
I have observed before that the success of an AI engine at the edge rests heavily on the software interface to drive that technology. Networks trained in the cloud need considerable massaging to optimize for smaller and more specialized edge devices. Moreover, an AI task at the edge depends on a standalone pipeline demanding a mix of neural net/matrix, vector, and scalar/control operations with corresponding code for each, to manage stream pre-processing and post-processing in addition to inferencing. This is an overwhelming level of complexity for most product developers. Hiding that complexity while still maximally optimizing applications depends on a strong SDK and a unique engine architecture.

First, unify processing
The mainstream architecture for the intelligent edge combines a neural net for inference, a DSP for vector processing and a CPU/cluster for scalar processing and control. This approach amplifies programming complexity by forcing code partitioning and flow management between these separate platforms. The Quadric Chimera engine combines all three operation types in one processor with a unified instruction pipeline, starting with a common instruction fetch, then branching into a conventional ALU pipeline for scalar elements and a dataflow pipeline built on a 2D matrix of processing elements (PEs) and local registers for matrix/vector operations.
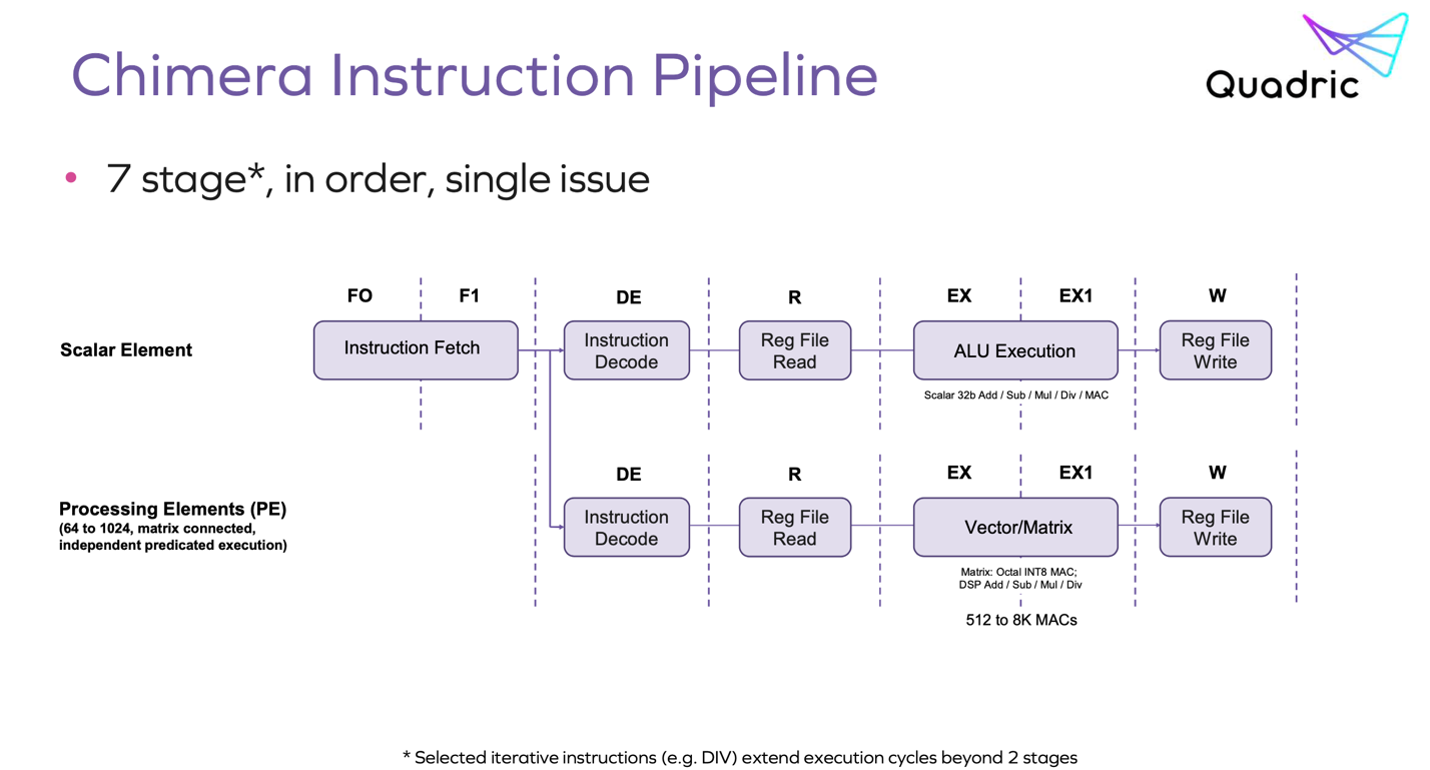
This structure allows scalar/control and matrix/vector operations to be modelessly interleaved. Unsurprisingly this architecture doesn’t support tricks like speculative execution but I’m guessing that is a small price to pay for simplifying the programming model. Also, I’m not sure such tricks even make sense in this context.
The programming model
I decided to first improve my understanding of inference programming as a foundation to see how the Quadric hardware/software supports that objective. Apologies to anyone who already knows this stuff, but it helped me. Programming in this domain means building graphs of pre-defined operations. There’s a nice example here of building a simple inference graph from scratch. Standard operations are defined by various ML frameworks. I found the ONNX format (an open standard) to be an easy starting point, with ~180 defined operations.
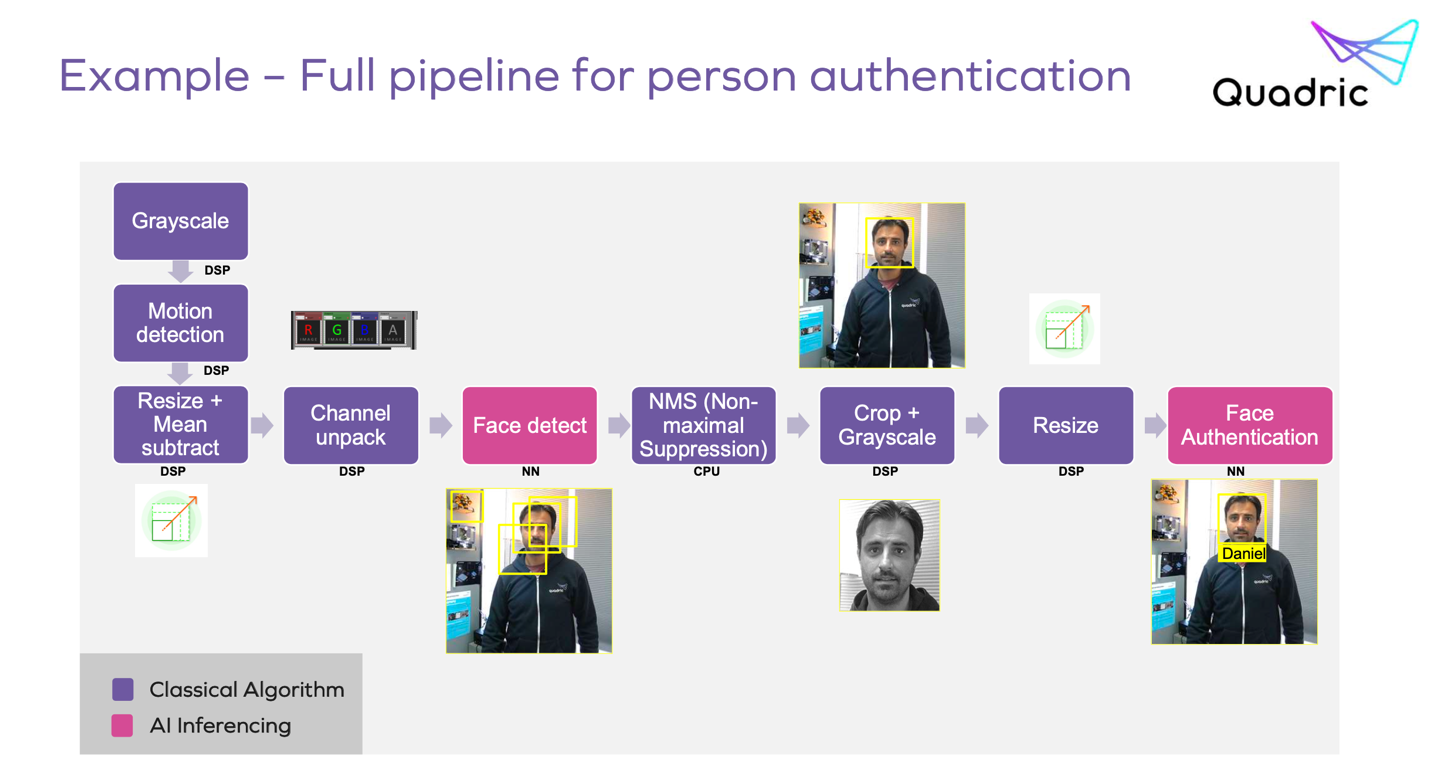
A framework trained model is structured as a graph, which (after optimization) will be embedded inside a larger inference pipeline graph. There may be more than one inference operation within the graph. Quadric share a nice 1D-graph example (below) for an employee identification system. This starts with a number of classical image processing functions. Then there is an inference step for face detection (a bounding box around the face), then again a few classical algorithm steps (selecting the most probable bounding box and some more image processing within that sub-image). Finally, another inference step for classification – is this a recognized employee?
Inference-centric operations are defined in the ONNX format or an equivalent, possibly supplemented by chip- or OEM-vendor operations for specialized layers. Other operations standard in a target application domain, such as standard image processing functions, would be supplied by the SDK. An OEM might also extend this set with one or two of their own differentiating features. What should be apparent from this pipeline is that the sequence of operations for this employee recognition system will ultimately require a mix of traditional CPU and matrix operations, in some cases possibly interleaved (for example in processing a custom layer or an operation not supported by the matrix processor).
Now for the Quadric SDK
With this target in mind, the Quadric SDK features and flow become very clear. Part of the solution is the DevStudio providing a graphical interface to drag/drop and connect pre-defined (or user-supplied) operations to build a graph. Again, pre-trained models from one of the standard training frameworks can be inserted into the graph. From this graph, DevStudio will build a C++ model which can be run through their Instruction Set Simulator (ISS) to profile against different Chimera core sizes, on-chip memory sizes and off-chip DDR bandwidth options. Once you are happy with the profile, you/the OEM can download the object code to an embedded implementation. In short, the AI architecture plus SDK provide developers the means to build, debug and maintain graph and C++ code on one core, not 3 separate cores. I have to believe this will be a popular option over more complex platforms.
The Chimera core is offered as an IP to embed in a larger SoC, consequently the SDK is expected integrate into the SoC vendor SDK. The SDK is now released; you can learn more HERE.
Share this post via:



Comments
There are no comments yet.
You must register or log in to view/post comments.