Many modern processor performance benchmarks rely on as many as three levels of cache staying continuously fed. Yet, new data-intensive applications like multithreaded generative AI and 4K image processing often break conventional caching, leaving the expensive execution units behind them stalled. A while back, Semidynamics introduced us to their new highly customizable RISC-V core, Atrevido, with its Gazillion memory retrieval technology designed to solve more big data problems with a different approach to parallel fetching. We recently chatted with CEO and Founder Roger Espasa for more insight into what the deeper RISC-V pipeline and customizable core can do for customers.
Minimize taking your foot off the vector accelerator
We start with a deeper dive into the vector capability. It’s easy to think of cache misses as causing an outright pipeline stall, where all operations must wait until data moves refill the pipeline. A better-fitting metaphor for a long data-intensive pipeline, such as in Atrevido, may be a Formula 1 racecar. Wild hairpin corners may still require braking, but gentler turns around most circuits present an opportunity to stay on the accelerator, backing off as little as possible.
Few applications use vector math exclusively; scalar instructions sprinkled in the loop can cause a finely-tuned vector pipeline to sputter without proper handling. “Our obsession is to keep a deeper RISC-V pipeline busy at all times,” says Espasa. “So, we do whatever the memory pipeline needs, and in some cases, that may be a little bit more scalar performance.”
The Atrevido 423 core adds a 4-wide decode, rename, and issue/retire architecture designed to speed up mostly vector math with some scalar math mixed in. “The out-of-order pipeline coupled with 128 simultaneous fetches really helps get scalar instructions out of the way fast – 4-wide helps with that extra last bit of performance,” continues Espasa. “We can get back to the top of the loop, find more vector loads and start pulling those in while the scalar stuff at the tail end finishes.”

It’s worth noting everything happens without managing the ordering in software; the code just issues instruction primitives, and execution occurs when the data arrives. Espasa points out that one of the strengths of the RISC-V community is that his firm doesn’t need to work on a compiler; plenty of experts are working on that side, and the code is standard.
Vector units may appear a lot smaller than they are
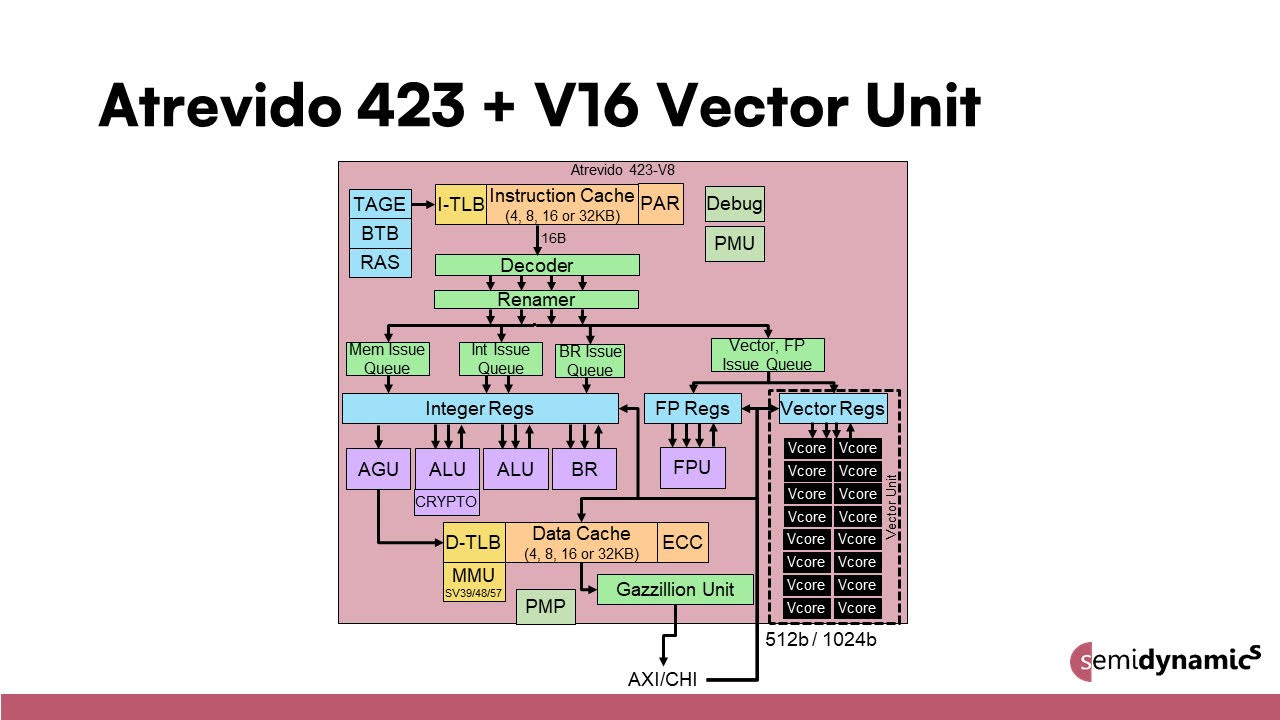
After seeing that vector unit in the diagram, we couldn’t resist asking Espasa one question: how big is the Atrevido vector unit in terms of area? Die size is a your-mileage-may-vary question with so much customizability and different process nodes. And when they say customizability, they mean it. Instead of one configuration – say, ELEN=64 and eight Vcores for a 512-bit DLEN engine standard in some other high-end CPU architectures – customers can pick their vector scale. The vector register length is also customizable from 1x up to 8x.

“We don’t disclose die area publicly, but our larger vector unit configurations are taking up something like 2/3rds of the area,” says Espasa. “We’ve started calling them Vcores because it’s easier to transition customer thinking from CUDA cores in GPUs.” He then interjects some customers are asking for more than one vector unit connected to each Atrevido core (!). The message remains the same: Semidynamics can configure and size elements of a RISC-V Atrevido to meet the customer’s performance requirements more efficiently than tossing high-end CPUs or GPUs at big data scenarios.
Some emerging use cases for a deeper RISC-V pipeline
We also asked Espasa what has happened that maybe he didn’t expect with early customer engagements around the Atrevido core. His response indicates a use case taking shape: lots of threads running on simpler models.
“We continuously get requests for new data types, and our answer is always yes, we can add that with some engineering time,” Espasa points out. int4 and fp8 additions say a lot about the type of application they are seeing: simpler, less training-intensive AI inference models, but hundreds or thousands of concurrent threads. Consider something like a generative AI query server where users hit it asynchronously with requests. One stream is no big deal, but 100 can overwhelm a conventional caching scheme. Gazillion fetches help achieve a deeper RISC-V pipeline scale not seen in other architectures.
There’s also the near-far imaging problem – having to blast through high frame rates of 4K images looking for small-pixel fluctuations that may turn into targets of interest. Most AI inference engines are good once regions of interest take shape, but having to process the entire field of the image slows things down. When we mentioned one of the popular AI inference IP providers and their 24-core engine, Espasa blushed a bit. “Let’s just say we work with customers to adapt Atrevido to what they need rather than telling them what it has to look like.”
It’s a recurring theme in the Semidynamics story: customization within the boundaries of the RISC-V specification takes customers where they need to go with differentiated, efficient solutions. And the same basic Atrevido architecture can go from edge devices to HPC data centers with deeper RISC-V pipeline scalability choices, saving power or adding performance. Find out more about the recent Semidynamics news at:
https://semidynamics.com/newsroom
Also Read:
Deeper RISC-V pipeline plows through vector-scalar loops
RISC-V 64 bit IP for High Performance
Configurable RISC-V core sidesteps cache misses with 128 fetches
Share this post via:




Comments
There are no comments yet.
You must register or log in to view/post comments.