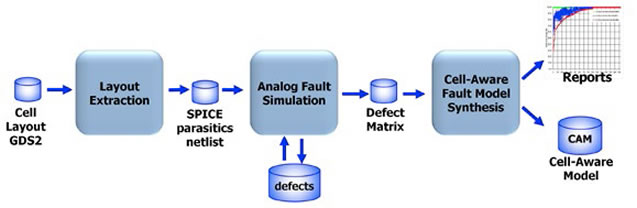
One of the challenges of physical design of a modern SoC is that of macro placement. Back when a design just had a few macros then the flooplanning could be handled largely manually. But modern SoCs suffer from a number of problems. A new white paper from Mentor covers Olympus-SOCs features to address these issues:
- As we move to smaller technology nodes we can put a lot more functionality on the same die. Not perhaps quite as much as you want since metal fabric is not scaling as fast as historically. The varying aspect ratios of the macros make it difficult to pack them tightly without wasting silicon area. Designers are left with the challenge of running multiple iterations to identify a reasonable configuration to take through full place and route.
- Poor seed placement. Floorplan designers typically run multiple trials using various seed placement configurations with the hope of finding the ideal solution. Since the quality of the initial placement is rarely optimal, you see an increase in both the number of trials with various seed placements and also the number iterations with the pre-CTS runs.
- Design space exploration. Conventional tools lack the ability to perform early design space exploration that considers various design metrics such as timing, area, leakage power, and congestion. This leads to inferior seed placement and also to performance and area being left on the table. There is typically no automated method to collate and present the results of all the trial macro placements done, so there is no way to make an informed decision on the full-blown implementation.
- Missing macro analysis functionality. Traditional tools provide very primitive macro analysis capabilities for determining whether a certain placement configuration is best suited for implementation. The analysis engines typically do not have the intelligence to analyze the connectivity through multiple sequential stages. Another drawback is that if a macro placement already exists for a block based on legacy design experience, the analysis functionality is either not supported or is very minimal. In order to determine the best placement, it is critical to have very powerful analysis and incremental what-if analysis capabilities.
- Pre clock-tree synhesis (CTS) optimization After getting the initial seed placement, there are typically many cycles iterating through the full blown pre-CTS flow to analyze timing, area, congestion and other design metrics before choosing a configuration for implementation. Because the seed placement QoR is often sub-par, the design needs to be analyzed to determine the feasibility of closing the design or block, which involves launching multiple trials in parallel. The pre-CTS runs are costly both in terms of resources and time, but can be eliminated with a good quality seed placement.
- The result of these problems causes more iterations and as a result the time to accomplish timing closure increases.
Olympus-SoC offers a completely automated macro placement (AMP) technology for both block level and hierarchical designs that delivers the best QoR in the shortest time. It offers tools for design space exploration to make the right trade-offs to meet various design metrics like timing, area, and congestion. AMP includes powerful what-if macro analysis capabilities for fine tuning macro placement results. The AMP flow significantly reduces the design time and eliminates weeks of manual iterations.
Olympus-SoC’s AMP technology offers the following features:
- Data flow graph driven macro placement and legalization
- Design space exploration with customizable recipes for parallel exploration
- Powerful macro analysis and refinement
- Completely automated flow with minimal manual intervention
The white paper covers the flow through the graph driven macro placement engine, how to assess quality of macro placement, refining the placement. There is a small case study.
The white paper is here.