
As artificial intelligence (AI) and machine learning (ML) models continue to evolve at a breathtaking pace, the demands on hardware for inference and real-time processing grow increasingly complex. Traditional hardware architectures for acceleration are proving inadequate to keep up with these rapid advancements in ML models. Steve Roddy, Chief Marketing Officer at Quadric Inc., made a presentation on this topic, at the IPSoC Conference in Silicon Valley last month. His talk elaborated on why and where the traditional architectures fall short and how Quadric’s innovative Chimera General Purpose NPU (GPNPU) offers a superior, future-proof solution.
The Limitations of Traditional Architectures
Traditional heterogeneous architectures typically employ a combination of NPUs, DSPs, and CPUs to handle various aspects of ML inference and real-time processing. Each component brings its strengths to the solution. NPUs are optimized for matrix operations, DSPs for math kernel performance, and CPUs for general-purpose tasks. However, these strengths come with significant limitations. Managing the interplay between NPU, DSP, and CPU requires complex data transfers and synchronization, leading to increased system complexity and power consumption. Developers must contend with different programming environments and extensive porting efforts, making debugging across multiple cores even more challenging and reducing productivity. Moreover, fixed-function accelerators, like traditional NPUs, are designed to handle a limited set of operations.
The Evolution of AI/ML Models
In the early days of machine learning, hardware accelerators were designed to handle relatively simple and highly regular operations. State-of-the-art (SOTA) networks primarily consisted of matrix-style operations, which suited hardwired, non-programmable accelerators like NPUs. These NPUs provided efficient ML inference by focusing on matrix multiplications, pooling, and activation functions. However, this specialization limited their flexibility and adaptability as AI models evolved.
The introduction of transformer models, such as Vision Transformers (ViTs) and Large Language Models (LLMs), marked a significant shift in AI/ML complexity. Modern algorithms now incorporate a wide variety of operator types, far beyond the scope of traditional matrix operations. Today’s SOTA models, like transformers, utilize a diverse set of graph operators—ResNets may use around 8, while transformers can use up to 24. This diversity in operations challenges hardwired NPUs, which are not designed to handle such a broad range of tasks efficiently, highlighting the limitations of traditional NPU architectures. As ML models evolve, these accelerators quickly become obsolete, unable to support new operators and network topologies.
What About Operator Fallback?
To mitigate the limitations of fixed-function NPUs, traditional systems use a mechanism called “Operator Fallback.” This approach offloads the most common ML computation operators to the NPU, while the CPU or DSP handles the less common or more complex operations. The assumption is that fallback operations are rare and non-performance critical. However, this is a flawed assumption for several reasons. When fallback occurs, the CPU or DSP handles operations at significantly lower speeds compared to the NPU. This results in performance bottlenecks, where the slow execution of fallback operators dominates the overall inference time. Fallback requires seamless data transfer and control between the NPU and the programmable cores, adding to system complexity and power consumption. As ML models grow in complexity, the frequency and criticality of fallback operations increase, further degrading performance.
Quadric’s Chimera GPNPU
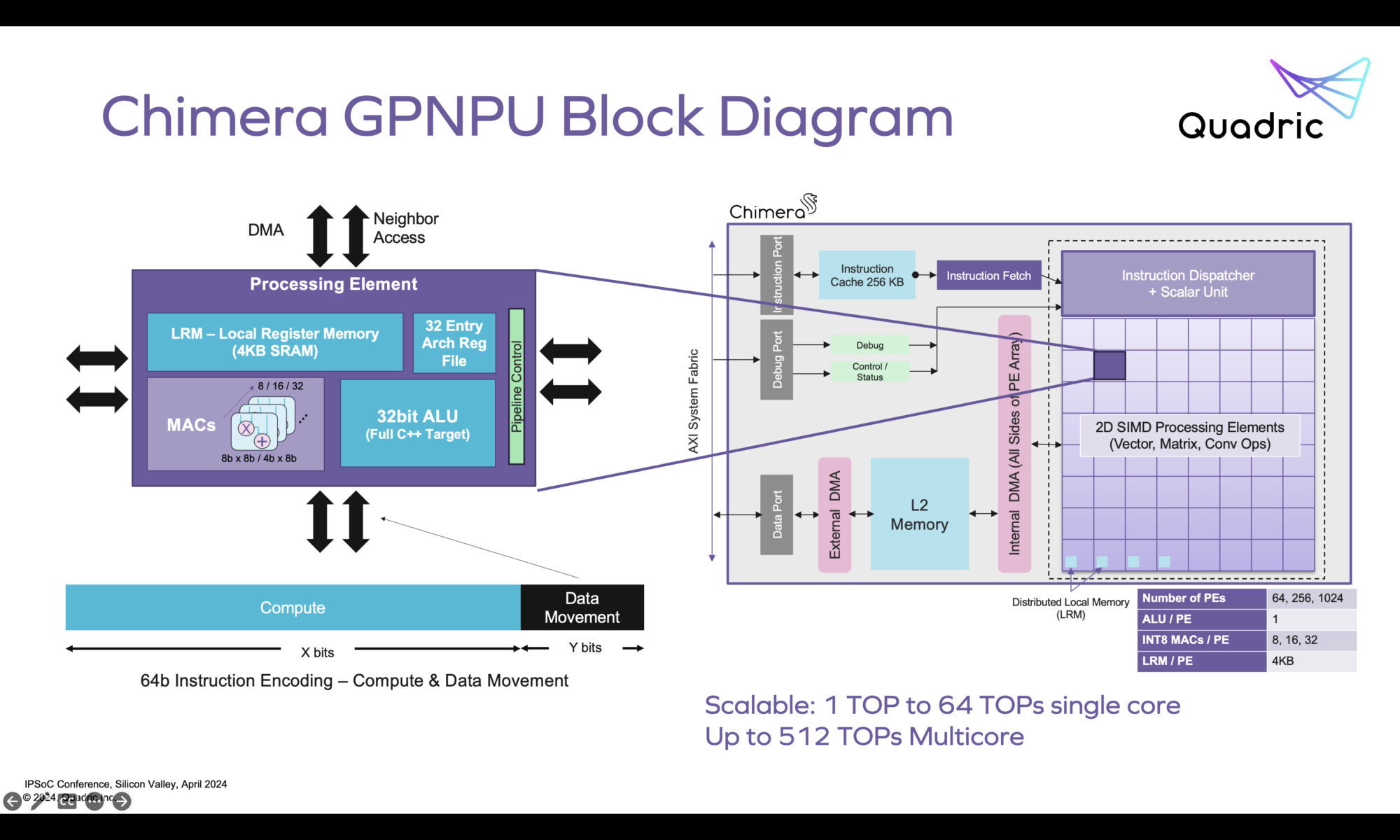
Quadric addresses these challenges with its Chimera GPNPU, an architecture designed to be as flexible and programmable as CPUs or DSPs, but with the performance of specialized accelerators.

Chimera consolidates the processing capabilities into a unified, single core architecture that runs all kernels as a C++ application. This simplifies SoC design by reducing the need for multiple specialized cores, easing integration and debugging. The GPNPU is purpose-built for matrix math and convolutions, maintaining high utilization similar to systolic arrays. This ensures excellent inference performance on ML tasks without relying on fallback. With the Chimera Graph Compiler, developers can auto-compile hundreds of networks and write/debug graph code and C++ code on one core, streamlining the development process and enhancing productivity. Chimera’s C++ programmability allows engineers to quickly add new ML operators, ensuring that the hardware can adapt to future ML models. This eliminates the risk of obsolescence associated with fixed-function accelerators.
By reducing the need for complex data transfers and synchronization between multiple cores, Chimera operates more efficiently, consuming less power. Available in 1 TOPS, 4 TOPS, and 16 TOPS variants, Chimera can scale to meet the demands of various applications, from low-power devices to high-performance systems.
View Chimera performance benchmarks on various neural networks here.
Summary
As ML models continue to evolve, the need for flexible, high-performance hardware becomes increasingly critical. Traditional architectures, relying on a combination of NPUs, DSPs, and CPUs, fall short due to their complexity, inefficiency, and risk of obsolescence. The fallback operator mechanism further exacerbates these issues, leading to significant performance bottlenecks.
Quadric’s Chimera GPNPU offers a compelling alternative, providing a unified, programmable architecture that eliminates the need for fallback. By addressing the inherent flaws of Operator Fallback, Quadric is setting a new standard for performance, flexibility, and future-readiness in ML computing. By simplifying SoC design, enhancing programming productivity, and ensuring future-proof flexibility, Chimera delivers a significant acceleration in ML inferencing and real-time processing.

Learn more at Quadric.
Also Read:
2024 Outlook with Steve Roddy of Quadric
Fast Path to Baby Llama BringUp at the Edge
Vision Transformers Challenge Accelerator Architectures
Share this post via:



Comments
There are no comments yet.
You must register or log in to view/post comments.