You are currently viewing SemiWiki as a guest which gives you limited access to the site. To view blog comments and experience other SemiWiki features you must be a registered member. Registration is fast, simple, and absolutely free so please,
join our community today!
Arteris IP and Magillem recently tied the knot, creating a merger of Network-on-Chip (NoC) and related Intellectual Property (IP) with a platform known for IP-XACT based SoC integration and related support. This is interesting to me because I’m familiar with products and people in both companies. I talked to Kurt Shuler, vice… Read More
I attended one of the Arm partner events in Cambridge many years ago, when they first talked about the coherent hub for managing cache coherence. I was impressed, but the obvious question even then was how any non-Arm IP was going to hook into this hub. They had a solution, of course, the ACE interface, and I left satisfied. As is the … Read More
Charlie Janac is president and CEO of Arteris IP where he is responsible for growing and establishing a strong global presence for the company that is pioneering the concept of NoC technology. Charlie’s career spans over 20 years and multiple industries including electronic design automation, semiconductor capital equipment,… Read More
There’s a lot of debate about how and when we are going to emerge from the worldwide economic downturn triggered by the pandemic. Everyone agrees we will emerge. This isn’t humanity’s first pandemic, nor will it be our last. But do we come out quickly or slowly? And what does the economy look like on the other side, particularly for … Read More
I’ve talked before about how Defacto provides a platform for scripted RTL assembly. Kind of a rethink of the IP-XACT concept but without need to get into XML (it works directly with SV), and with a more relaxed approach in which you decide what you want to automate and how you want to script it.
They’re hosting a webinar on May 28th 10-11am… Read More
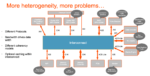
The nexus of complexity in SoC design these days has to be in automotive ADAS devices. Arteris IP highlighted this in the Linley Processor Conference recently where they talked about an ADAS chip that Toshiba had built. This has multiple vision and AI accelerators, both DSP and DNN-based. It is clearly aiming for ISO 26262 ASIL D … Read More
Block floating point (BFP) has been around for a while but is just now starting to be seen as a very useful technique for performing machine learning operations. It’s worth pointing out up front that bfloat is not the same thing. BFP combines the efficiency of fixed point operations and also offers the dynamic range of full floating… Read More
FPGAs have always been a great way to add performance to a system. They are capable of parallel processing and have the added bonus of reprogramability. Achronix has helped boost their utility by offering on-chip embedded FPGA fabric for integration into SoCs. This has had the effect of boosting data rates through these systems… Read More
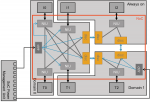
Caching intent largely hasn’t changed since we started using the concept – to reduce average latency in memory accesses and to reduce average power consumption in off-chip reads and writes. The architecture started out simple enough, a small memory close to a processor, holding most-recently accessed instructions and data … Read More
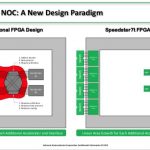
Why does it seem like current FPGA devices work very much like the original telephone systems with exchanges where workers connected calls using cords and plugs? Achronix thinks it is now time to jettison Switch Blocks and adopt a new approach. Their motivation is to improve the suitability of FPGAs to machine learning applications,… Read More