
To create quantum computing chips today, a typical designer must cobble various tools together, switching back and forth between them for different tasks. By contrast, EDA solutions such as Keysight Advanced Design System (ADS) unify a design workflow in a single interface with automated data exchange between features. In … Read More

Author: Don Dingee
QuantumPro unifies superconducting qubit design workflow
Chiplet ecosystems enable multi-vendor designs
Chiplets dominate semiconductor industry conversations right now – and after the recent Chiplet Summit, we expect the intensity to go up a couple of notches. One company name often heard is Blue Cheetah, and we had the opportunity to sit down with them recently to discuss their views and their just-announced design win at Tenstorrent.… Read More
WEBINAR: FPGA-Accelerated AI Speech Recognition
The three-step conversational AI (CAI) process – automatic speech recognition (ASR), natural language processing, and text-to-synthesized speech response – is now deeply embedded in the user experience for smartphones, smart speakers, and other devices. More powerful large language models (LLMs) can answer more queries… Read More
NoCs give architects flexibility in system-in RISC-V design
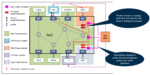
RISC-V tends to generate excitement over the possibilities for the processor core, any custom instruction extensions, and its attached memory subsystem. Those are all necessary steps to obtaining system-level performance. But is that attention sufficient? Architects who have ventured into larger system-on-chip (SoC) … Read More
Automotive-grade MIPI PHY IP drives multi-sensor solutions

Sensors are critical to every new automotive design, whether created for a driver or self-driving. Frame rates and resolution for car, truck, and SUV imaging systems continue to rise. Getting data from each sensor to a location in the vehicle with sufficient processing power may be challenging, especially when AI inference algorithms… Read More
Pairing RISC-V cores with NoCs ties SoC protocols together
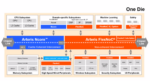
Designers have many paths for differentiating RISC-V solutions. One path launches into various RISC-V core customizations and extensions per the specification. Another focuses on selecting and assembling IP blocks in a complete system-on-chip (SoC) design around one or more RISC-V cores. A third is emerging: interconnecting… Read More
Keysight EDA 2024 Delivers Shift Left for Chiplet and PDK Workflows
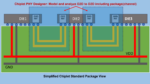
Much of the recent Keysight EDA 2024 announcement focuses on high-speed digital (HSD) and RF EDA features for Advanced Design System (ADS) and SystemVue users, including RF System Explorer, DPD Explorer (for digital pre-distortion), and design elements for 5G NTN, DVB-S2X, and satcom phased array applications. Two important… Read More
Deeper RISC-V pipeline plows through vector-scalar loops

Many modern processor performance benchmarks rely on as many as three levels of cache staying continuously fed. Yet, new data-intensive applications like multithreaded generative AI and 4K image processing often break conventional caching, leaving the expensive execution units behind them stalled. A while back, Semidynamics… Read More
Scaling LLMs with FPGA acceleration for generative AI

Large language model (LLM) processing dominates many AI discussions today. The broad, rapid adoption of any application often brings an urgent need for scalability. GPU devotees are discovering that where one GPU may execute an LLM well, interconnecting many GPUs often doesn’t scale as hoped since latency starts piling up with… Read More
Extending RISC-V for accelerating FIR and median filters
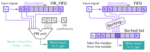
RISC-V presents a unique opportunity for designers to extend the microarchitecture with custom instructions. One possible application is digital signal filtering using finite impulse response (FIR) or median filters, potential algorithms for carrier demodulation schemes in communications systems like 5G. Codasip application… Read More







Silicon Insurance: Why eFPGA is Cheaper Than a Respin — and Why It Matters in the Intel 18A Era