
AI for revolutionary business applications grabs all the headlines but real near-term growth is already happening, in consumer devices and in IoT. For good reason. These applications may be less eye-catching but are eminently practical: background noise cancellation in earbuds and hearing aids, keyword and command ID in voice control and face-ID in vision, predictive maintenance and health and fitness sensing. None of these require superhuman intelligence or revolutions in the way we work and live yet they deliver meaningful productivity/ease-of-use improvements. At the same time, they must be designed for milliwatt-level power levels and must be attractive to budget-conscious consumers and enterprises aiming to scale. Product makers in this space are already actively building and selling products for a wide range of applications and now have a common interest group (not yet standards) in the tinyML Foundation.
Requirements and Opportunity
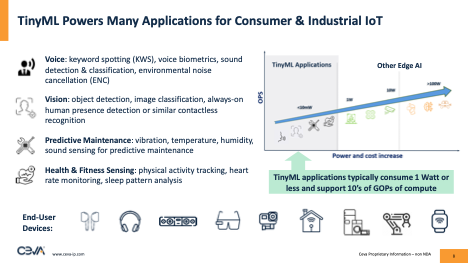
Activity around tiny ML is clear, but it’s worth stressing that the tinyML group isn’t (yet) setting hard boundaries on how a product qualifies to be in the group. However, per Elia Shenberger (Sr. Director Biz Dev, Sensors and Audio at CEVA) one common factor is power, less that a watt for the complete device, and milliWatts for the ML function. Another common factor is ML performance, up to hundreds of Gigaops per second.
These guidelines constrain networks to be small ML models running on battery-powered devices. Transformers/GenAI are not in scope (though see the end of this blog). Common uses will be for sensor data analytics for remote deployment with infrequent maintenance, and for always-on functions such as voice and anomalous sound detection or visual wake triggers. As examples of active growth, Raspberry PI (with AI/ML) is already proving very popular in industrial applications, and ST sees TinyML as the biggest driver of the MCU market within the next 10 years.
According to ABI Research, 4 billion inference chips for tinyML devices are expected to ship annually by 2028 with a CAGR of 32%. ABI also anticipate that by 2030 75% of inference-based shipments will run on dedicated tinyML hardware rather than general purpose MCUs.
A major factor in making this happen will almost certainly be cost, both hardware and software. Today a common implementation depends on an MCU for control and feature extraction (signal processing), followed by an NPU or accelerator to run the ML model. This approach incurs a double royalty overhead and will certainly result in a larger chip area/cost. It will also promote greater complexity in managing software, AI models, and data traffic between these cores. In contrast, single-core solutions with out-of-the-box APIs, libraries, and ported models based on open model zoos are going to look increasingly appealing.
Ceva-NeuPro-Nano
Ceva is already established in the embedded inference space with their NeuPro-M family of products. Recently they extended this family by adding NeuPro-Nano to address tinyML profiles. They claim some impressive stats versus alternative solutions: 10X higher performance, 45% die area, 80% lower on-chip memory demand and 3X lower energy consumption.
The architecture allows them to run control code, feature extraction and the AI model all within the same core. That reduces the burden on the MCU, allowing a builder to go with a smaller MCU or even dispense with that core altogether (depending on application). To understand why, consider two common tinyML applications: wake-word/command extraction from voice, and environmental noise cancellation. In the first, feature extraction consumes 36% of processing time, with the balance in the AI model. In the second, feature extraction consumes 68% of processing time versus the AI model. Clearly moving these into a common core with dedicated signal processing plus an ML engine is going to outperform a platform splitting feature extraction and AI model between 2 cores.
The NeuPro-Nano neural engine to run the AI model is scalable, supporting multiple MAC configurations and ML performance is further boosted through sparsity acceleration and activation acceleration for non-linear types such as sigmoid.
Proprietary weight compression technology dispenses with need for intermediate decompression storage, handling on-the-fly decompression as needed. Which significantly reduces need for on-chip SRAM – more cost reduction.
Power management is a key component in meeting tinyML objectives. Clever sparsity management minimizes calculations with zero weights, dynamic voltage and frequency scaling (tunable per application) can significantly reduce net power, and weight sparsity acceleration also reduces energy/bandwidth communication overhead.
Finally the core is designed to work directly with standard inference frameworks – TensorFlow Lite for Microcontrollers and μTVM – and offers a tinyML Model Zoo covering voice, vision and sensing use-cased and based on open libraries, pre-trained and optimized for NeuPro-Nano.
Future proofing
Remember that point about tinyML being a collaboration rather than a standards committee? The initial aims are quite clear; however these continue to evolve at least in discussion as applications continue to evolve. Maybe the ceiling for power will be pushed up, maybe bit-widths should cover a wider range to support on-device training, maybe some level of GenAI should be supported.
Ceva is ready for that. NeuPro-Nano already supports 4-bit to 32-bit accuracies as well as native transformer computation. As the tinyML goalposts move, NeuPro-Nano can move with them.
Ceva-NeuPro-Nano is already available. You can learn more HERE.
Share this post via:




Comments
There are no comments yet.
You must register or log in to view/post comments.