
For what seems like a long time in the fast-moving world of AI, CNNs and their relatives have driven AI engine architectures at the edge. While the nature of neural net algorithms has evolved significantly, they are all assumed to be efficiently handled on a heterogenous platform processing through the layers of a DNN: an NPU for tensor operations, a DSP or GPU for vector operations and a CPU (or cluster) managing whatever is left over.
That architecture has worked well for vision processing where vector and scalar classes of operation don’t interleave significantly with the tensor layers. A process starts with normalization operations (grayscale, geometric sizing, etc), handled efficiently by vector processing. Then follows a deep series of layers filtering the image through progressive tensor operations. Finally a function like softmax, again vector-based, normalizes the output. The algorithms and the heterogenous architecture were mutually designed around this presumed lack of interleaving, all the heavy-duty intelligence being handled seamlessly in the tensor engine.
Enter transformers
The transformer architecture was announced in 2017 by Google Research/Google Brain to address a problem in natural language processing (NLP). CNNs and their ilk function by serially processing local attention filters. Each filter in a layer selects for a local feature – an edge, texture or similar. Stacking filters accumulate bottom-up recognition ultimately identifying a larger object.
In natural language the meaning of a word in a sentence is not determined solely by adjacent words in the sentence; a word some distance away may critically affect interpretation. Serially applying local attention can eventually pick up weighting from a distance but such influence is weakened. Better is global attention, looking at every word in a sentence simultaneously where distance is not a factor in weighting, evidenced by the remarkable success of large language models.
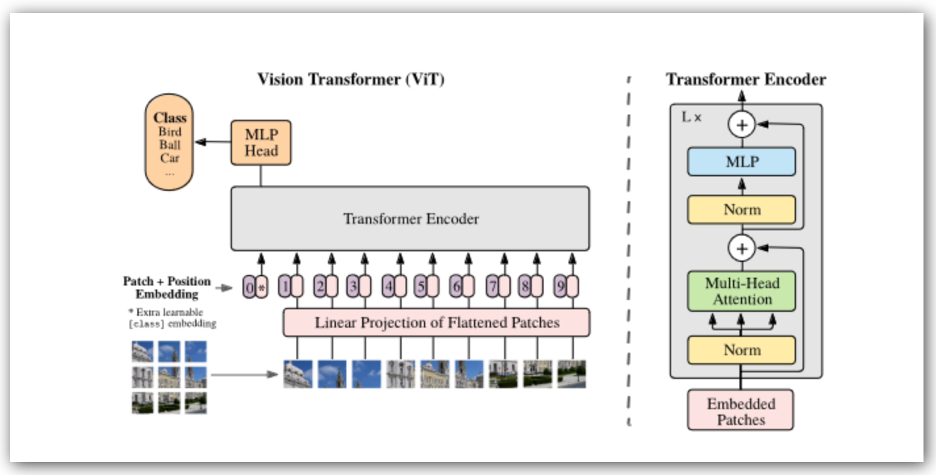
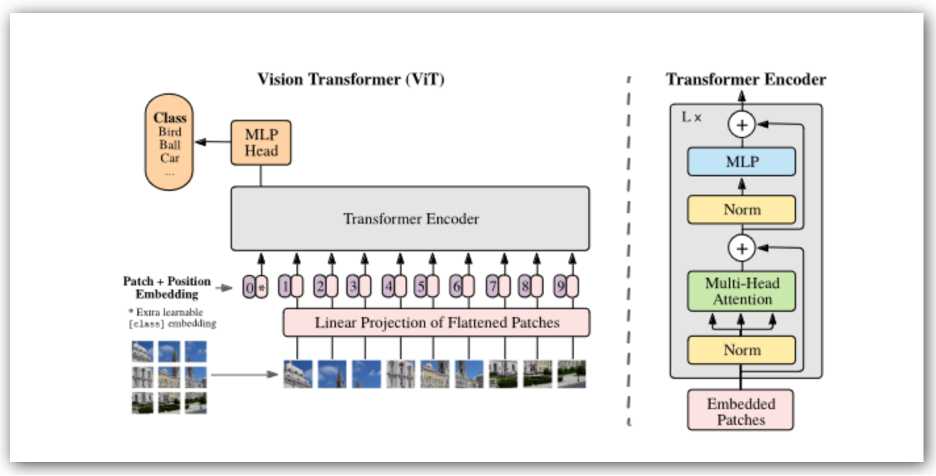
While transformers are known best in GPT and similar applications they are also gaining ground rapidly in vision transformers, known as ViT. An image is linearized in patches (say 16×16 pixels) then processed as a string through the transformer with ample opportunity for parallelization. For each the sequence is fed through a series of tensor and vector operations in succession. This repeats for however many encoder blocks the transformer supports.
The big difference from a conventional neural net model is that here tensor and vector operations are heavily interleaved. Running such an algorithm is possible on a heterogenous accelerator but frequent context switching between engines would probably not be very efficient.
What’s the upside?
Direct comparisons seem to show ViTs able to achieve comparable levels of accuracy to CNNs/DNNs, in some cases maybe with better performance. However more interesting are other insights. ViTs may be biased more to topological insights in a figure rather than bottom-up pixel-level recognition, which might account for them being more robust to image distortions or hacks. There is also active work on self-supervised training for ViTs which could greatly reduce training effort.
More generally, new architectures in AI stimulate a flood of new techniques, already apparent in many ViT papers over just the last couple of years. Which means that accelerators will need to be friendly to both traditional and transformer models. That bodes well for Quadric, whose Chimera General-Purpose NPU (GPNPU) processors are designed to be a single processor solution for all AI/ML compute, handling image pre-processing, inference, and post-processing all in the same core. Since all compute is handled in a single core with a shared memory hierarchy, no data movement is needed between compute nodes for different types of ML operators. You can learn more HERE.
Also Read:
An SDK for an Advanced AI Engine
Quadric’s Chimera GPNPU IP Blends NPU and DSP to Create a New Category of Hybrid SoC Processor
CEO Interview: Veerbhan Kheterpal of Quadric.io
Share this post via:



Comments
There are no comments yet.
You must register or log in to view/post comments.