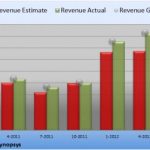
Synopsys just delivered second quarter 2012 results with improved revenue on a year-over-year basis. Unfortunately operating expenses are said to be out of control. I’m not a stock guy so for more financial information and analysis try the Motley Fool article HERE.
The interesting thing to note is that Synopsys still has a pile of cash, some $800M, so expect more acquisitions in all areas of the business especially IP, in my opinion. The IP business is a clear differentiator for Synopsys and they are running away with it.
You can tell a lot about a company from their DAC plan. Synopsys has gone AMS mobile this year:
Synopsys at DAC 2012
In addition to special events, Synopsys will offer informative presentations and demonstrations of its comprehensive portfolio of integrated system-level, implementation, verification, IP, manufacturing and FPGA solutions. Visit Synopsys at Booth #1130 to learn about the newest solutions available to help enable the next 25 years of innovation. For more information on these special events and all Synopsys’ activities at DAC visit www.synopsys.com/DAC.
Synopsys DAC Events, Monday, June 4, 2012:
- AMS Verification Luncheon: Boost Productivity Using Synopsys’ AMS Verification Solution
11:30 a.m. – 1:30 p.m., Marriott Hotel, Golden Gate Ballroom, Salon B
Industry leaders from AMD, ARM, GLOBALFOUNDRIES, Micron and NVIDIA share experiences using Synopsys’ AMS verification solutions in some of today’s most challenging designs.
- IC Compiler Luncheon: Leading the Way to 20nm Design with Synopsys’ IC Compiler™ Software
11:30 a.m. – 1:30 p.m., Marriott Hotel, Golden Gate Ballroom, Salon A
Hear from experts in foundry, processor, wireless and consumer electronics companies, such as STMicroelectronics, GLOBALFOUNDRIES and Samsung, that have successfully met the 20nm design enablement challenge with IC Compiler.
- Customer Insight Sessions: High-Performance, Gigahertz+ Success with Synopsys’ Galaxy™ Implementation Platform
2:00 p.m. with Samsung and 3:00 p.m. with NVIDIA, Moscone Convention Center East Mezzanine, Room 220
Technical experts will discuss the latest high-performance design trends, challenges and solutions. They’ll share best practices and innovations in high-performance technology that help address Gigascale, Gigahertz+, low power and advanced geometry design challenges.
- Synopsys’ PrimeTime® Software Special Interest Group 2012 Dinner: Next-generation Hierarchical Timing Technology — HyperScale
6:00 p.m. – 8:30 p.m., Marriott Hotel, Golden Gate Balzlroom, Salon A
At this event, you will see Synopsys’ R&D team unveil the new underlying engines for its hierarchical timing technology, HyperScale. Industry experts will also share their experience with this innovative new technology, which demonstrated up to 10X faster and smaller full-chip timing analysis runs with signoff quality results matching flat analysis. Speakers include timing experts from LSI, NVIDIA, Samsung and Synopsys. The event will be moderated by Brian Bailey of EE Times. PrimeTime Ecosystem Partners will also be there, including ARM, Chip Estimate, eSilicon, Global UniChip Corp., Library Technologies, Nangate, Open-Silicon, Platform Computing, an IBM company, Runtime Design Automation, Samsung, SmartPlay, SpringSoft, Target Compiler Technologies, Univa and Z Circuit.
Synopsys DAC Events, Tuesday, June 5, 2012:
- ARM, GLOBALFOUNDRIES, Samsung, Synopsys Partner Breakfast: Breaking through Barriers — High-Performance and Energy-Efficient ARM Powered SoCs at 32/28nm and 20nm
7:15 – 8:45 a.m., Marriott Hotel, Golden Gate Ballroom, Salon A
In this session, experts from ARM, GLOBALFOUNDRIES, Samsung and Synopsys will describe key design and manufacturing challenges facing designers at 32/28nm and 20nm and how through collaboration, the companies are addressing these challenges. The collaboration combines semiconductor manufacturing, EDA and IP enablement, shared cycles of learning and silicon proof-points to enable a complete silicon-proven design enablement and manufacturing-ready solution for optimized implementations of ARM Powered high-performance and energy-efficient SoCs.
- Customer Insight Sessions: High-Performance, Gigahertz+ Success with Synopsys’ Galaxy™ Implementation Platform
10:00 a.m. with Cavium and 2:00 p.m. with Samsung, Moscone Convention Center East Mezzanine, Room 220
Technical experts will discuss the latest high-performance design trends, challenges and solutions. They’ll share best practices and innovations in high-performance technology that help address Gigascale, Gigahertz+, low power and advanced geometry design challenges.
- Verification Luncheon: SoC Leaders Verify with Synopsys
11:45 a.m. – 1:45 p.m., Marriott Hotel, Golden Gate Ballroom, Salon A
Given the complexity of today’s SoC designs, incremental tool improvements will not be sufficient to deliver the required order-of-magnitude boost to verification productivity. At this luncheon, AMD, Broadcom, Cavium, Freescale, Qualcomm and ST-Ericsson will share their views on what’s driving SoC complexity and how their teams have achieved success. They’ll also discuss the latest developments in verification. The event will be moderated by John Chilton, senior vice president of marketing and strategic development at Synopsys.
- IPL Alliance Luncheon: Reaping the Benefits of iPDKs
12:00 p.m. – 1:30 p.m., Marriott Hotel, Golden Gate Ballroom, Salon B
At the 6th Annual IPL Luncheon, presenters from multiple foundries will highlight the benefits of the Interoperable PDK (iPDK) standard and their experiences in developing and deploying foundry iPDKs. The IPL Alliance will also present an update on current and future IPL projects.
- Customer Insight Session: Mixed-Signal SoC Design Success with the IC Compiler Custom Co-Design Solution
4:00 p.m. with STMicroelectronics and Proteus Biomedical, Moscone Convention Center East Mezzanine, Room 220
Attend an informative session on Synopsys’ mixed-signal SoC implementation solution and custom co-design methodology advancements. Learn how leading companies have successfully tackled difficult “big D/little A” mixed-signal physical design challenges using Synopsys’ unified cell-based and custom implementation solution with IC Compiler.