

I’ll never forget first learning about Xilinx when they got started back in 1984, because the concept of a Field Programmable Gate Array (FPGA) was so simple and elegant, it was rows and columns of logic gates that a designer could program to perform any logic function, then connect that logic to IO pads to drive other chips on the board. At first their chips were used to gather up all of the glue-logic found on a printed circuit board which was hundreds of logic gates, but today that situation is drastically different because with the new Adaptive Compute Acceleration Platform (ACAP) architecture they have managed to pack 50 billion transistors on a single die with an impressive IP library.
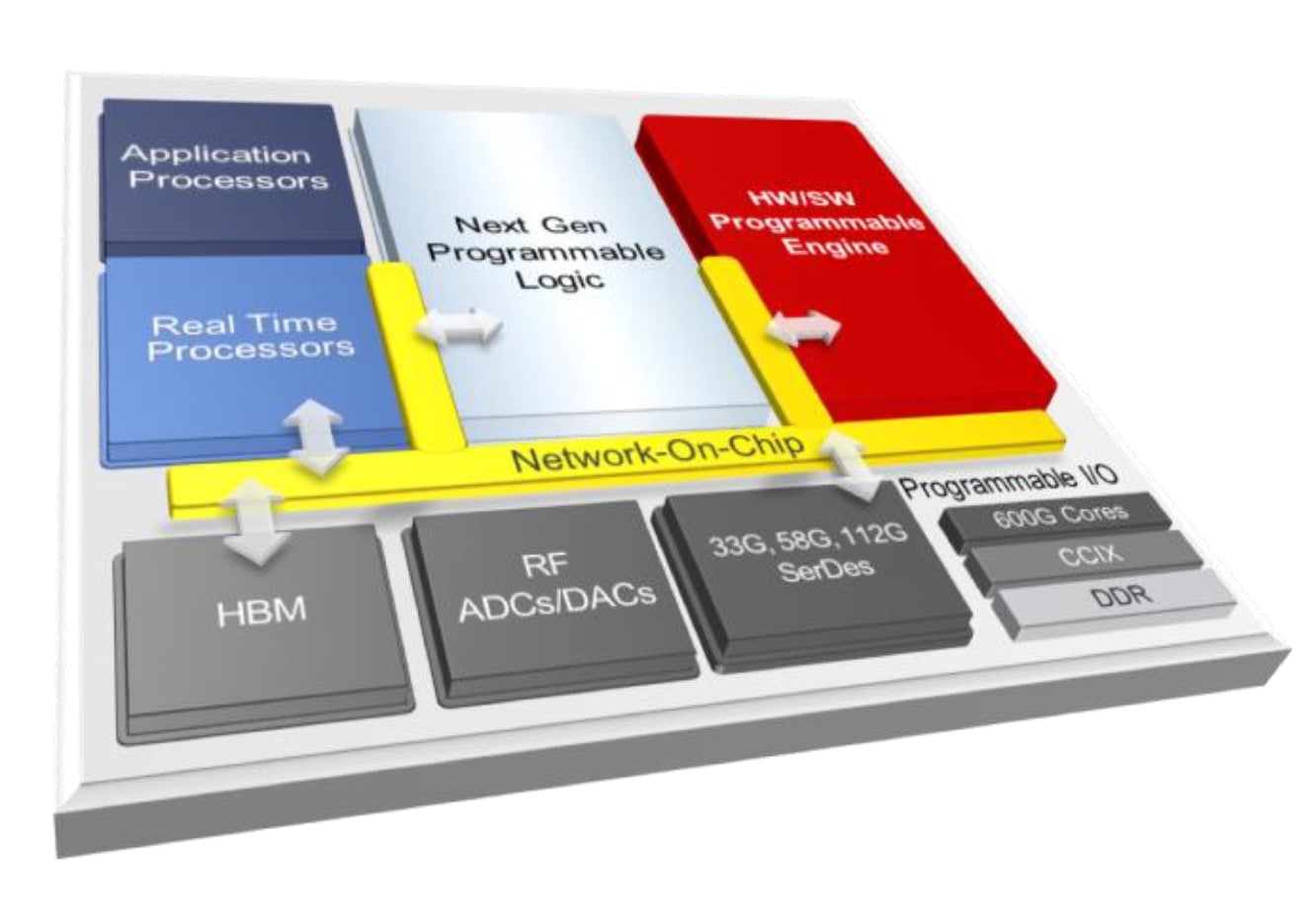
Xilinx has figured out how to offer SoC designers lots of features through IP blocks, and the fastest-growing market segments are loving it: AI, ADAS, IoT, Cloud computing, data center. Designers now have access to a wide range of configurable IP like:
- Application processors, ARM cores
- Real time processors
- High Bandwidth Memory (HBM)
- RF, ADC, DAC
- SerDes
- Programmable IO: CCX, DDR
- Network-On-Chip
- Programmable Logic
Nitin Navale from Xilinx presented at DAC on the topic, “IP Integration Challenges of Domain-Specific Architectures on Programmable SoC Platforms“, so I watched the 22 minute presentation and summarize the major findings in this blog.
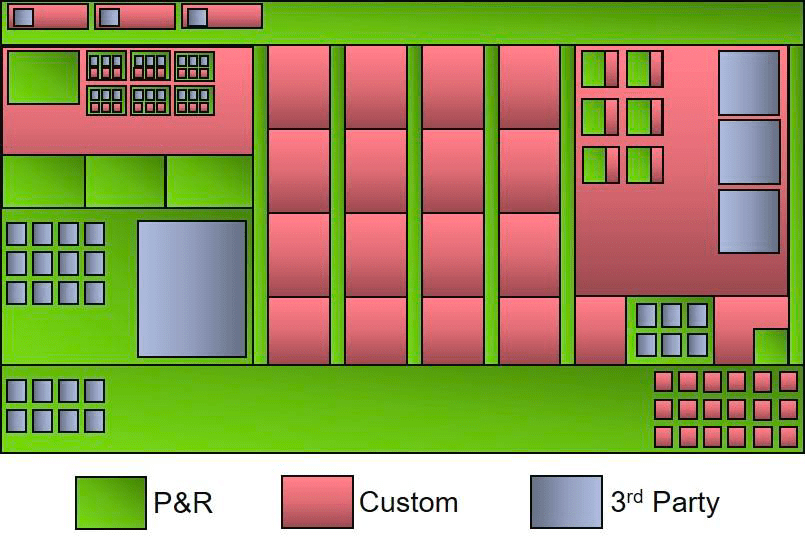
Near the end of an SoC project all of the physical IP needs to be integrated together in a correct manner, quickly and with disk storage efficiency. The top-level for a Xilinx chip is constructed in a hierarchical fashion, but with different layout styles, like: Custom layout, Place & Route (P&R). In addition, each IP block is either developed internally, or provided by a third party. Data formats for IP blocks can be in GDS II, LEF/DEF or the newer Oasis format.
Here’s a diagram showing how P&R blocks, custom blocks and 3rd party blocks can be assembled in a complex hierarchy to form a Xilinx SoC.
An IP block may contain P&R regions and some Custom, or P&R and some 3rd party, or Custom with P&R blocks, so lots of permutations are possible. It’s important that consistent versions of an IP are maintained across the entire hierarchy, so no mismatching versions can be allowed.
As an IP block has been verified clean and is no longer changing, it gets marked as Golden, so no further revisions are accepted. Having a QA methodology for checking and preserving IP integrity is a requirement, because getting to market with first-pass silicon success is what keeps a company profitable.
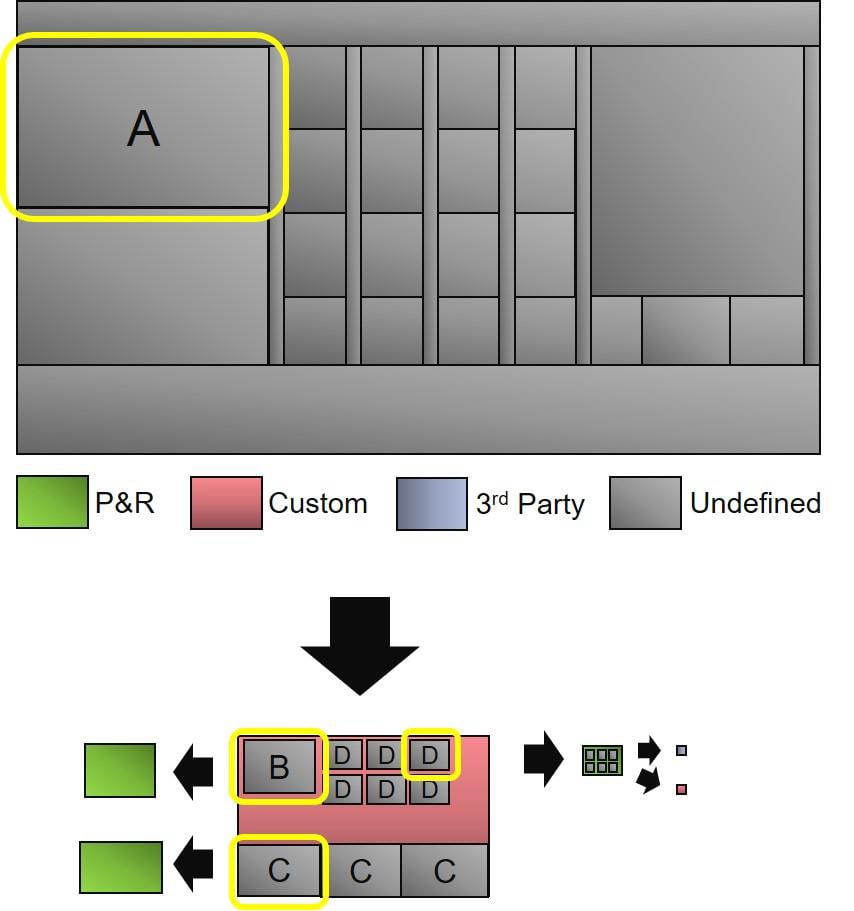
Xilinx formerly used an internal flow for IP integration, but now they prefer using a commercial EDA tool flow. Using the previous hierarchy diagram as a basis, consider how we want to trace the chip hierarchy in order to identify all IP layout data to build a merge list:
- Retrieve IC layouts for all top-level blocks
- Review each layout for undefined sub-blocks
- Recurse on undefined sub-blocks
This diagram shows how we start out at the top-level and identify Block A, recurse into it and find Blocks B, C and D. Recurse into Block D and find the lowest leaf cells.
Custom blocks are defined using OpenAccess, so the integration task is to stream out the GDS II from OA. Most 3rd party designs are stored on Unix as a GDS II file, so integration requires retrieving the Unix path. A P&R block could be saved either as Oasis or GDS II, so a custom script makes that decision.
In step 2 they use another utility to recurse and find any undefined sub-blocks. In the example both Bock B and C are defined as P&R blocks, while Block D is made up of 3rd party IP.
This methodology continues for all blocks on the Xilinx chip, identifying between 40 and 70 layout files, so finally it’s time to merge the data. The internal CAD tool flow required two steps, creating a very large intermediate GDS II file, then converting that GDS II into the final Oasis file to satisfy the foundry. Problems with the internal tool flow:
- Slow run times
- Disk intensive
- Cannot mark a layout as Golden
The new tool adopted at Xilinx for IP merge integration is called Skipper, and it’s from Empyrean. There were several reasons that Skipper was so attractive:
- Fastest speed for both GDS II and Oasis viewing
- Fast IP merging, 5-10X speedup
- One step method, instead of two
- Smaller disk space usage
- Integrated with 3rd party DRC/LVS tools, easy to debug
- Speedy LVL runtimes
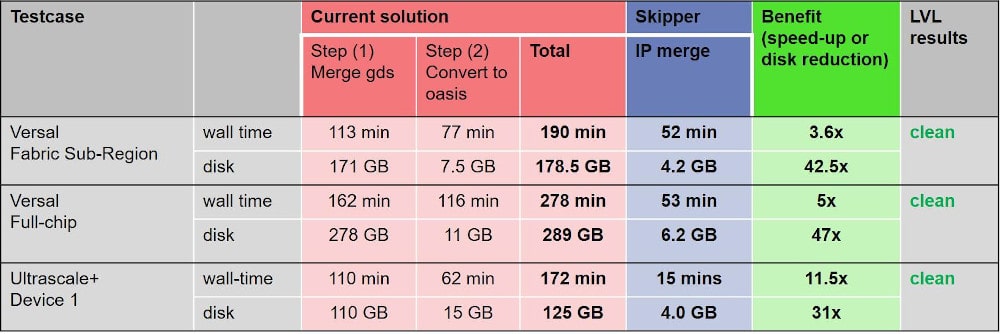
The proof of these improvements is shown in a comparison of both runtime and disk usage on three test cases:
Runtime speed improvements range from 3.6X to 11.5X, while disk usage is quite impressive at 31X to 42.5X smaller when using Skipper.
Summary
A 50 billion transistor programmable SoC from Xilinx is a dazzling achievement because of the sheer engineering challenges, and the CAD team has moved from an internal IP integration methodology to a commercial tool flow using Skipper from Empyrean. Both run time improvements and disk efficiency metrics were quite convincing to make the switch. Watch the entire 22 minute video on YouTube.
Related Blogs







{kind=link}
{kind=link}
{kind=link}
{kind=link}