The internet of things (IoT) or internet of everything is a term that is into the red zone on the hype-meter. But it does genuinely have something of substance behind the hype. The thing that is a little deceptive is that the IoT term makes it sound like it is a market, but in fact it is several different markets: medical, automotive, industrial, metrology, fitness and more. But these different applications largely have several things in common. They are cost-sensitive, they require long battery life (or even scavenging power from the environment) and they require connectivity, almost always wireless.
My expectation is that very few IoT designs will be large SoCs in advanced FinFET processes. The costs are too high, the difficulty of doing the design is too high, and the need for that many gates doesn’t exist. As for many other classes of design, I think the sweet spot for some time will be 28nm. This is the last process node that doesn’t require the expense and delay of double patterning, a lot of capacity is in place from a number of foundries, and much of the equipment is depreciated. I am not alone in believing that 28nm will be a very long-lived process generation. But for IoT there is a problem: wireless interfaces require RF.
A couple of weeks ago GlobalFoundries announced a new 28nm process 28SLP-RF that is targeted at IoT and mobile applications. This is a process that is built on the foundation of the existing field-proven cost-optimized 28SLP process adding RF modeling. This is a HKMG (high-K metal gate). It is gate-first which GF claims is “up to” 30% cheaper than equivalent gate-last processes (10% mask adders, 10% power management and 10% area scaling disadvantage of gate-last).
I talked to Mike Chen (Deputy Director, Product Line Management) and Peter Rabbeni (Director, RF Segment Marketing) about the new process and the ecosystem around it. What is being announced is essentially adding an RF component to the existing ramped 28SLP process. GF already have some customers who have designed their own RF on top of the basic process but this is purely as a COT design. What is new is that the RF is being made available to anyone doing design at 28nm. The PDK exist and can be downloaded from the GF website (for qualified companies). There are reference flows.
Compared to the previous process node, 40LP, it has:
- Twice the gate density
- 36% speedup with full overdrive option
- 40% power reduction
- 1.6GHz performance for the ARM Cortex-A9
- And now RF
I asked Mike and Peter about IP. After all, most groups designing IoT applications are not really capable of designing radios on the bare silicon and even for groups who have in-house RF designers, it is slow and expensive to design a wireless interface. They told me that they were working to make available both bluetooth and WiFi interfaces although it was too early to tell me which company they were working with and giving early access to the process.
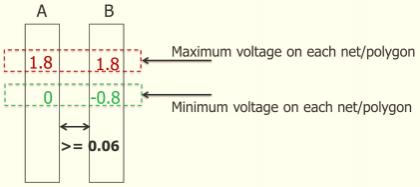
Silicon results have demonstrated high-frequency performance (310GHz) and low flicker/thermal noise providing chip designers flexibility in optimizing core RF performance and functionality. The 28SLP-RF process technology is designed for devices that require low standby power and long battery life integrated with RF/wireless functionality. The technology is enabled with key RF features, including core and I/O (1.5V/1.8V) transistor RF models along with 5V LDMOS devices, which simplifies RF SoC design. For passive RF devices, 28SLP-RF offers alternate polarity metal-oxide-metal (APMOM) capacitors up to 5V, deep n-well devices, diffusion, poly and precision resistors, inductors and an ultra-thick metal (UTM) layer.
The process is fully qualified from -40° to 125° and MPW shuttles run quarterly, and perhaps more frequently depending on demand and urgency. GF are already working with some lead customers. The expectation is that lead customers will have prototypes available late 2015 with production in 2016.
The press release with more details is here.