If a CPU or CPU cluster in an SoC is the brain of an SoC, then the interconnect is the rest of the central nervous system, connecting all the other processing and IO functions to that brain. This interconnect must enable these functions to communicate with the brain, with multiple types of memory, and with each other as quickly and predictably as each function requires. But it must also be efficient and ensure error-free operation.
Pulling off this trick has led to plethora of bus protocol standards, most widely represented by the AMBA family, now complemented by CCIX, which I’ll get to later. There’s a nice summary of the various AMBA protocols here, ranging from APB and ASB, through multiple flavors of AHB and multiple flavors of AXI, all the way up to ACE (also in a couple of flavors) and finally CHI. Why so many? Because you simply can’t serve in one protocol the needs for functions running at tens of MHz to functions running at GHz, and quality of service (QoS) ranging from best-effort (e.g. web response) to guaranteed (e.g. phone-call).
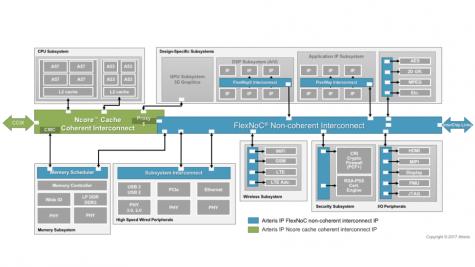
Network-on-chip (NoC) architectures, like the FlexNoC solution from Arteris, have become pervasive in mixed-protocol SoC designs because of the flexibility, performance, QoS and layout- and power-efficient advantages they offer in in contrast to more traditional switch-matrix solutions. You don’t need to construct tiered hierarchies of interconnect to bridge between different protocols; the NoC architectures seamlessly manages bridging and communication and can be tuned to deliver the PPA and QoS you need.
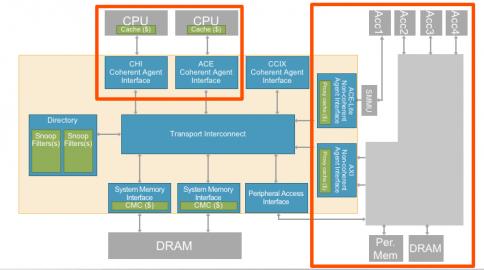
These days, there’s another wrinkle: Cache-coherent protocols have become popular thanks to the appearance of CPU clusters and other devices which need to communicate with those systems. When cores read and write memory, they do so first to their caches as a fast short-cut to reading and writing main memory. But if a core updates memory address X in its private cache just before a function F reads X, from its private cache or directly from main memory, then F is going to read the wrong value. Cache-coherency protocols manage these potential mismatches through a variety of techniques to ensure that memory views stay in sync when needed. The ACE and CHI protocols were introduced to cover this need; ACE first then CHI later to handle the more complex configurations appearing in more recent SoCs.
Now of course many design enterprises have a mix of IPs with either ACE interfaces or CHI interfaces. Arteris introduced their Ncore version 3 cache coherent interconnect at the October 2017 Linley conference to manage both ACE and CHI protocols in one interconnect, so you can manage a complete cache-coherent domain with just one interconnect solution. This is technology is very configurable, not just in the expected parameters but also in topology. Ncore 3 supports tree, ring and mesh topologies and even a 3D options, all allowing for different ways to manage bandwidth, latency and fault-tolerance.
Typically, your whole design won’t require cache-coherence; much of what you repurpose from legacy subsystems (or even many new subsystems) won’t depend on this capability. You can connect all of those non-coherent subsystems and hardware accelerators using the standard FlexNoC solution, but again with a wrinkle: A hardware accelerator/sub-subsystem in this non-coherent domain can share address space with the coherent domain, allowing memory references from that accelerator/subsystem to be coherent. You accomplish this by connecting these non-coherent subsytems to the Ncore 3 fabric through interfaces containing proxy caches, which loops them into the coherence management logic. You can even connect multiple non-coherent accelerators to a single proxy cache, thereby creating a cluster that can interact with the rest of the system as a coherent peer to the cache-coherent CPU clusters..
Kurt Shuler (VP Marketing at Arteris) told me that this need to integrate non-coherent subsystems and accelerators with the coherent domain is becoming increasingly important in machine-learning use-cases. As the number of hardware accelerators required to process neural net and image processing algorithms increases, it become harder to manage data communications without using cache coherence for critical parts of the system. Incidentally, it’s also possible to connect, cache coherently, to other die/devices though the CCIX interface (in a 2.5D/3D assembly solution for example). Ncore 3 supports this kind of connection with a CCIX interface connecting coherent domains between multiple chips.
There is one more important set of capabilities in Ncore 3 that are highly relevant to automotive or other safety-critical applications. This solution provides (within the fabric) ECC generators and checkers for end-to-end data protection, intelligent unit duplication and checking, similar to dual-core lockstep (DCLS), and a fault controller with BIST that is automatically configured and connected based on the designer’s data protection and hardware duplication settings. The capabilities can be combined to provide sufficient diagnostic coverage to meet automotive ISO 26262 functional safety certification requirements, as well as the more general IEC 61508 specification.
There’s a lot of technology here which should be immediately interesting to anyone building heterogeneous coherent/non-coherent SoCs and anyone wanting to build added safety into those systems. You can learn more HERE.
Share this post via:



Comments
5 Replies to “Connecting Coherence”
You must register or log in to view/post comments.