It has been a year since my article Semiconductor Landscape in Jan 2012 I wanted to look back into the major events over the year and then anticipate what’s in store going forward. What has happened over the year is much more than what I could foresee. Major consolidation in EDA space – Synopsys acquired Magma, SpringSoft, Ciranova, Eve; consolidation in semiconductor space – IBM acquired Texas Memory System, GlobalFoundries became independent of AMD, Micron is set to acquire Elpida and there were others. The point is that these consolidations are along the expected lines. One thing we have not seen yet is any indication of Qualcomm or Apple having their own foundries, although they could afford one profitably, if not for others’ designs, at least for their own needs. We may need to wait more to hear on that.
My tacit understanding in that article and still is that more consolidation will happen in coming years. Main reasons of consolidations are macroeconomic situation, business leadership, technology leadership and IP leadership. Let’s examine the scenarios from each of these perspectives and decipher from there what’s expected to happen –
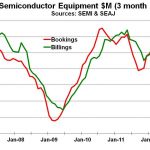
Macroeconomics – In 2012, there is 3% decline in Semiconductor revenue, $298B from $307B in 2011, published by Gartner. And considering the unforeseen catastrophe of Fiscal Cliff, EU crisis and slowdown in BRICS, I am not hopeful of any real growth in economy in a few years from now, rather contraction is possible. The future is uncertain. If some corporate in US, baring a few like Qualcomm and Apple, are well capitalized, that is due to government and Fed pumping money into the system. In such a situation weaker hands will get hold of the stronger hands and thereby consolidation will happen. Another aspect is of meagre operating profit margins which, in order to improve the bottom line, will eventually force artificial robots to do routine work. Management tools will evolve for general book keeping of man power to reduce management overhead. Jobs will be measured by tools and paid accordingly, automatically.
Business Leadership – Here I would like to take a few examples. First comes to my mind is memory business which is faltering; low profit, high volume. We have seen the fate of Elpida. Micron, a strong leader in this space is coming for its rescue. Second, Freescale Semiconductor is not doing well and can be acquired, either in parts or in whole. Although it is narrowing down its losses, challenging future may initiate it to sell some of its lucrative portfolio in RF products and micro controllers which Qualcomm and TI would like to happily adopt. Another indication in business leadership we can see is that while majority of semiconductor vendors (e.g. Samsung, Toshiba, TI) had decline in their revenue Qualcomm and Broadcom had increase in their revenue. That’s a clear indication that while strong ones will emerge stronger, weaker ones will be subdued.
Technology Leadership – This is an interesting area where technology leaders are always in dilemma on what kind of services to be outsourced. When the technology becomes too complex as in the case of sub 20nm process, close collaboration between technology leaders (Foundry, EDA, Design) become necessary. Clear evidence is about Apple starting its own chip design team. That is also related to protecting IP but technology is the driver for better
efficiency. Eventually technology drives business and hence small and mid-size and weak players will either close or coalesce with strong technology leaders.
IP Leadership – This is a niche space where an IP owner can stay as long as it wishes or can survive. That’s the reason it has a separate unique space. ARM has established itself as a large IP leader and will continue. New IP leaders will keep on emerging and merging with other IP or technology leaders at their will.
By Pawan Kumar Fangaria
EDA/Semiconductor professional and Business consultant
Email:Pawan_fangaria@yahoo.com