
The world of AI algorithms continues to advance at a furious pace, and no industry is more dependent on those advances than automotive. While media and analysts continue to debate whether AI will deliver value in business applications, there is no question that it adds value to cars, in safety, some level of autonomous driving, and in comfort. But there’s a tension between these rapid advances and the 15-year nominal life of a car. Through that lifetime, software and AI models must be updated at service calls or through over-the-air updates. Such updates are now relatively routine for regular software, but AI advances are increasing stress on NPU architectures even more than they have in the past.
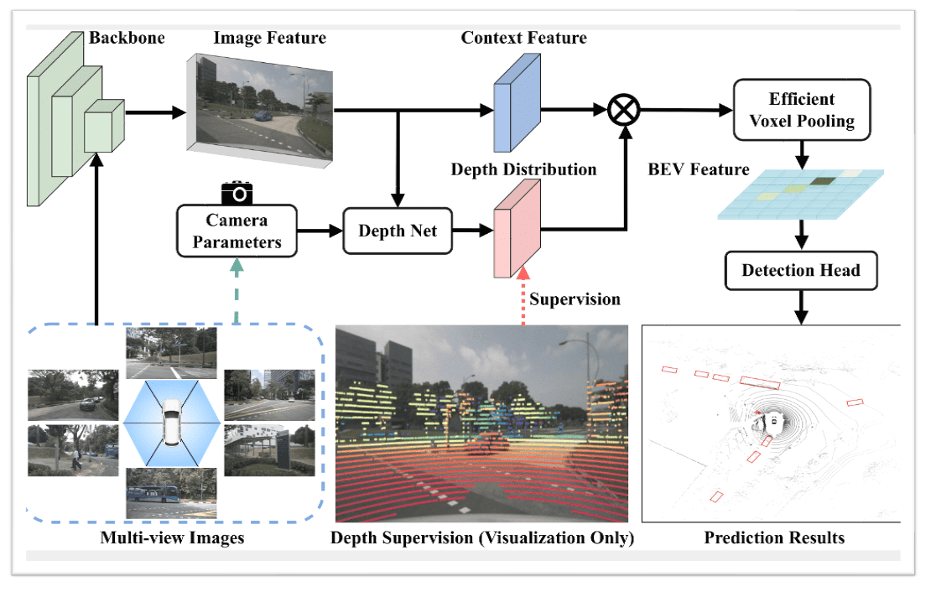
A BEVDepth algorithm (courtesy of GitHub)
From CNNs to Transformers to Fusion
For most of us CNNs were the first big breakthrough in AI, amply served by a matrix/vector engine (MACs) followed by a bit of ALU activity to wrap up the algorithm. Hardware was just that – a MAC array and a CPU. Transformers made this picture messier. The attention part is still handled by a matrix engine but the overall flow goes back and forth between matrix, vector and scalar operations. Still manageable in common NPUs with three engines (MAC, DSP, CPU) but traffic between these engines increases, adding latency unless the NPU and the model are optimized carefully for minimal overhead. Now add in fusion, depending on special operators which must be custom coded in C++ to run on the CPU. The important metric, inferences per second, depends heavily on model designer/implementor expertise.
This raises two important questions for any OEM or Tier1 planning around an NPU selection. First, what kind of performance can they expect for advanced algorithms for next generation designs? Second, will they need NPU provider expertise to code and optimize their proprietary/differentiating algorithms. Revealing company secrets is only part of the problem. The NPU market is still young and likely volatile, unlike the established CPU market. After committing to an NPU, who will take care of their model evolution needs over the 15-year life of a car?
Predicting what might be needed in the future is impossible, but it is certainly possible to look to model needs on the near horizon for a sense of which NPU architectures might best support adaptation to change. Quadric has an intriguing answer, citing some of the newer AI models such as BEVDepth.
Evolution in Bird’s Eye View (BEV) applications
If you have a relatively modern car you are probably already familiar with Bird’s Eye View as an aid to parallel parking. This is an option on your infotainment screen, an alternative to the backup camera view and the forward-facing camera view. BEV is the screen that shows a view from an imaginary camera floating six feet above the car, amazingly useful to judge how close you are to the car behind, the car in front, and the kerb.
This view is constructed through the magic of optics: multiple cameras around the car in effect project their images onto a focal plane at that imaginary camera location. The images are stitched together, with some adjustment, providing that bird’s-eye view.
Neat and useful, but model designers have larger aspirations than support for parallel parking. BEV is already making its way into some aspects of autonomous driving, especially as a near-range supplement to LIDAR or RADAR. But to be truly useful it needs to extend to a 3D view.
Adding depth information to BEV has stimulated a lot of research. Each camera contributes a different input to the BEV, not just as a slice of that view, but also through differing perspectives and intrinsic properties of the cameras. There are multiple proposed algorithms, of which one is BEVDepth. This algorithm uses point clouds from LIDAR as a reference for transformer-based depth learning around camera images.
An important step in this process involves voxel pooling. Pooling is a familiar step in CNNs, reducing the dimension of an image while preserving important features. Voxels are just the “3D pixels” you would expect in a 2D image (BEV) with depth. Voxel pooling is a complex algorithm and (in the GitHub version) is implemented in CUDA, the well-known NVIDIA programming standard. At nearly 200 lines of CUDA, this is not a simple operator to be added easily to the ONNX standard operator set. Further I am told this operation accounts for 60% of the compute cost of BEVDepth and must run on an ALU. Could you implement this on a regular NPU? Probably but apparently other NPU experts still haven’t delivered performance versions, while Quadric has already demonstrated their implementation.
A good fit for Quadric Chimera
You may not remember the key value prop for the Chimera NPU. These can be arranged as systolic arrays, nothing novel there. But each processing element (PE) in the array has MACs, an ALU, and local register memory wrapped in a processor pipeline. In switching between matrix, vector, and scalar operations, there’s no need to move data. Computation of all types can be handled locally as data flows through the array, rather than having to be swapped back and forth between matrix, DSP, and CPU engines.
Sounds good, but does it deliver? Quadric ran a benchmark of the Voxel Pooling algorithm, comparing performance on an Nvidia RTX 3090 chip versus a Quadric QC-Ultra (quad-core), running at the same clock frequency. The Quadric solution ran more than 2 times faster at substantially lower power. And here’s the clincher. While the algorithm is written in CUDA, the only difference between CUDA C++ and Quadric’s C++ is some easily understood memory pointer changes. Quadric was able to port the GitHub code in 2 weeks and claim anyone with C++ experience could have made the same changes. They claim the same applies to any operation which can be written in C++.
The takeaway is that a model as advanced as BEVDepth, supported by a key function written in CUDA, was easily mapped over to the Quadric platform and ran twice as fast as the same function running on an Nvidia chip at substantially lower power. Faster of course because Chimera is designed for IoT inferencing rather than heavy-duty training. Much lower power for the same reason. And programming is easily managed by an OEM or Tier1 C++ programmer. Ensuring that models can be maintained and upgraded long-term over the life of an automotive product line.
Staying current with AI innovation is a challenge in all markets, but none more so than in automotive. The NPU architecture you want to bet on must allow you to upgrade models in ways you can’t yet predict over 15-year lifespans. You need a solution your own software programmers can manage easily yet which offers all the performance advantages you expect from an NPU. You might want to checkout Quadric’s website.
Also Read:
2025 Outlook with Veerbhan Kheterpal of Quadric
Tier1 Eye on Expanding Role in Automotive AI
A New Class of Accelerator Debuts
Share this post via:




Comments
There are no comments yet.
You must register or log in to view/post comments.