Modern semiconductor devices, a far cry from the chips we once knew, are now highly complex intelligent systems used in datacenters, communications infrastructure, in consumer electronics, automotive, home and office automation, almost everywhere. All such applications build around large subsystems, invariably compute, often AI, sometimes vision/audio engines, always memory and communications subsystems, and more. Each subsystem hosts its own network-on-chip (NoC) connecting sub-functions together, as does the top-level design to connect between subsystems. These structures commonly incorporate a hierarchy of 5-20 NoCs per die/chiplet.
Even when the full system builds entirely on subsystems proven elsewhere, new spec and floorplan constraints may require several of these NoCs to be redesigned or refined, a potentially huge task impacting product schedules. Arteris’ AI-based NoC IP generator, FlexGen, aims to address this challenge. Rick Bye (Director of Product Management, Arteris) and Andy Nightingale (VP Product Management, Arteris) shared their insights with me.
(Source: Arteris, Inc.)
AI for Full-Chip NoC Optimization
We’re already seeing a trend to use AI in global optimization for electronic design: in physical design, in board design, in multiphysics analysis and optimization. These are all problems with huge search spaces, not amenable to traditional optimization techniques, better suited to heuristics learned over trials on historical data.
NoC optimization over a hierarchy of NoCs looks like a very similar problem. Optimizing based on learning over a range of topologies, floorplans, performance and QoS goals, drawing on prior experience which I bet Arteris has in abundance given the years they have been in this business. Then given a new design and network objectives with constraints defined at least to initial estimates, they are able to generate implementations of all those NoCs at the push of a button. I am told this is exactly what their field AEs do to launch evaluations. Pretty neat.
The Caveat
Automating the whole NoC design task through to signoff sounds ideal but reality is never quite that simple. Others have offered this hope but always fall short in lack of repeatability. Optimization may generate significantly different solutions between different design drops, improved certainly in some respects but adding new chaos in floorplanning, timing, QoS, on each new drop. Moreover, constraints provided to guide optimization are never complete, and lack understanding of some system objectives, design expert experience, even future product line objectives.
Automating generation is a very important step forward but it must allow for experts to provide incremental manual overrides where they see a need, and those manually supplied constraints should persist as the design evolves. The Arteris team stressed that this repeatability is why the current FlexGen is based on ML rather than a fancier AI foundation model. Given what I know of AI today, I can understand their caution.
That said, the objective of AI-centric generation is still to find a better PPA solution, faster. On the “faster” metric, Arteris claim generation times dropping from 20 hours to 4 hours, early optimization time (initial trials against a rough floorplan) dropping from 3 hours to 10 minutes and final optimization dropping from 2 weeks to 100 minutes. Even better, such turnaround times enable design teams to explore a wider range of options, getting to better global optima from topology generation to final signoff.
Results
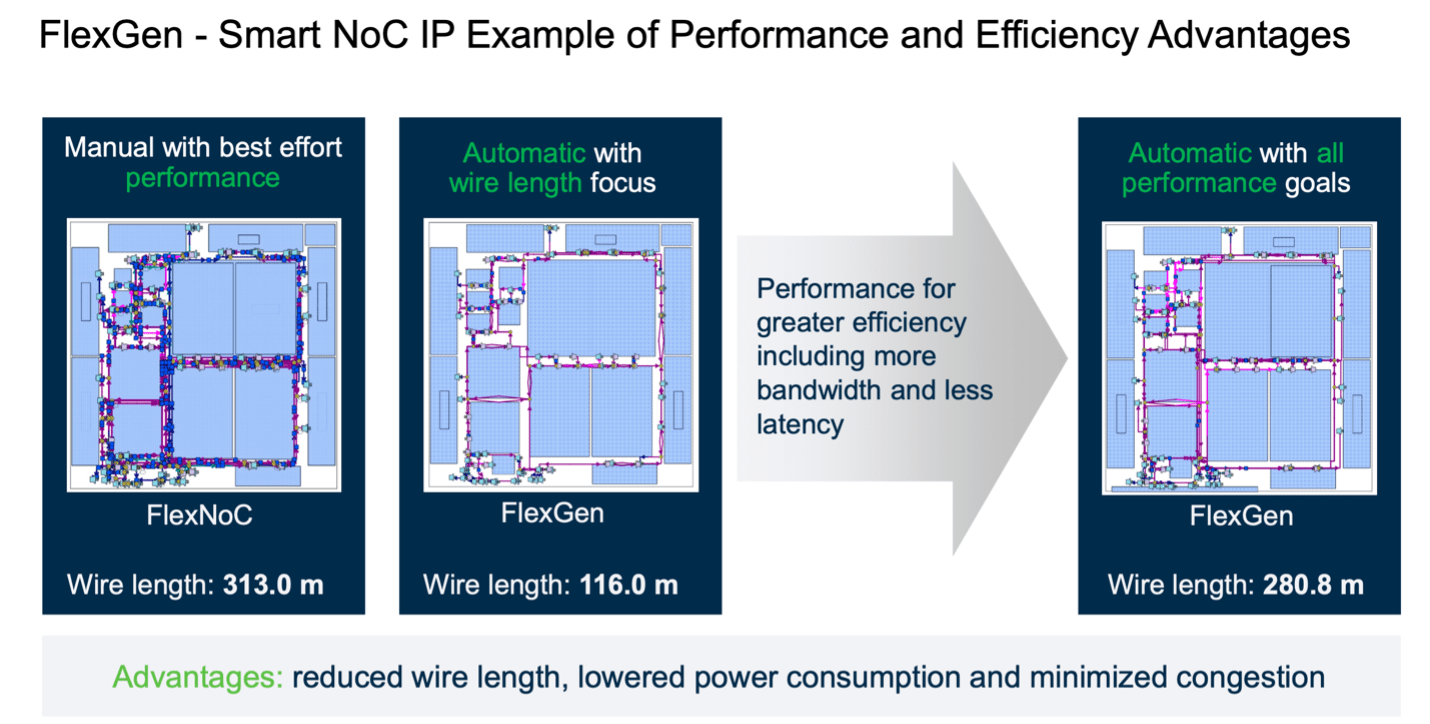
Those are the claims, how does FlexGen deliver in practice? Arteris ran trials on an in-house design (shown above), comparing on manually optimized FlexNoC implementations, tuning against different objectives to explore a range of possibilities. Optimizing just for wire length, they were able to drop total length from over 300 meters to just over 100 meters. Not a very realistic objective of course since this does not factor in performance but is still useful to see where the boundary is. An optimization acknowledging all performance goals still dropped total wirelength to 280 meters, a 10% reduction, with consequences for latency, power and area – improved PPA. Incidentally, a 10% optimization is very much in line with other AI optimizers in EDA.
Dream Chip Technologies used FlexGen on one of their designs, again comparing with a prior FlexNoC implementation. They found a 26% reduction in total wire length, 28% reduction in the longest wire, a 5% reduction in latency, 51% reduction in max latency and a 3% reduction in area. Again, improved PPA. All with a 10x boost in productivity versus effort invested on the manual implementation.
I’m impressed. Automated optimization delivering real improvements but within tightly controlled bounds to preserve repeatability. You can read the press release HERE and explore the product in more detail HERE.
Also Read:
Arteris Raises Bar Again with AI-Based NoC Design
MCUs Are Now Embracing Mainstream NoCs
Arteris Empowering Advances in Inference Accelerators
Share this post via:



Comments
There are no comments yet.
You must register or log in to view/post comments.