During TSMC 2018 Technology Symposium, Dr. B.J. Woo, TSMC VP of Business Development presented market trends in the area of mobile applications and HPC computing as well as shared TSMC progress in making breakthrough efforts in the technology offerings to serve these two market segments.
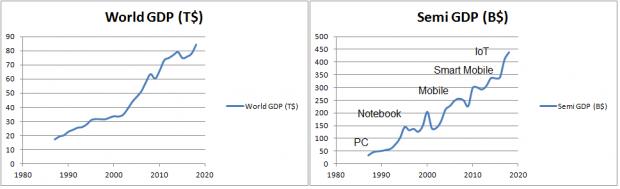
Both 5G and AI are taking the center stage in shaping the high double-digit data growth demand. For mobile segment, the move from 4G LTE to 5G requires the use of higher modem speed (from 1Gbps to 10Gbps), 50% faster CPU, twice faster GPU, double transistor density, 3X performance increase of AI engines to 3 TOPS (Trillion Operations Per Seconds) target and without much power increase. In this market segment, TSMC is ushering the move from 28HPC+ towards 16FFC.
On the cloud side, data center switch demands double throughput, from 12.8Tbps to 25.6Tbps as the computing demand move towards the network edge. Similarly the drive towards double memory bandwidth, 3 to 4x increase in throughput of AI accelerators and up to 4x transistor density improvement are taking place.
N7 Technology Progress
Dr. Woo stated that delivering high density and power efficiency requirements to satisfy low latency of data intensive AI application is key to the success of TSMC N10 process. It has also enabled AI in the smartphones space. On the sideline, N7 node has been making good progress in providing excellent PPA values with >3x density improvement, >35% speed gain and >65% power reduction over its 16nm predecessor.
N7 HPC track provides 13% speed over N7 mobile (7.5T vs 6T), while it has passed the yield and qual tests (SRAM, FEOL, MEOL, BEOL) and MP-ready D0. Part of the contributing factor is TSMC successful leveraged learning from N10 D0 and it is targeted for Fab15.
The N7 IP ecosystem is also in ready state with over 50 tapeouts slated by end of 2018 for mobile, HPC, automotive and servers. The 7nm technology is anticipated to be having a long life similar to its predecessor 28nm/16nm nodes. The combination of mild pitch scaling from N10 to N7 plus the migration from immersion to EUV scaling and denser standard cell architecture make significant overall improvement.
EUV Adoption and N7+ Process Node
She shared some progress of the EUV application on N7+. Applicable on selected layers, EUV reduces the process complexity and enhances resulting pattern fidelity. It also enables future technology scaling while offering better performance, yield and shorter cycle time. Dr. Woo showed caption of via resistance having much tighter distribution in N7+ EUV versus N7+ immersion as it delivers better uniformity.
The N7+ value proposition includes delivering 20% more logic density over N7, 10% lower power at same speed, and additional performance improvements anticipated from the ongoing collaboration with customers.
N7+ will also have double digit good die increase over N7 node as it gains traction from capitalizing the use of the same equipment and tooling. She claimed that it has lower defect density than other foundries as well as comparable 256Mb SRAM yield and device performance vs N7 baseline. TSMC provides easy IP porting (layout and re-K) from N7 to N7+ for those design entities that do not need to be redesigned.
HPC and N7+ Process Node
For HPC platform solution, the move from N7 to N7+ involves the incorporation of EUV, denser standard cell architecture, ultra-low Vt transistors, high-performance cells, SHDMIM (Super High Density MIM) capacitance and larger CPP (Contacted Poly Pitch) and 1-fin cells.
N7+ offers better performance and power usage through the use of an innovative standard cell architecture. It allows higher fin density in the same footprint for 3% speedup. On the other hand, reducing power by applying single-fin in non-timing-critical area reduces about 20% capacitance and in-turns, the dynamic power number.
The adoption of new structures also enhances MIM capacitance and utilization rate for HPC 3% to 5% performance boost. N7+ design kit is ready for supporting the IP ecosystem.
N5 Value Proposition
It has new elVt (extreme low Vt) offering a 25% max speed-up versus N7, incorporating aggressive scaling and full-fledged EUV. N5 has made good progress with double digit yield on 256Mb SRAM. Risk production is slated to be 1H2019.
Dr. Woo also shared a few metrics compared with N7 process (test vehicles used ARM A72 CPU core + internal ring oscillator):
– 15% speed improvement (up to 25% max speed)
– 30% power reduction
– 1.8x increased logic density through innovative layout and routing
– 1.3x analog density improvement through poly pitch shrink and selective Lg and fin #, yielding a more structured layout (“brick-like” patterns)
16FFC/12FFC Technologies
Dr. Woo covered RF technologies and roadmap (more on this in subsequent blog on IoT and Automotive). She mentioned that N16 and N12 FinFet based platform technologies have broad coverage, addressing HPC, mobile, consumer and automotive. Both 16FFC and 12FFC have shown strong adoption data with over 220 tapeouts. 12FFC should deliver 10% speed gain, 20% power reduction and 20% increased logic density vs 16FFC through dual-pitch BEOL, device boost, 6-track stdcell library and 0.5v VCCmin.
To recap, AI and 5G are key drivers for both mobile and HPC product evolutions. Along this line, TSMC keeps pushing the PPA (Power, Performance and Area) envelopes for the mainstream products while delivering leading RF technologies to keep pace with technology accelerated designs in these segments.
Also read: Top 10 Highlights of the TSMC 2018 Technology Symposium