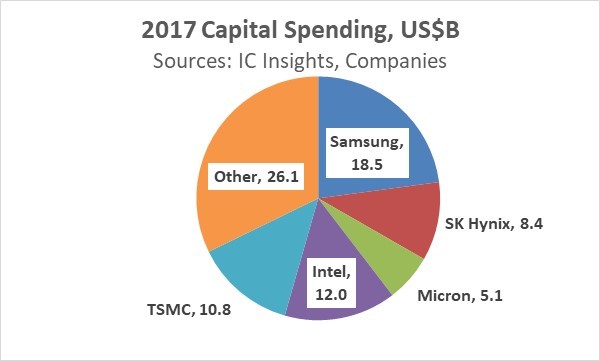
Semiconductor capital expenditures (cap ex) in 2017 will increase significantly from 2016. In August, Gartner forecast 2017 cap ex growth of 10.2% and IC Insights projected 20.2% growth. SEMI expects spending on semiconductor fabrication equipment will increase 37%. Cap ex growth is primarily driven by increased capacity for DRAM and flash memory. Of the three major memory companies, Samsung’s cap ex for 2017 could range from $15 billion (up 32%) to $22 billion (up 94%), according to IC Insights. The mid-range of IC Insights’ forecast for Samsung cap ex is $18.5 billion, up 63% and accounting for 23% of total industry cap ex. SK Hynix in July estimated 2017 cap ex of $8.4 billion, up 58%. Micron Technology spent $5.1 billion in its fiscal year ended August 2017, down 6%. However, Micron’s guidance for fiscal 2018 cap ex is $7.5 billion, up 47%.
Of the major non-memory spenders, Intel plans $12.0 billion in 2017 cap ex, up 25%. TSMC, the largest foundry company, only expect 6% growth in cap ex to $10.8 billion. The top five companies will account for about two-thirds of 2017 cap ex. The remaining companies should see cap ex growth of about 3%.
The history of the semiconductor industry has been high growth rates in capital spending leading to excess capacity. Eventually the excess capacity results in rising inventories and companies cutting prices in attempts to increase demand. When the excess capacity is combined with a decline in end market demand for semiconductors, the semiconductor market collapses. However, the current projections for 2017 cap ex are nowhere near the growth rates which have historically led to overcapacity and market downturns.
The table below shows periods of high cap ex growth over the last 34 years. High cap ex growth coincides with high semiconductor market growth – strong demand driving increased capacity investment. Since 1984, cap ex growth has been 75% or higher in four different years (1984, 1995, 2000 and 2010 – marked in red). The years in red are analogous to a red traffic light – indicating a stop or danger. In three of the cases (1984, 1995 and 2000), the following year saw a decline in the semiconductor market. In 2010 cap ex grew 118%. The market did not decline in 2011 but growth decelerated 31 percentage points from 32% in 2010 to 0.4% in 2011. The market declined 3% the following year in 2012.
In three other years cap ex growth has been below 75% but above 40% (1988, 1994 and 2004 – marked in yellow). The years in yellow are like a yellow traffic light – advising caution. In 1988-1989 the semiconductor market decelerated 30 points (from 38% to 8%) and in 2004-2005 the market decelerated 21 points (28% to 7%). 1994-1995 was an exception to the typical trend with cap ex growing 54% in 1994 and 75% in 1995. The semiconductor market grew 32% in 1994 and 42% in 1995. The collapse hit in 1996, with a 9% decline in the market, a 50-point deceleration.
Semiconductor market downturns are not always driven by overcapacity. The market declined in 1998, 2008, 2009, 2012 and 2015 due to economic factors and slowing end equipment demand.
High growth in semiconductor capital expenditures can be a warning sign of potential overcapacity. However, the current situation is not close to a caution or danger signal. The highest cap ex forecast of 20.2% from IC Insights is only half of the caution growth rate of 40%. Our Semiconductor Intelligence forecast in September was 18.5% semiconductor market growth in 2017 and 10% in 2018. The forecast assumes no overcapacity and no fall off in end market demand. There is a chance of high cap ex growth in 2018 leading to excess capacity in 2019, but we are not currently projecting this scenario.