SoC hardware designers could learn a thing or two from the world of software development, especially when it comes to the topic of managing complexity. Does that mean that hardware designers should literally use a software development environment, and force fit hardware design into file and class-based software methodologies? I don’t really think so, but it would make sense for hardware designers to use some best practices from software development that have been adapted to the unique IP-centric world of SoC design where it’s becoming more common to use hundreds of IP blocks.
A workspace is the name give to environment where SoC design including IP content and the metadata used to describe it are managed, and changes to IP are tracked. You could manually create workspaces and then manually track IP changes with a general purpose tool like Excel, however it would likely consume weeks of valuable engineering effort and the results would be error prone because you would have to manually alert other designers on your team every time a change to IP was made.
Manually managed workspaces introduce more issues like: the security of certain IP and who should have access, selecting the correct IP versions to avoid errors, and keeping network traffic and disk usage at a minimum.
Correct-by-construction Workspaces
Now that we know the risks of using a manual process, let’s define what a correct-by-construction workspace methodology should do for us:
- Centralized Management of all IP, where any change is automatically propagated to anyone of the design team.
- Centralized security by assigning the proper access to each IP block by each team member.
- Minimized disk usage by using a common, read-only version of IP blocks.
- View management where a designer can see all data views required.
- Multi-site support so that teams spread around the globe can see and use the IP to get their projects completed with a minimum latency, low network traffic and low disk storage.
Hardware design is not Software design
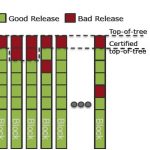
Chip designers run regressions, simulations and physical verifications that can take from minutes to days, and can consume large amounts of RAM and disk space, so it’s not practical to treat this like an Agile software development process that relies upon a “top-of-tree” approach. For SoC design a feasible approach is to to track which blocks have been fully verified in the context of the whole design, then add that to a certified top-of-tree:
ProjectIC from Methodics
Engineers at Methodicshave created ProjectIC as a platform to manage the IP lifecycle for both chip and IP designs that does create and track correct-by-construction workspaces.
One commonality between software and hardware development is that ultimately they are just collections of files. Popular data management tools like Perforce can be used for both hardware and software disciplines, however additions must be made to support an IP-centric design methodology. Hardware designs need to track IP metadata and have an IP abstraction layer enabled by IP metadata to be effective:
Features on top of data management for ProjectIC that enable correct-by-construction workspaces are:
- An IP catalog to list which IP release can be used.
- Central definitions so that you can control IP configurations for your design.
- Security through permissions control.
- Task specific workspaces for an IP block being designed.
- View management so that an RTL designer doesn’t need to check out the physical layout view.
- Automatic notifications of any new IP block release to anyone that is using that block.
- Minimized disk space usage by having remote or local data available to a workspace.
Further Reading
There’s a four page white paper from Methodics that goes into more detail and it can be downloaded here. There you’ll read about:
- Workspace management in practice
- Creating a workspace
- Editing Local IP data
- Releasing an IP
- Managing defects
- Improved collaboration
Another related white paper is called Data Management Best Practices, which covers how to effectively use DM for hardware design. There’s a brief registration process before you can download either white paper.
Conclusion
A correct-by-construction workspace approach will save you time, effort and provide peace of mind over a manually managed workspace methodology.