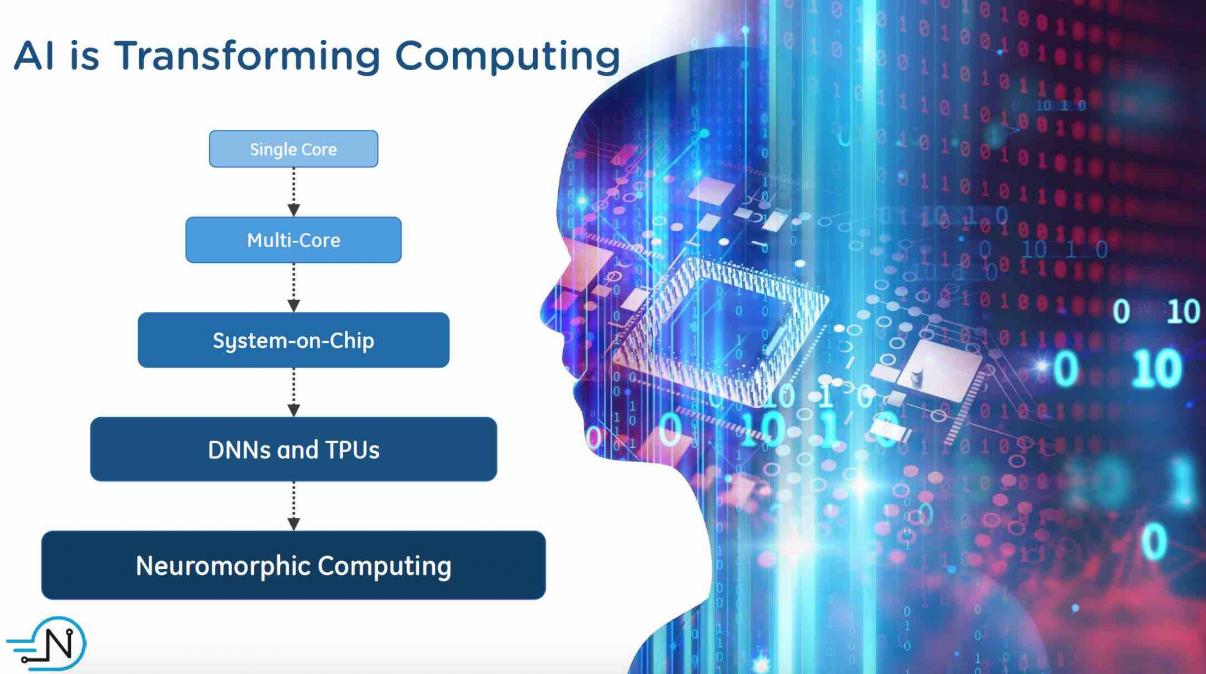
Artificial Intelligence based systems are driving a metamorphosis in computing, and consequently precipitating a large shift in SOC design. AI training is often done in the cloud and has requirements for handling huge amounts of data with forward and backward data connections. Inference usually occurs at the edge and must be power efficient and fast. Each of these imposes new requirements on computing systems. Training puts a premium on throughput and inference relies on low latency, especially for real time applications like ADAS.
To accommodate these new requirements, there are sweeping changes occurring in computational architectures. In much the same way that mini- and then micro- computers changed the landscape of computing, the changes necessitated to support AI will permanently alter how things are done.
The what and how of these changes was the topic of a presentation given by NetSpeed at the Linley Processor Conference on April 11[SUP]th[/SUP] in Santa Clara. The presentation by Anush Mohandass, VP of Marketing at NetSpeed, discusses how a smart interconnect fabric helps to enable embedded AI applications. Their first point was that AI is making its way into a large and broad number of applications. These include vision, speech, forecasting, robotics and diagnostics, among others.
Inside of these new SOCs there is a new data flow. A large number of compute elements which are small and efficient need to perform peer to peer data exchange rapidly and efficiently. There will be many multicast requests and the transfers should be non-blocking. Indeed, QoS becomes very important. Previous architectures operated differently, with processing units using a central memory as an interchange system.
AI systems need ‘any-to-any’ data exchanges that benefit from wide interfaces and need to support long bursts. However, the central requirement is that all the elements need to be active simultaneously. Naturally, it is easy to see that this can lead to power management issues that should be resolved with aggressive clock gating and traffic sensitive optimizations.
NetSpeed talked about their approach, which can help enable SOCs that have requirements like those imposed by AI applications. They provide the logic needed to integrate, coordinate and control the large number of types and instances of IPs in an SOC. This covers many facets: interconnect, cache coherency, system level cache, system level debug, bandwidth allocation, QoS controls, power management, and clock crossings. With so many parameters and requirements, what is really needed is a design environment specifically geared to implementing the optimal solution.
This is something NetSpeed offers. It supports an architectural design approach that starts off with a specification, and then helps work through the various tradeoffs. Their design environment provides feedback along the way and is checking for design correctness continually.
NetSpeed offers Orion for creating non-coherent interconnect. Their Gemini offering is for coherent system backbones. Their Crux backbone is architecture agnostic. Finally, for programmable L2, L3, and LLC cache they offer Pegasus. Their design environment assists with design and assembly. They use a machine learning based cognitive engine to help with implementation. The system outputs extensive data analytics and visualizations.
In much the same as TCP/IP offers a multi layered protocol that provides abstraction for data transmission on the internet, NetSpeed’s SOC solution uses a multi-layer protocol implementation to provide optimal performance and highest throughput. With this comes QoS, multicast support and no blocking behavior, needed for AI processing.
The NetSpeed presentation went into greater depth on the technology and is well worth reviewing. The big take away is that entirely new ways of design will be necessary to accommodate the needs of AI in future SOCs. It may come to pass that we look back at CPU based computing the way we do punched cards and magnetic tapes.