poll"]}
)
[_relations:protected] => Array
(
[Node] => XF\Entity\Node Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 55
[rootClass:protected] => XF\Entity\Node
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[title] => SemiWiki Main Forum ( Ask the Experts! )
[description] => Post your questions to the experts here!
[node_name] =>
[node_type_id] => Forum
[parent_node_id] => 1
[display_order] => 1
[display_in_list] => 1
[lft] => 2
[rgt] => 3
[depth] => 1
[style_id] => 0
[effective_style_id] => 0
[breadcrumb_data] => {"1":{"node_id":1,"title":"Main Category","depth":0,"lft":1,"node_name":null,"node_type_id":"Category","display_in_list":true}}
[navigation_id] =>
[effective_navigation_id] =>
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[24926] => ThemeHouse\XPress\XF\Entity\Thread Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 113
[rootClass:protected] => XF\Entity\Thread
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[thread_id] => 24926
[node_id] => 2
[title] => Could Intel’s Foundry Be Worth $500 Billion?
[reply_count] => 55
[view_count] => 6972
[user_id] => 5
[username] => Daniel Nenni
[post_date] => 1776116591
[sticky] => 0
[discussion_state] => visible
[discussion_open] => 1
[discussion_type] => discussion
[first_post_id] => 99141
[first_post_reaction_score] => 0
[first_post_reactions] => []
[last_post_date] => 1777064828
[last_post_id] => 99440
[last_post_user_id] => 332041
[last_post_username] => XYang2023
[prefix_id] => 0
[tags] => []
[custom_fields] => []
[vote_score] => 0
[vote_count] => 0
[featured] => 0
[type_data] => []
[index_state] => default
)
[_relations:protected] => Array
(
[User] => ThemeHouse\XLink\XF\Entity\User Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 62
[rootClass:protected] => XF\Entity\User
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[user_id] => 5
[username] => Daniel Nenni
[username_date] => 0
[username_date_visible] => 0
[email] => dnenni@semiwiki.com
[custom_title] => Founder
[language_id] => 1
[style_id] => 0
[style_variation] =>
[timezone] => America/Los_Angeles
[visible] => 1
[activity_visible] => 1
[user_group_id] => 3
[secondary_group_ids] => 4,5,132
[display_style_group_id] => 3
[permission_combination_id] => 88
[message_count] => 15512
[question_solution_count] => 0
[conversations_unread] => 0
[register_date] => 1280720820
[last_activity] => 1777310075
[last_summary_email_date] => 1605968657
[trophy_points] => 113
[alerts_unviewed] => 77
[alerts_unread] => 77
[avatar_date] => 1663211649
[avatar_width] => 110
[avatar_height] => 107
[avatar_highdpi] => 0
[avatar_optimized] => 0
[gravatar] =>
[user_state] => valid
[security_lock] =>
[is_moderator] => 1
[is_admin] => 1
[is_banned] => 0
[reaction_score] => 9399
[warning_points] => 0
[is_staff] => 1
[secret_key] => 0HwyUVVHCwJotUUVEpvqAclfYJdGNPpw
[privacy_policy_accepted] => 0
[terms_accepted] => 0
[vote_score] => 0
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[Forum] => XF\Entity\Forum Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 56
[rootClass:protected] => XF\Entity\Forum
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[discussion_count] => 8563
[message_count] => 62673
[last_post_id] => 99485
[last_post_date] => 1777323278
[last_post_user_id] => 35301
[last_post_username] => Xebec
[last_thread_id] => 24989
[last_thread_title] => South Korea’s K-shaped economy where chip giants give out $1 million bonuses to staff
[last_thread_prefix_id] => 0
[moderate_threads] => 0
[moderate_replies] => 0
[allow_posting] => 1
[count_messages] => 1
[auto_feature] => 0
[find_new] => 1
[allow_index] => allow
[index_criteria] =>
[field_cache] => []
[prefix_cache] => []
[prompt_cache] => []
[default_prefix_id] => 0
[default_sort_order] => last_post_date
[default_sort_direction] => desc
[list_date_limit_days] => 0
[require_prefix] => 0
[allowed_watch_notifications] => all
[min_tags] => 0
[forum_type_id] => discussion
[type_config] => {"allowed_thread_types":["poll"]}
)
[_relations:protected] => Array
(
[Node] => XF\Entity\Node Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 55
[rootClass:protected] => XF\Entity\Node
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[title] => SemiWiki Main Forum ( Ask the Experts! )
[description] => Post your questions to the experts here!
[node_name] =>
[node_type_id] => Forum
[parent_node_id] => 1
[display_order] => 1
[display_in_list] => 1
[lft] => 2
[rgt] => 3
[depth] => 1
[style_id] => 0
[effective_style_id] => 0
[breadcrumb_data] => {"1":{"node_id":1,"title":"Main Category","depth":0,"lft":1,"node_name":null,"node_type_id":"Category","display_in_list":true}}
[navigation_id] =>
[effective_navigation_id] =>
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[24994] => ThemeHouse\XPress\XF\Entity\Thread Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 117
[rootClass:protected] => XF\Entity\Thread
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[thread_id] => 24994
[node_id] => 2
[title] => Meta signs agreement with AWS to power agentic AI on Amazon's Graviton chips
[reply_count] => 0
[view_count] => 572
[user_id] => 36640
[username] => soAsian
[post_date] => 1777049199
[sticky] => 0
[discussion_state] => visible
[discussion_open] => 1
[discussion_type] => discussion
[first_post_id] => 99428
[first_post_reaction_score] => 0
[first_post_reactions] => []
[last_post_date] => 1777049199
[last_post_id] => 99428
[last_post_user_id] => 36640
[last_post_username] => soAsian
[prefix_id] => 0
[tags] => []
[custom_fields] => []
[vote_score] => 0
[vote_count] => 0
[featured] => 0
[type_data] => []
[index_state] => default
)
[_relations:protected] => Array
(
[User] => ThemeHouse\XLink\XF\Entity\User Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 114
[rootClass:protected] => XF\Entity\User
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[user_id] => 36640
[username] => soAsian
[username_date] => 0
[username_date_visible] => 0
[email] => jackmtsai@gmail.com
[custom_title] =>
[language_id] => 1
[style_id] => 0
[style_variation] =>
[timezone] => America/Chicago
[visible] => 1
[activity_visible] => 1
[user_group_id] => 2
[secondary_group_ids] =>
[display_style_group_id] => 2
[permission_combination_id] => 8
[message_count] => 425
[question_solution_count] => 0
[conversations_unread] => 0
[register_date] => 1608139716
[last_activity] => 1777272295
[last_summary_email_date] => 1719670845
[trophy_points] => 63
[alerts_unviewed] => 0
[alerts_unread] => 0
[avatar_date] => 0
[avatar_width] => 0
[avatar_height] => 0
[avatar_highdpi] => 0
[avatar_optimized] => 0
[gravatar] =>
[user_state] => valid
[security_lock] =>
[is_moderator] => 0
[is_admin] => 0
[is_banned] => 0
[reaction_score] => 389
[warning_points] => 0
[is_staff] => 0
[secret_key] => 2oKeCTFkGUpMro5tcmj7WaY9HksB13Kw
[privacy_policy_accepted] => 1608139716
[terms_accepted] => 1608139716
[vote_score] => 0
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[Forum] => XF\Entity\Forum Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 56
[rootClass:protected] => XF\Entity\Forum
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[discussion_count] => 8563
[message_count] => 62673
[last_post_id] => 99485
[last_post_date] => 1777323278
[last_post_user_id] => 35301
[last_post_username] => Xebec
[last_thread_id] => 24989
[last_thread_title] => South Korea’s K-shaped economy where chip giants give out $1 million bonuses to staff
[last_thread_prefix_id] => 0
[moderate_threads] => 0
[moderate_replies] => 0
[allow_posting] => 1
[count_messages] => 1
[auto_feature] => 0
[find_new] => 1
[allow_index] => allow
[index_criteria] =>
[field_cache] => []
[prefix_cache] => []
[prompt_cache] => []
[default_prefix_id] => 0
[default_sort_order] => last_post_date
[default_sort_direction] => desc
[list_date_limit_days] => 0
[require_prefix] => 0
[allowed_watch_notifications] => all
[min_tags] => 0
[forum_type_id] => discussion
[type_config] => {"allowed_thread_types":["poll"]}
)
[_relations:protected] => Array
(
[Node] => XF\Entity\Node Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 55
[rootClass:protected] => XF\Entity\Node
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[title] => SemiWiki Main Forum ( Ask the Experts! )
[description] => Post your questions to the experts here!
[node_name] =>
[node_type_id] => Forum
[parent_node_id] => 1
[display_order] => 1
[display_in_list] => 1
[lft] => 2
[rgt] => 3
[depth] => 1
[style_id] => 0
[effective_style_id] => 0
[breadcrumb_data] => {"1":{"node_id":1,"title":"Main Category","depth":0,"lft":1,"node_name":null,"node_type_id":"Category","display_in_list":true}}
[navigation_id] =>
[effective_navigation_id] =>
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[24979] => ThemeHouse\XPress\XF\Entity\Thread Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 121
[rootClass:protected] => XF\Entity\Thread
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[thread_id] => 24979
[node_id] => 2
[title] => SpaceX Strikes Deal With Cursor for $60 Billion
[reply_count] => 5
[view_count] => 1288
[user_id] => 36640
[username] => soAsian
[post_date] => 1776822665
[sticky] => 0
[discussion_state] => visible
[discussion_open] => 1
[discussion_type] => discussion
[first_post_id] => 99357
[first_post_reaction_score] => 4
[first_post_reactions] => {"1":4}
[last_post_date] => 1777003843
[last_post_id] => 99416
[last_post_user_id] => 20231
[last_post_username] => Barnsley
[prefix_id] => 0
[tags] => []
[custom_fields] => []
[vote_score] => 0
[vote_count] => 0
[featured] => 0
[type_data] => []
[index_state] => default
)
[_relations:protected] => Array
(
[User] => ThemeHouse\XLink\XF\Entity\User Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 114
[rootClass:protected] => XF\Entity\User
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[user_id] => 36640
[username] => soAsian
[username_date] => 0
[username_date_visible] => 0
[email] => jackmtsai@gmail.com
[custom_title] =>
[language_id] => 1
[style_id] => 0
[style_variation] =>
[timezone] => America/Chicago
[visible] => 1
[activity_visible] => 1
[user_group_id] => 2
[secondary_group_ids] =>
[display_style_group_id] => 2
[permission_combination_id] => 8
[message_count] => 425
[question_solution_count] => 0
[conversations_unread] => 0
[register_date] => 1608139716
[last_activity] => 1777272295
[last_summary_email_date] => 1719670845
[trophy_points] => 63
[alerts_unviewed] => 0
[alerts_unread] => 0
[avatar_date] => 0
[avatar_width] => 0
[avatar_height] => 0
[avatar_highdpi] => 0
[avatar_optimized] => 0
[gravatar] =>
[user_state] => valid
[security_lock] =>
[is_moderator] => 0
[is_admin] => 0
[is_banned] => 0
[reaction_score] => 389
[warning_points] => 0
[is_staff] => 0
[secret_key] => 2oKeCTFkGUpMro5tcmj7WaY9HksB13Kw
[privacy_policy_accepted] => 1608139716
[terms_accepted] => 1608139716
[vote_score] => 0
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[Forum] => XF\Entity\Forum Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 56
[rootClass:protected] => XF\Entity\Forum
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[discussion_count] => 8563
[message_count] => 62673
[last_post_id] => 99485
[last_post_date] => 1777323278
[last_post_user_id] => 35301
[last_post_username] => Xebec
[last_thread_id] => 24989
[last_thread_title] => South Korea’s K-shaped economy where chip giants give out $1 million bonuses to staff
[last_thread_prefix_id] => 0
[moderate_threads] => 0
[moderate_replies] => 0
[allow_posting] => 1
[count_messages] => 1
[auto_feature] => 0
[find_new] => 1
[allow_index] => allow
[index_criteria] =>
[field_cache] => []
[prefix_cache] => []
[prompt_cache] => []
[default_prefix_id] => 0
[default_sort_order] => last_post_date
[default_sort_direction] => desc
[list_date_limit_days] => 0
[require_prefix] => 0
[allowed_watch_notifications] => all
[min_tags] => 0
[forum_type_id] => discussion
[type_config] => {"allowed_thread_types":["poll"]}
)
[_relations:protected] => Array
(
[Node] => XF\Entity\Node Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 55
[rootClass:protected] => XF\Entity\Node
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[title] => SemiWiki Main Forum ( Ask the Experts! )
[description] => Post your questions to the experts here!
[node_name] =>
[node_type_id] => Forum
[parent_node_id] => 1
[display_order] => 1
[display_in_list] => 1
[lft] => 2
[rgt] => 3
[depth] => 1
[style_id] => 0
[effective_style_id] => 0
[breadcrumb_data] => {"1":{"node_id":1,"title":"Main Category","depth":0,"lft":1,"node_name":null,"node_type_id":"Category","display_in_list":true}}
[navigation_id] =>
[effective_navigation_id] =>
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[24990] => ThemeHouse\XPress\XF\Entity\Thread Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 125
[rootClass:protected] => XF\Entity\Thread
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[thread_id] => 24990
[node_id] => 2
[title] => How Nvidia’s Long-Term Bet Helped Turn WinWay into a Leading Test Interface Supplier
[reply_count] => 0
[view_count] => 499
[user_id] => 398583
[username] => karin623
[post_date] => 1777001751
[sticky] => 0
[discussion_state] => visible
[discussion_open] => 1
[discussion_type] => discussion
[first_post_id] => 99414
[first_post_reaction_score] => 0
[first_post_reactions] => []
[last_post_date] => 1777001751
[last_post_id] => 99414
[last_post_user_id] => 398583
[last_post_username] => karin623
[prefix_id] => 0
[tags] => []
[custom_fields] => []
[vote_score] => 0
[vote_count] => 0
[featured] => 0
[type_data] => []
[index_state] => default
)
[_relations:protected] => Array
(
[User] => ThemeHouse\XLink\XF\Entity\User Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 122
[rootClass:protected] => XF\Entity\User
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[user_id] => 398583
[username] => karin623
[username_date] => 0
[username_date_visible] => 0
[email] => karin623@gmail.com
[custom_title] =>
[language_id] => 1
[style_id] => 0
[style_variation] =>
[timezone] => Asia/Hong_Kong
[visible] => 1
[activity_visible] => 1
[user_group_id] => 2
[secondary_group_ids] =>
[display_style_group_id] => 2
[permission_combination_id] => 8
[message_count] => 44
[question_solution_count] => 0
[conversations_unread] => 0
[register_date] => 1748753435
[last_activity] => 1777001752
[last_summary_email_date] => 1771856462
[trophy_points] => 18
[alerts_unviewed] => 4
[alerts_unread] => 4
[avatar_date] => 0
[avatar_width] => 0
[avatar_height] => 0
[avatar_highdpi] => 0
[avatar_optimized] => 0
[gravatar] =>
[user_state] => valid
[security_lock] =>
[is_moderator] => 0
[is_admin] => 0
[is_banned] => 0
[reaction_score] => 64
[warning_points] => 0
[is_staff] => 0
[secret_key] => PBnrLVmUtkEL7YUKL8Ij_6L3tfKYRzDQ
[privacy_policy_accepted] => 1748753435
[terms_accepted] => 1748753435
[vote_score] => 0
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[Forum] => XF\Entity\Forum Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 56
[rootClass:protected] => XF\Entity\Forum
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[discussion_count] => 8563
[message_count] => 62673
[last_post_id] => 99485
[last_post_date] => 1777323278
[last_post_user_id] => 35301
[last_post_username] => Xebec
[last_thread_id] => 24989
[last_thread_title] => South Korea’s K-shaped economy where chip giants give out $1 million bonuses to staff
[last_thread_prefix_id] => 0
[moderate_threads] => 0
[moderate_replies] => 0
[allow_posting] => 1
[count_messages] => 1
[auto_feature] => 0
[find_new] => 1
[allow_index] => allow
[index_criteria] =>
[field_cache] => []
[prefix_cache] => []
[prompt_cache] => []
[default_prefix_id] => 0
[default_sort_order] => last_post_date
[default_sort_direction] => desc
[list_date_limit_days] => 0
[require_prefix] => 0
[allowed_watch_notifications] => all
[min_tags] => 0
[forum_type_id] => discussion
[type_config] => {"allowed_thread_types":["poll"]}
)
[_relations:protected] => Array
(
[Node] => XF\Entity\Node Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 55
[rootClass:protected] => XF\Entity\Node
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[title] => SemiWiki Main Forum ( Ask the Experts! )
[description] => Post your questions to the experts here!
[node_name] =>
[node_type_id] => Forum
[parent_node_id] => 1
[display_order] => 1
[display_in_list] => 1
[lft] => 2
[rgt] => 3
[depth] => 1
[style_id] => 0
[effective_style_id] => 0
[breadcrumb_data] => {"1":{"node_id":1,"title":"Main Category","depth":0,"lft":1,"node_name":null,"node_type_id":"Category","display_in_list":true}}
[navigation_id] =>
[effective_navigation_id] =>
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[24966] => ThemeHouse\XPress\XF\Entity\Thread Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 129
[rootClass:protected] => XF\Entity\Thread
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[thread_id] => 24966
[node_id] => 2
[title] => Google in talks with Marvell to build new AI chips, The Information reports
[reply_count] => 13
[view_count] => 1611
[user_id] => 5
[username] => Daniel Nenni
[post_date] => 1776695933
[sticky] => 0
[discussion_state] => visible
[discussion_open] => 1
[discussion_type] => discussion
[first_post_id] => 99306
[first_post_reaction_score] => 0
[first_post_reactions] => []
[last_post_date] => 1776916852
[last_post_id] => 99379
[last_post_user_id] => 3419
[last_post_username] => ChrisGar
[prefix_id] => 0
[tags] => []
[custom_fields] => []
[vote_score] => 0
[vote_count] => 0
[featured] => 0
[type_data] => []
[index_state] => default
)
[_relations:protected] => Array
(
[User] => ThemeHouse\XLink\XF\Entity\User Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 62
[rootClass:protected] => XF\Entity\User
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[user_id] => 5
[username] => Daniel Nenni
[username_date] => 0
[username_date_visible] => 0
[email] => dnenni@semiwiki.com
[custom_title] => Founder
[language_id] => 1
[style_id] => 0
[style_variation] =>
[timezone] => America/Los_Angeles
[visible] => 1
[activity_visible] => 1
[user_group_id] => 3
[secondary_group_ids] => 4,5,132
[display_style_group_id] => 3
[permission_combination_id] => 88
[message_count] => 15512
[question_solution_count] => 0
[conversations_unread] => 0
[register_date] => 1280720820
[last_activity] => 1777310075
[last_summary_email_date] => 1605968657
[trophy_points] => 113
[alerts_unviewed] => 77
[alerts_unread] => 77
[avatar_date] => 1663211649
[avatar_width] => 110
[avatar_height] => 107
[avatar_highdpi] => 0
[avatar_optimized] => 0
[gravatar] =>
[user_state] => valid
[security_lock] =>
[is_moderator] => 1
[is_admin] => 1
[is_banned] => 0
[reaction_score] => 9399
[warning_points] => 0
[is_staff] => 1
[secret_key] => 0HwyUVVHCwJotUUVEpvqAclfYJdGNPpw
[privacy_policy_accepted] => 0
[terms_accepted] => 0
[vote_score] => 0
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[Forum] => XF\Entity\Forum Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 56
[rootClass:protected] => XF\Entity\Forum
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[discussion_count] => 8563
[message_count] => 62673
[last_post_id] => 99485
[last_post_date] => 1777323278
[last_post_user_id] => 35301
[last_post_username] => Xebec
[last_thread_id] => 24989
[last_thread_title] => South Korea’s K-shaped economy where chip giants give out $1 million bonuses to staff
[last_thread_prefix_id] => 0
[moderate_threads] => 0
[moderate_replies] => 0
[allow_posting] => 1
[count_messages] => 1
[auto_feature] => 0
[find_new] => 1
[allow_index] => allow
[index_criteria] =>
[field_cache] => []
[prefix_cache] => []
[prompt_cache] => []
[default_prefix_id] => 0
[default_sort_order] => last_post_date
[default_sort_direction] => desc
[list_date_limit_days] => 0
[require_prefix] => 0
[allowed_watch_notifications] => all
[min_tags] => 0
[forum_type_id] => discussion
[type_config] => {"allowed_thread_types":["poll"]}
)
[_relations:protected] => Array
(
[Node] => XF\Entity\Node Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 55
[rootClass:protected] => XF\Entity\Node
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[title] => SemiWiki Main Forum ( Ask the Experts! )
[description] => Post your questions to the experts here!
[node_name] =>
[node_type_id] => Forum
[parent_node_id] => 1
[display_order] => 1
[display_in_list] => 1
[lft] => 2
[rgt] => 3
[depth] => 1
[style_id] => 0
[effective_style_id] => 0
[breadcrumb_data] => {"1":{"node_id":1,"title":"Main Category","depth":0,"lft":1,"node_name":null,"node_type_id":"Category","display_in_list":true}}
[navigation_id] =>
[effective_navigation_id] =>
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[24970] => ThemeHouse\XPress\XF\Entity\Thread Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 133
[rootClass:protected] => XF\Entity\Thread
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[thread_id] => 24970
[node_id] => 2
[title] => Anthropic takes $5B from Amazon and pledges $100B in cloud spending in return
[reply_count] => 2
[view_count] => 849
[user_id] => 36640
[username] => soAsian
[post_date] => 1776796632
[sticky] => 0
[discussion_state] => visible
[discussion_open] => 1
[discussion_type] => discussion
[first_post_id] => 99347
[first_post_reaction_score] => 1
[first_post_reactions] => {"4":1,"3":1}
[last_post_date] => 1776849305
[last_post_id] => 99362
[last_post_user_id] => 24009
[last_post_username] => Jozo035
[prefix_id] => 0
[tags] => []
[custom_fields] => []
[vote_score] => 0
[vote_count] => 0
[featured] => 0
[type_data] => []
[index_state] => default
)
[_relations:protected] => Array
(
[User] => ThemeHouse\XLink\XF\Entity\User Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 114
[rootClass:protected] => XF\Entity\User
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[user_id] => 36640
[username] => soAsian
[username_date] => 0
[username_date_visible] => 0
[email] => jackmtsai@gmail.com
[custom_title] =>
[language_id] => 1
[style_id] => 0
[style_variation] =>
[timezone] => America/Chicago
[visible] => 1
[activity_visible] => 1
[user_group_id] => 2
[secondary_group_ids] =>
[display_style_group_id] => 2
[permission_combination_id] => 8
[message_count] => 425
[question_solution_count] => 0
[conversations_unread] => 0
[register_date] => 1608139716
[last_activity] => 1777272295
[last_summary_email_date] => 1719670845
[trophy_points] => 63
[alerts_unviewed] => 0
[alerts_unread] => 0
[avatar_date] => 0
[avatar_width] => 0
[avatar_height] => 0
[avatar_highdpi] => 0
[avatar_optimized] => 0
[gravatar] =>
[user_state] => valid
[security_lock] =>
[is_moderator] => 0
[is_admin] => 0
[is_banned] => 0
[reaction_score] => 389
[warning_points] => 0
[is_staff] => 0
[secret_key] => 2oKeCTFkGUpMro5tcmj7WaY9HksB13Kw
[privacy_policy_accepted] => 1608139716
[terms_accepted] => 1608139716
[vote_score] => 0
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[Forum] => XF\Entity\Forum Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 56
[rootClass:protected] => XF\Entity\Forum
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[discussion_count] => 8563
[message_count] => 62673
[last_post_id] => 99485
[last_post_date] => 1777323278
[last_post_user_id] => 35301
[last_post_username] => Xebec
[last_thread_id] => 24989
[last_thread_title] => South Korea’s K-shaped economy where chip giants give out $1 million bonuses to staff
[last_thread_prefix_id] => 0
[moderate_threads] => 0
[moderate_replies] => 0
[allow_posting] => 1
[count_messages] => 1
[auto_feature] => 0
[find_new] => 1
[allow_index] => allow
[index_criteria] =>
[field_cache] => []
[prefix_cache] => []
[prompt_cache] => []
[default_prefix_id] => 0
[default_sort_order] => last_post_date
[default_sort_direction] => desc
[list_date_limit_days] => 0
[require_prefix] => 0
[allowed_watch_notifications] => all
[min_tags] => 0
[forum_type_id] => discussion
[type_config] => {"allowed_thread_types":["poll"]}
)
[_relations:protected] => Array
(
[Node] => XF\Entity\Node Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 55
[rootClass:protected] => XF\Entity\Node
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[title] => SemiWiki Main Forum ( Ask the Experts! )
[description] => Post your questions to the experts here!
[node_name] =>
[node_type_id] => Forum
[parent_node_id] => 1
[display_order] => 1
[display_in_list] => 1
[lft] => 2
[rgt] => 3
[depth] => 1
[style_id] => 0
[effective_style_id] => 0
[breadcrumb_data] => {"1":{"node_id":1,"title":"Main Category","depth":0,"lft":1,"node_name":null,"node_type_id":"Category","display_in_list":true}}
[navigation_id] =>
[effective_navigation_id] =>
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[populated:protected] => 1
)
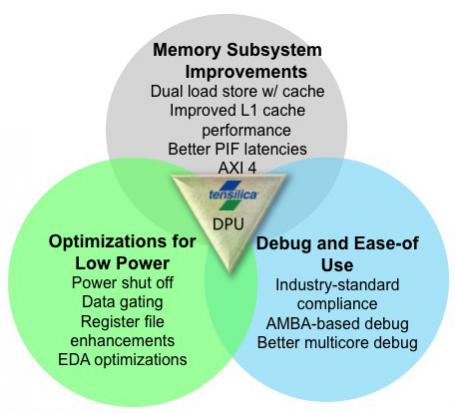
 Now they are onto the tenth generation. The problems have changed a lot over time. Well, mainly the performance requirements have only gotten higher and higher but the power budgets have…not. Tensilica’s processors are often used to offload the control processor in various applications, or to create systems with performance that cannot be approached with a general purpose processor. Terabit data rates for example. Usually the big motivation is power: offload the application processor in a smartphone to play mp3 at much lower power, or design an LTE modem without requiring a power hungry multicore general purpose processor. Back in 1997 we didn’t worry much about power.
Now they are onto the tenth generation. The problems have changed a lot over time. Well, mainly the performance requirements have only gotten higher and higher but the power budgets have…not. Tensilica’s processors are often used to offload the control processor in various applications, or to create systems with performance that cannot be approached with a general purpose processor. Terabit data rates for example. Usually the big motivation is power: offload the application processor in a smartphone to play mp3 at much lower power, or design an LTE modem without requiring a power hungry multicore general purpose processor. Back in 1997 we didn’t worry much about power.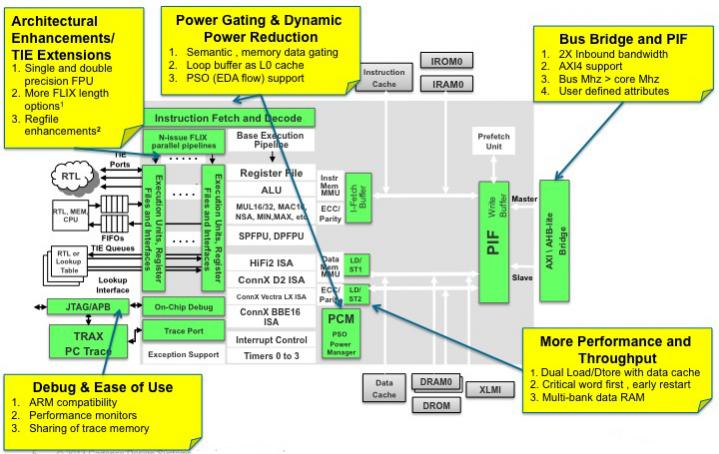
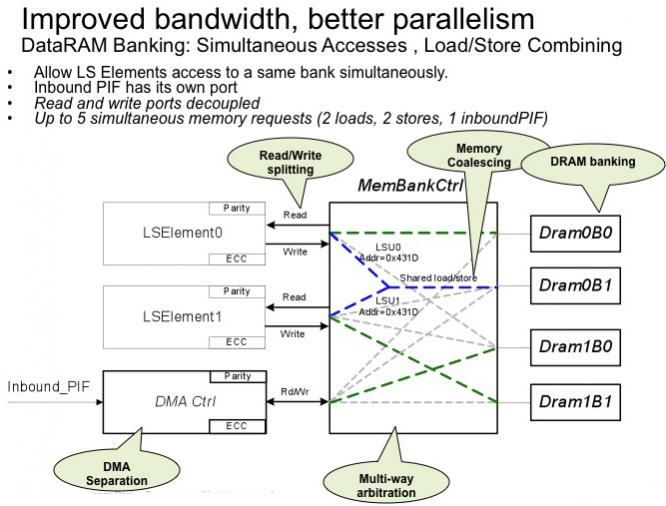




Comments
There are no comments yet.
You must register or log in to view/post comments.