
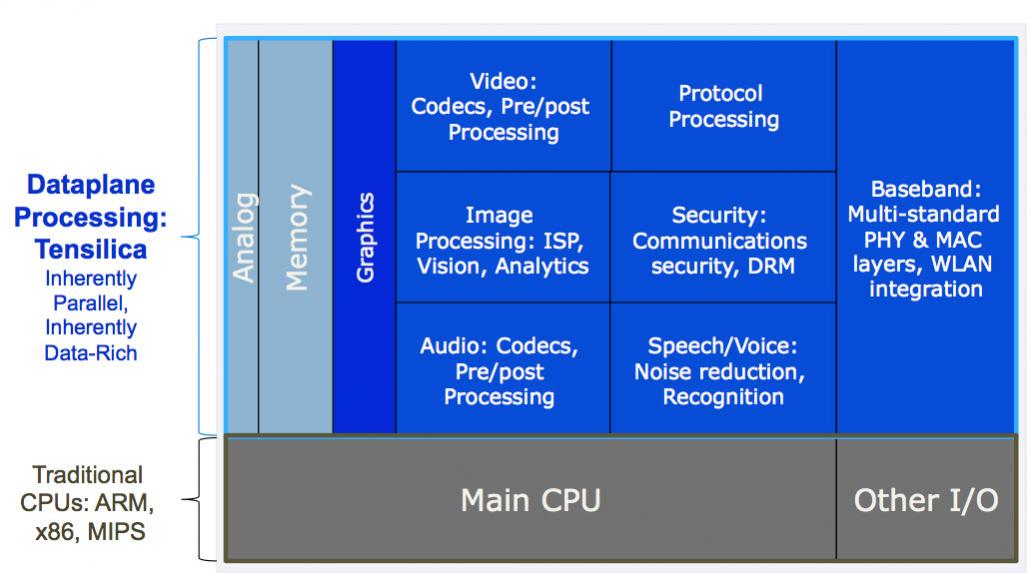
 At the Linley processor conference this week, Chris Rowen, the CTO of Tensilica presented on the protocol processing dataplane. That sounds superficially like he is talking about networking but in fact true protocol processing is just part of adding powerful compute features to the dataplane. Other applications are video, audio, security, voice-recognition and so on. All of these applications are inherently parallel and data-rich and either are impossible to process on a general purpose control processor such as an ARM (not enough performance) or are extremely power-hungry to use a general purpose processor.
At the Linley processor conference this week, Chris Rowen, the CTO of Tensilica presented on the protocol processing dataplane. That sounds superficially like he is talking about networking but in fact true protocol processing is just part of adding powerful compute features to the dataplane. Other applications are video, audio, security, voice-recognition and so on. All of these applications are inherently parallel and data-rich and either are impossible to process on a general purpose control processor such as an ARM (not enough performance) or are extremely power-hungry to use a general purpose processor.
Depending on the application, different kinds of parallelism are required, from single-instruction multiple-data (SIMD) vector processing to homogenous threads (all doing the same thing) or heterogenous threads.
The Tensilica Xtensa dataplane processor units (DPUs) are highly customizable and thus suitable for all these applications. The processors generated range from 11.5K gates up to huge beasts with large numbers of execution units. In addition, they can have a huge range of I/O architectures with FIFOs, lookup tables, or very wide direct connections. After all, a high-performance DPU isn’t much use if you can’t get the data in and out to the rest of the design with high enough bandwidth.
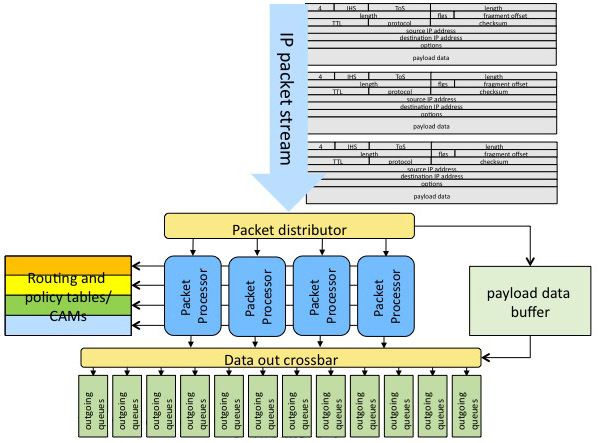
Probably the most demanding application, requiring very high I/O performance and high performance in the compute fabric, is network data forwarding (such as in a high-performance router). The most generic way to do this would be to use a cache-coherent memory system and just put the packets in off-chip DRAM. But Chris has a rule-of-thumb that, since energy is proportional to distance, if a direct wire connect is 1 unit of energy, local memory is 4, on-chip NoC is 16 and going off-chip is 256.
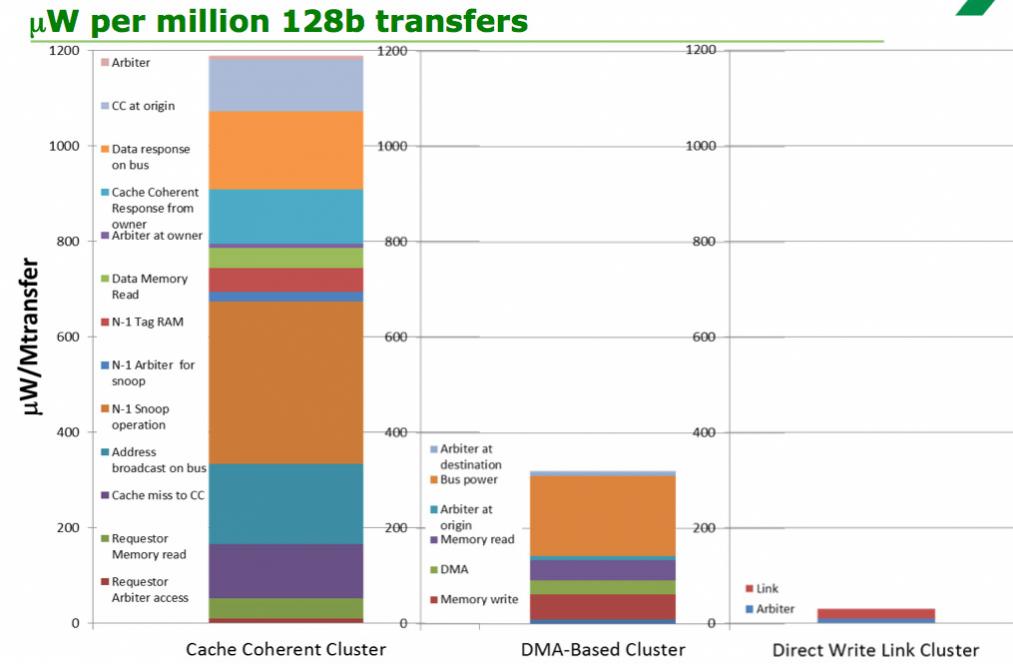
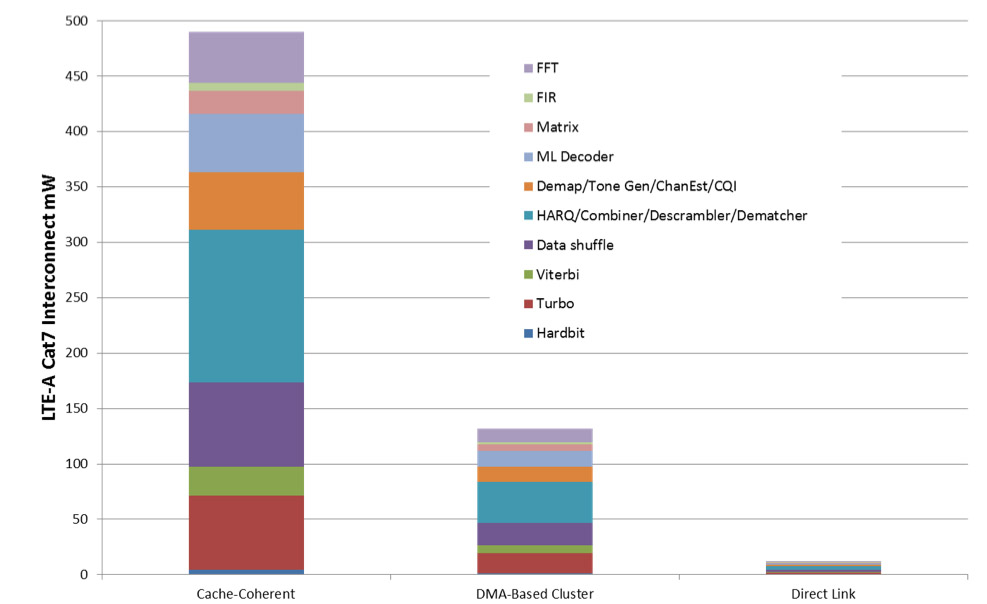
There is thus an enormous difference in energy efficiency to build the best possible fabric on-chip to keep everything fed, rather than building something completely general purpose, as can be seen from the above diagram showing the difference between using a cache-coherent cluster, one where DMA is used to offload the processors and one with direct connect.
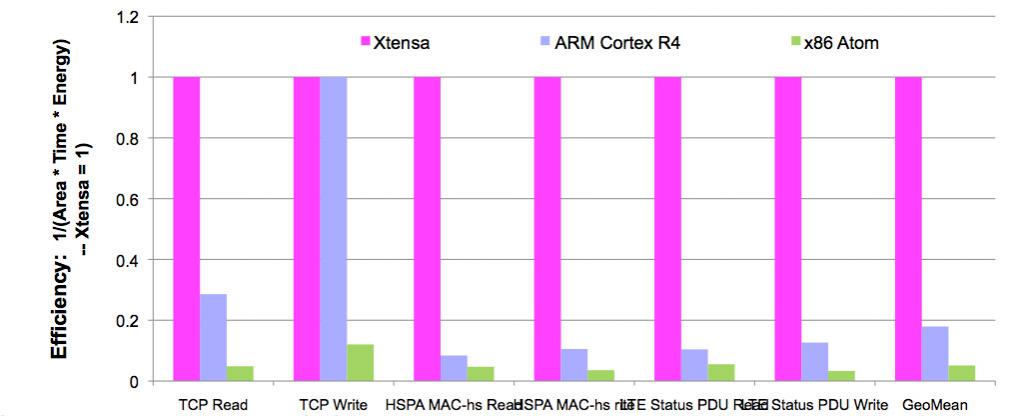
The savings are huge using a DPU versus a standard microrprocessor. The pink bars show the efficiency of the Tensilica Xtensa DPU, the blue are ARM and the green is Intel Atom. Higher numbers are good (this is efficiency, Xtensa has been scaled to 1).
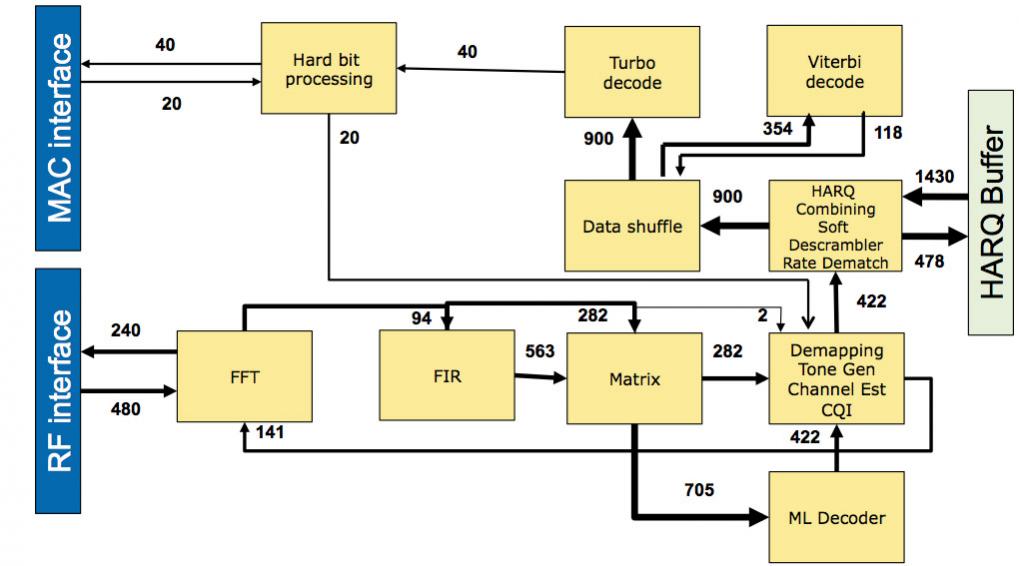
To take another demanding example, LTE-Advanced level 7. The block diagram is complex and requires a huge amount, 6.5Gb/s, to be moved around between the blocks. Again, comparing the general purpose solution to building direct connections on-chip shows the enormous difference in efficiency.





TSMC CoWoS versus Intel EMIB Semiconductor Packaging