We have entered the age of AI specific processors, where specialized silicon is being produced to tackle the compute needs of AI. Whether they use GPUs, embedded programmable logic or specialized CPUs, many AI chips are based on parallel processing. This makes sense because of the parallel nature of AI computing. As a result, in silicon for these applications we are seeing large numbers of replicated processing elements and distributed memories. These large AI designs fortunately lend themselves to advanced DFT solutions that can take advantage of their architectural characteristics.
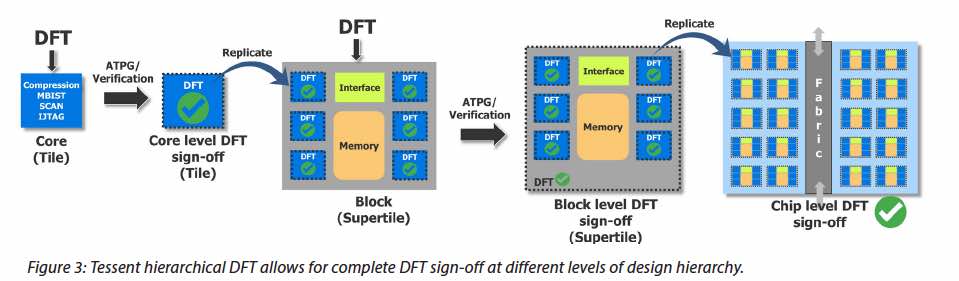
Mentor has produced a white paper, titled “AI Chip DFT Techniques for Aggressive Time to Market”, that talks about how the properties of many large AI chips can be leveraged to save DFT, ATPG and test time. The first step they recommend is to take advantage of AI chip regularity. They propose doing test insertion and pattern generation/verification at the core level. Hierarchical DFT, like that found in Mentor’s Tessent, can use hierarchically nested cores that are already signed off for DFT to run DFT on the entire design from the top level. Higher level blocks can include blocks or cores that have already had DFT sign-off. These in turn can be signed off and used repeatedly within a chip.
Tessent’s IJTAG allows plug and play for core replication and integration. It also offers automation for chip-level DFT configuration and management. The flexibility this allows for some interesting optimizations. One such case is where there are a large number of very small cores. Mentor suggests using hierarchical grouping of cores for test to reduce overhead and save time. This is a happy middle ground between too granular and completely flat ATPG.
Another optimization that their approach allows is channel broadcasting. This allows the same test data to be used for identical groups of cores. It reduces test time and the number of pins required. Tessent is smart enough to help optimize the configuration for channel broadcasting.
In addition to repeating logic elements, AI chips have a large number of smaller distributed memory elements. If each memory core had its own BIST controller this would require a large area overhead. With Tessent it is possible for one BIST controller to be shared among multiple memory cores. To go along with this they offer a shared-bus interface to optimize the connections to the BIST controller.
Another topic the white paper covers is their move to RTL for test insertion. When this is used, it is possible to run test verification before the synthesis. RTL verification runs much faster than gate level verification. Also, the debug process is easier. Moving test debug and verification to the RTL level means that synthesis is not required each time a test fix is made. Mentor has also implemented a number of testability checks at RTL that can save down-steam iterations during ATPG.
While AI is making the lives of end users easier, it is certainly creating a demand for increasingly powerful silicon for processing. Despite this growing complexity of silicon, there is a bright spot in the test arena. Mentor clearly has been investing in their DFT product line. The good news is that many of the characteristics of these AI chips create opportunities for improving the efficiency of the design process and the resulting design, particularly in the area of test. If you want to delve into the specifics of how Mentor proposes designers take advantage of DFT optimizations for AI chips, the white paper is available on their website.